vLLM 大规模服务:DeepSeek @ 2.2k tok/s/H200,采用 Wide-EP
引言
在 v0.11.0 中,vLLM V0 引擎的最后一行代码被移除,标志着其已完全迁移到改进的 V1 引擎架构。若没有 vLLM 社区的 1,969 名贡献者在过去一个月(截至 2025年12月18日)提交的 950 余次代码,这一成就将不可能实现。
这些努力已通过 vLLM 被纳入 SemiAnalysis 开源 InferenceMax 性能基准测试而得到验证。此外,vLLM 很自豪能获得 Meta、LinkedIn、Red Hat、Mistral 和 HuggingFace 团队的生产环境信任。
DeepSeek 风格的分解式服务和稀疏混合专家 (MoE) 模型部署在高性能 LLM 推理方面仍然处于领先地位。本文概述了 vLLM 团队为进一步提高吞吐量而构建的关键优化,包括
- 异步调度
- 双批次重叠
- 分解式服务
- CUDA 图模式
FULL_AND_PIECEWISE - 默认启用 DeepGEMM
- DeepEP 内核集成
- 专家并行负载均衡
- DeepSeek-R1 的 SiLU 内核
如需进一步参考,我们推荐 llm-d、PyTorch、Dynamo 和 Anyscale 团队关于大规模服务、分解式服务、分布式推理以及使用 vLLM 的宽专家并行 (Wide-EP) 的优秀文章。
结果
最近在通过 Infiniband 和 ConnectX-7 NIC 连接的 Coreweave H200 集群上进行的社区基准测试显示,在类生产环境的多节点部署中,每颗 H200 GPU 可持续达到 2.2k tokens/s 的吞吐量。
这比早期基准测试中每颗 GPU 约 1.5k tokens/s 的数据有了显著提升。这一增益是持续优化工作(包括内核改进,如 silu-mul-quant 融合、Cutlass QKV 内核、TP attention 错误修复)以及为解码实现的双批次重叠 (DBO) 的直接结果。
这种性能使得运营商能够通过整合工作负载并减少实现目标 QPS 所需的副本数量,从而降低每代币成本,实现即时收益。
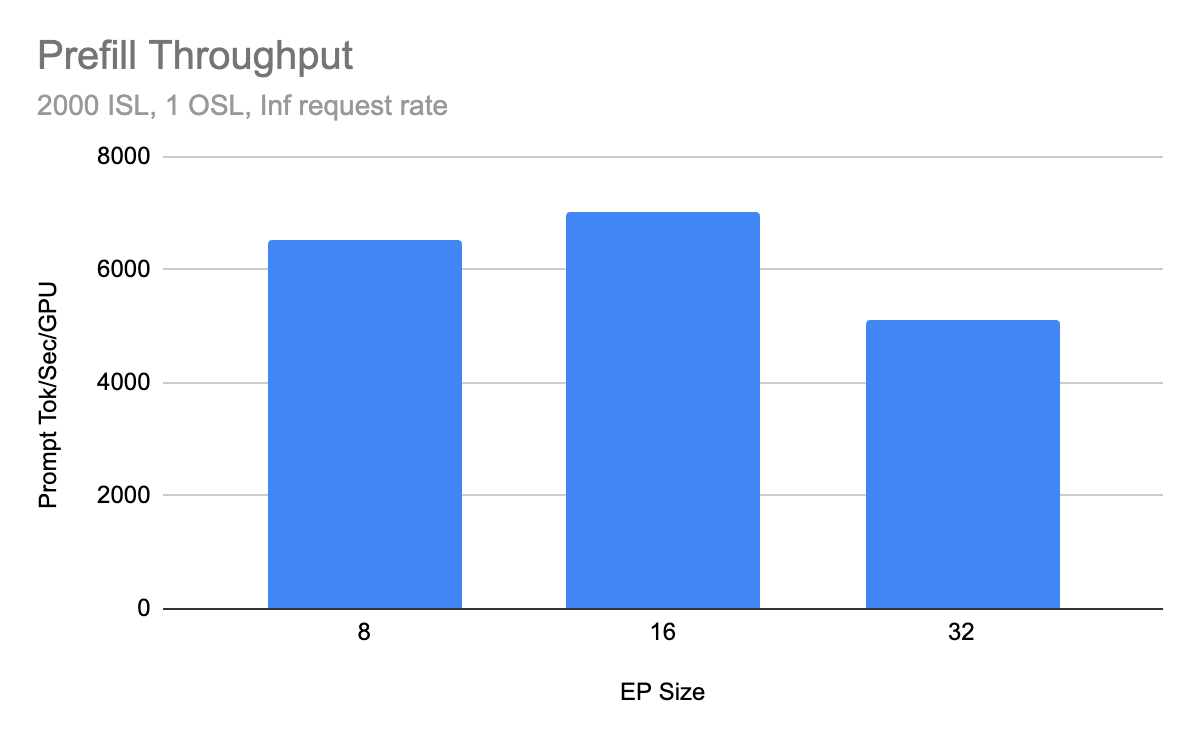
预填充结果
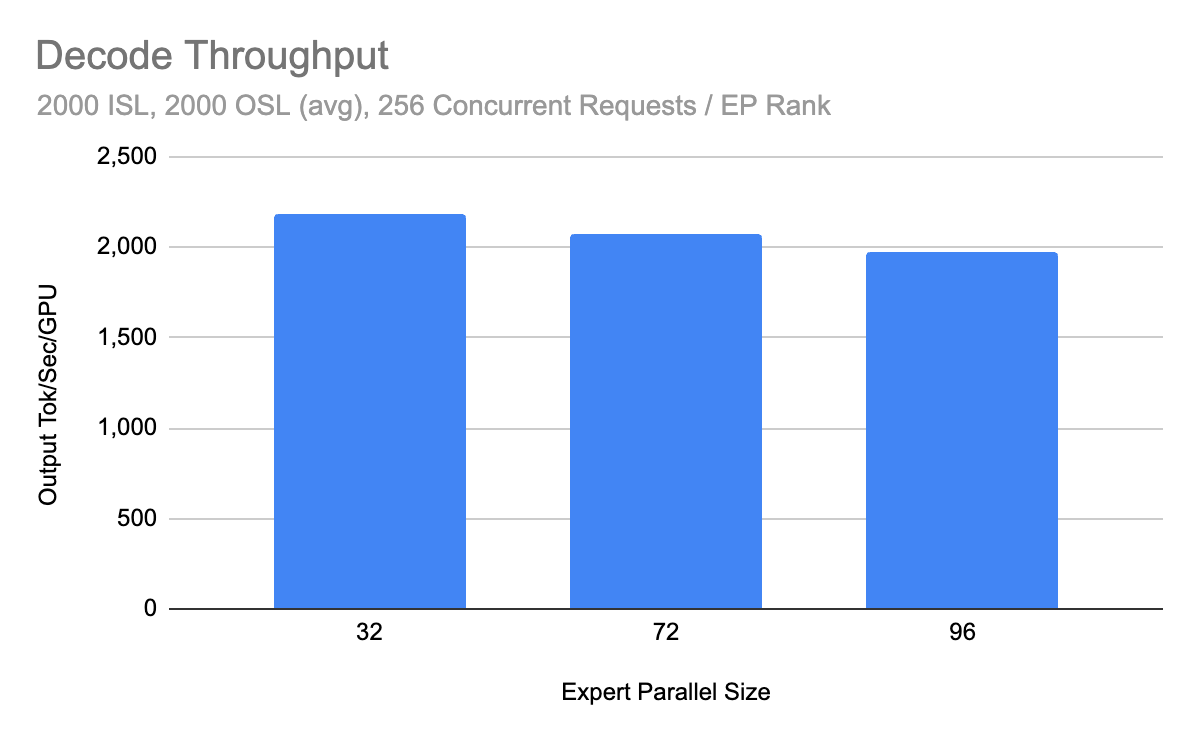
解码结果
关键组件
Wide-EP
为大规模服务部署 DeepSeek-V3 模型系列等前沿模型需要两个主要考虑因素
- 稀疏专家激活:在 DeepSeek-R1 中,模型总参数 671B 中只有 37B 在每次前向传递中处于激活状态
- KV 缓存管理:张量并行部署对于 DeepSeek 的多头潜在注意力 (MLA) 架构来说并非最优,因为潜在投影会在分片之间重复
专家并行 (EP) 是一种利用这些特性最大化有效 KV 缓存的部署模式,并通过 vLLM 中的 --enable-expert-parallel 标志支持。在此模式下,一组专家在部署中的不同等级之间共享。在前向传递期间,令牌在等级之间路由,由适当的专家处理。

Wide-EP 令牌路由
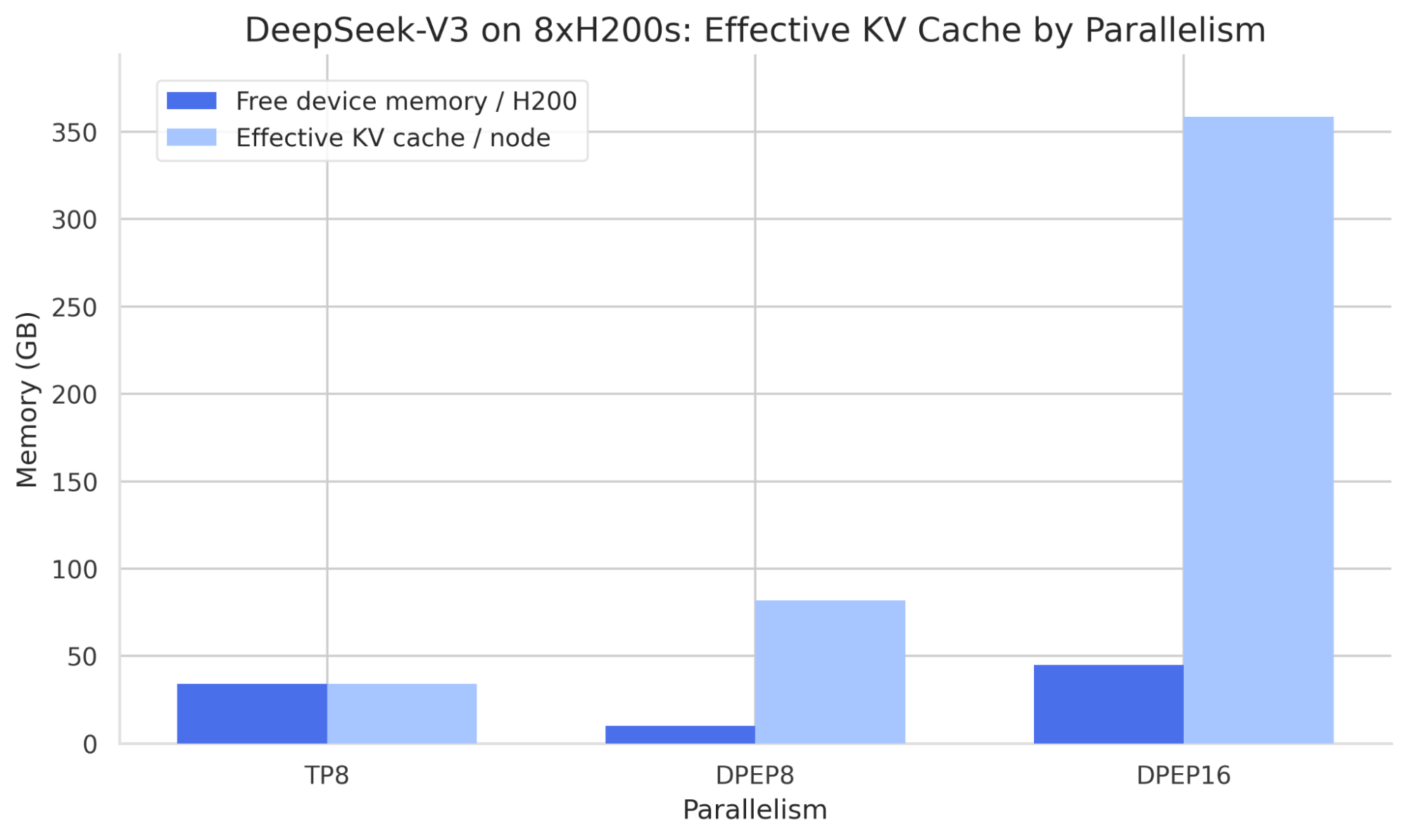
Wide-EP 将 EP 与数据并行 (DP) 结合。数据并行部署可以使用 mp 或 ray 数据并行后端启动,在 Ray 集群中提供更简单的设置。与张量并行相比的优势如下图所示,该图显示了 DeepSeek-V3 使用张量并行和专家并行分片策略时每颗 GPU 的内存使用情况。
TP 策略显示每颗 H200 有 34GB 的空闲设备内存,但对于 MLA 模型,每个等级必须复制潜在注意力投影。在 DP 部署中,注意力层是复制的,以便潜在投影在不同等级之间是独立的,从而增加整个部署的有效批次大小。
增加专家并行度会增加等级之间的同步开销。为了解决这个问题,vLLM 集成了对 DeepEP 高吞吐量和低延迟 all-to-all 内核的支持。此外,vLLM 还支持 Perplexity MoE 内核以及基于 NCCL 的 AllGather-ReduceScatter all-to-all。有关 vLLM 中可用的 all-to-all 后端的信息,请参阅 vLLM MoE 内核文档。
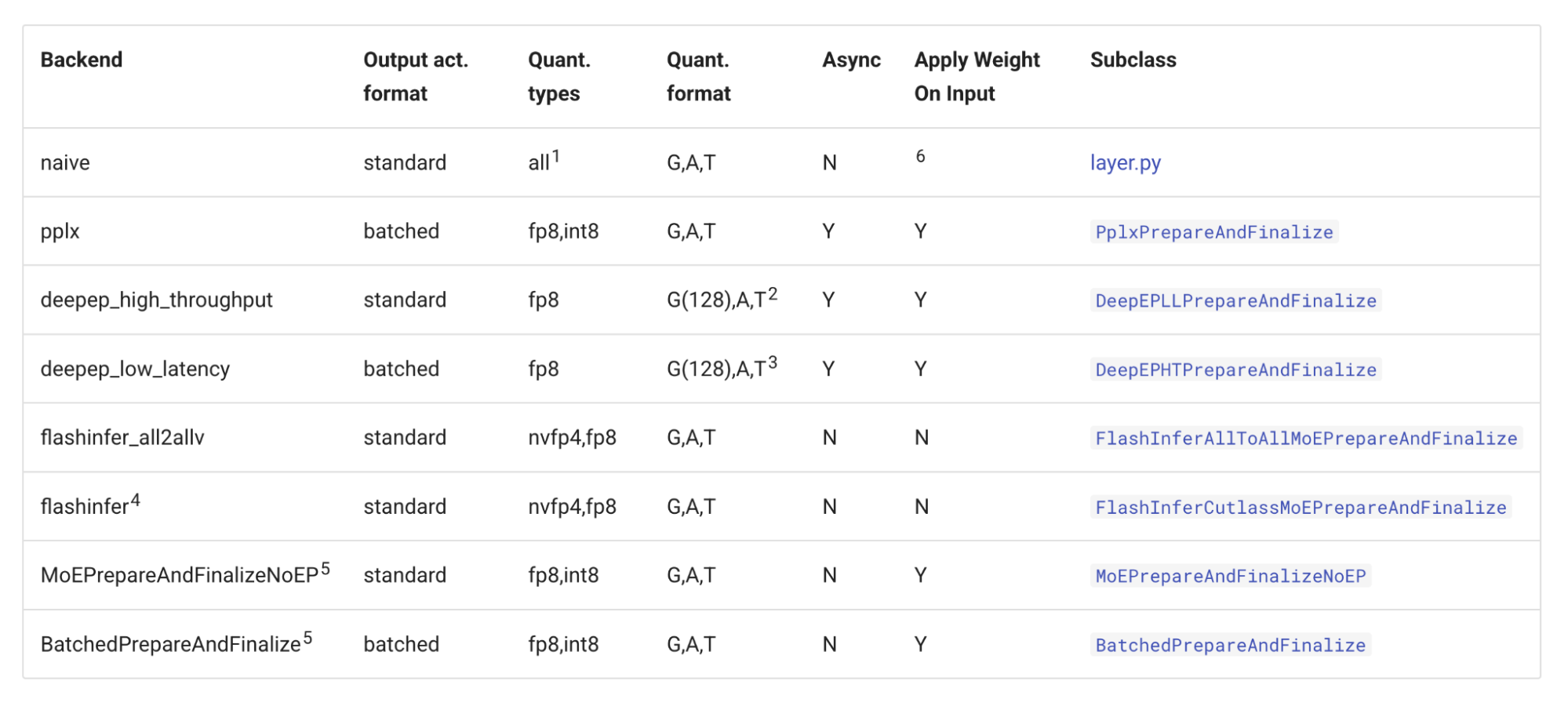
vLLM all-to-all 后端
双批次重叠 (DBO)
vLLM 集成了对 DeepSeek 微批处理策略的双批次重叠 (DBO) 支持,可通过命令行 --enable-dbo 标志使用。该策略将计算和集体通信重叠,以提高 GPU 利用率。具体而言,vLLM 的实现方式如下:
- 跨等级进行集体
all_reduce以确认微批处理将是有益的,最小阈值可通过--dbo-decode-token-threshold进行调整。 - 主线程创建微批次工作线程,完成 CUDA 图捕获。
- vLLM 的模块化 MoE all-to-all 内核基类协调微批次工作线程的启动,在等待 GPU 工作完成时让出控制权。
下面是 DeepSeek 解码工作负载 未启用 DBO 的分析跟踪。“MoE Dispatch/Combine”部分显示了集体通信所花费的过长时间,尽管计算负载很小。
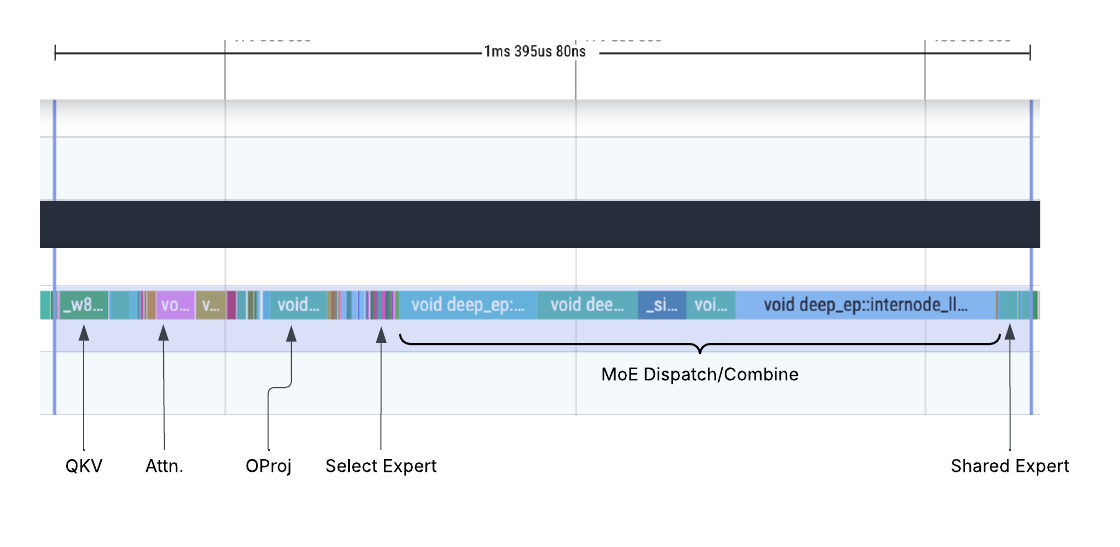
DBO 之前
以下跟踪显示了 启用 DBO 的相同工作负载。第一个微批次工作线程启动并完成 MoE 分派,然后立即让给第二个微批次工作线程。接下来,第二个线程完成其分派,并在完成后让回第一个线程。最后,第一个工作线程在让回第二个微批次工作线程之前完成其组合。
这会在通信开销高的部署中(例如专家并行度高的部署)提高 GPU 利用率。
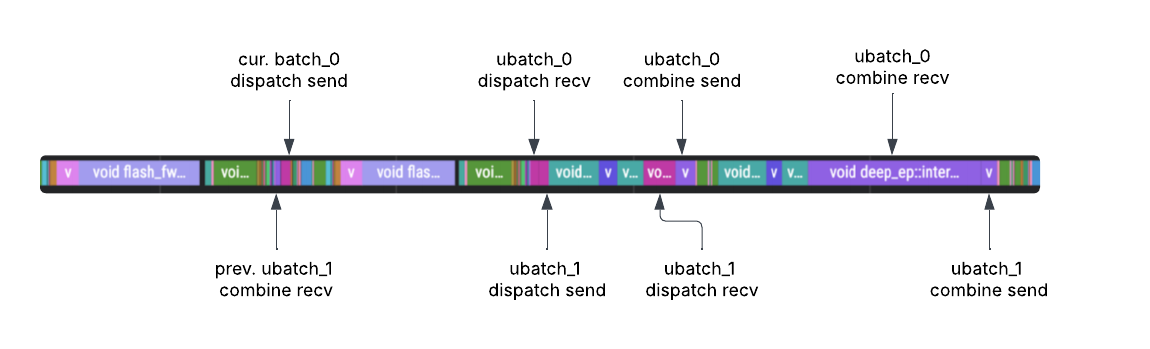
DBO 之后
专家并行负载均衡 (EPLB)
MoE 专家层在训练时针对专家之间的负载均衡进行了优化,但在推理时,实际工作负载可能会导致令牌路由不平衡。请参阅 NVIDIA 关于 MoE 专家路由的实验结果,了解不同工作负载之间专家负载均衡的统计数据。
在 wide-EP 设置中,这意味着某些 EP 秩可能会处于空闲状态,而其他秩则处理大量令牌。为了缓解这个问题,vLLM 实现了 DeepSeek 专家并行负载均衡器 (EPLB) 的分层和全局负载均衡策略。EPLB 由 --enable-eplb CLI 标志控制,具有可配置的窗口大小、再均衡间隔、冗余专家和日志记录选项。

EPLB 运行中
为了实现 EPLB,每次 MoE 前向传播都会记录每个令牌的负载,并且滑动窗口会在 EP 秩之间聚合这些统计数据。当达到再均衡间隔时,负载均衡器会计算新的逻辑到物理专家映射,并协调权重混洗,以便新的放置生效而无需重新启动模型。
分解式服务
由浩瀚人工智能实验室在 2024 年 DistServe 论文中描述的分解式预填充/解码服务模式,对于专家并行部署尤其有用。

P/D 分解运行中
由于专家分布在不同的等级上,一个请求的令牌在一个等级上开始处理,可能需要由 EP 组中任何其他等级上的专家进行处理。这需要在 MoE 层之间进行同步(如果某个等级未使用,则进行虚拟传递),以便层组合集体在适当的时候准备好接收令牌。
这意味着一个计算密集型预填充请求可能会延迟整个 EP 组的前向传播,从而放大分解式服务的优势。此外,DeepSeek 部署可以配置为专门使用适合其工作负载的 DeepEP 内核(高吞吐量或低延迟)。
部署路径
llm-d
llm-d 是一个 Kubernetes 原生分布式推理服务堆栈,为任何人提供清晰的路径,以大规模服务大型生成式人工智能模型。llm-d 帮助您在大多数硬件加速器和基础设施提供商上,针对关键 OSS 模型实现最快的“达到最先进 (SOTA) 性能的时间”。欲了解更多详细信息,请查看 llm-d 的 Wide EP 最佳实践,以复现本文中的结果。
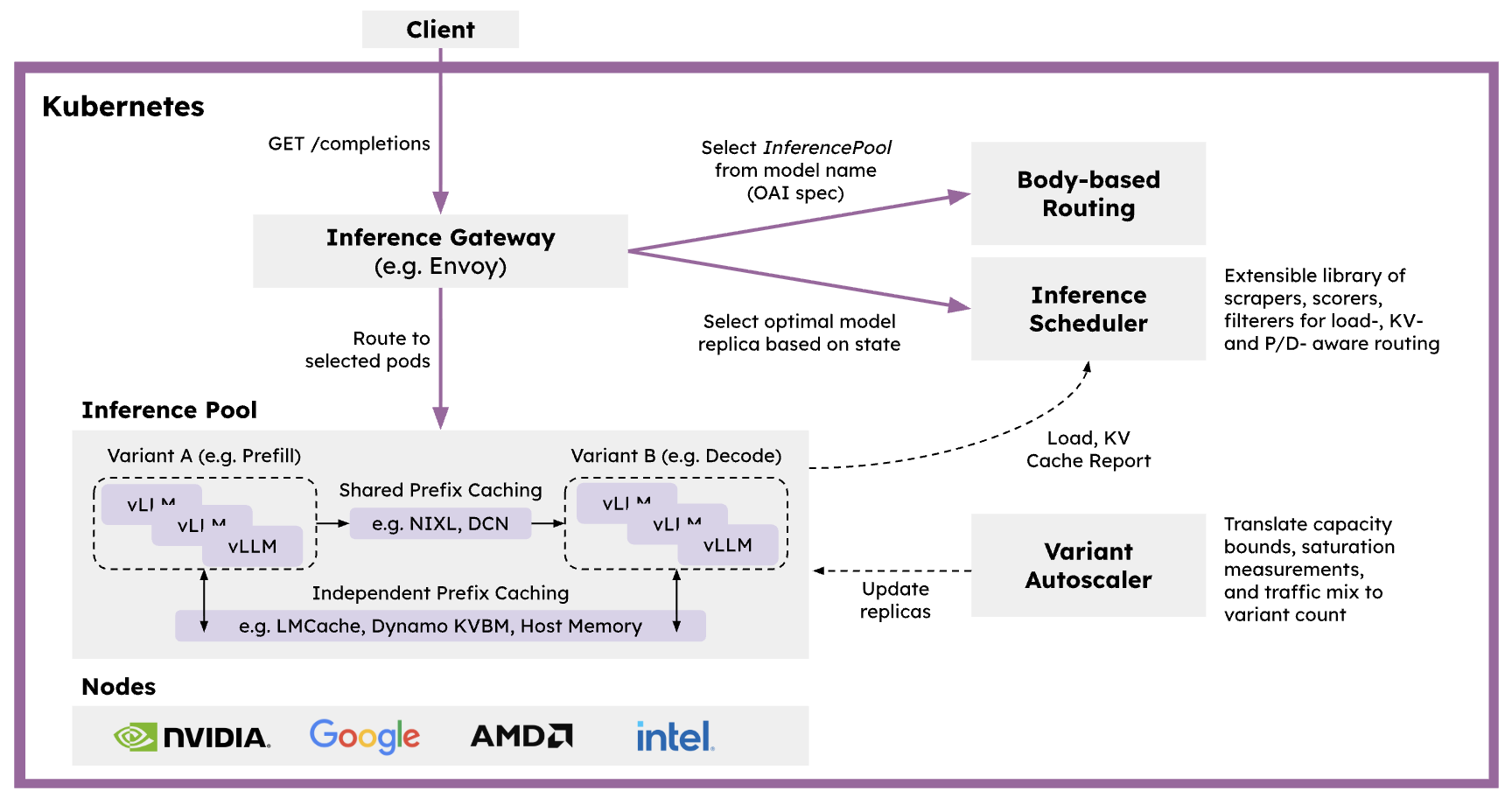
Dynamo
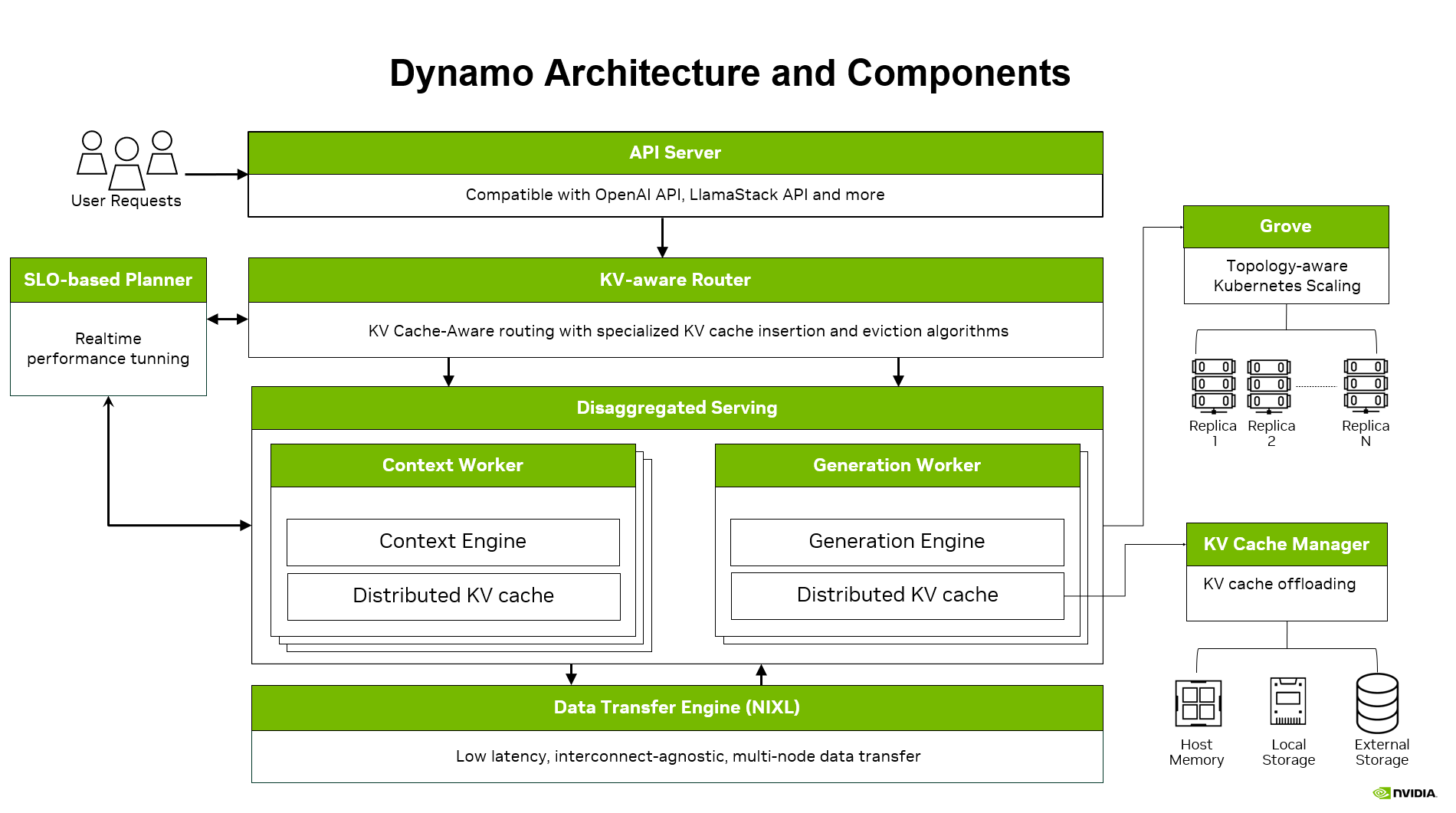
Dynamo 专为 LLM 的高吞吐量和低延迟生产部署而设计。诸如 KV 感知路由、用于缓存卸载的 KV 块管理器以及用于动态负载匹配的规划器等功能使您能够在扩展到更多 GPU 的同时实现更严格的 SLA。vLLM 和 wide-EP 服务在 Dynamo 中原生支持所有这些功能。有关更多详细信息,请查看 Dynamo 和 示例配方以复制此博客文章中的性能。
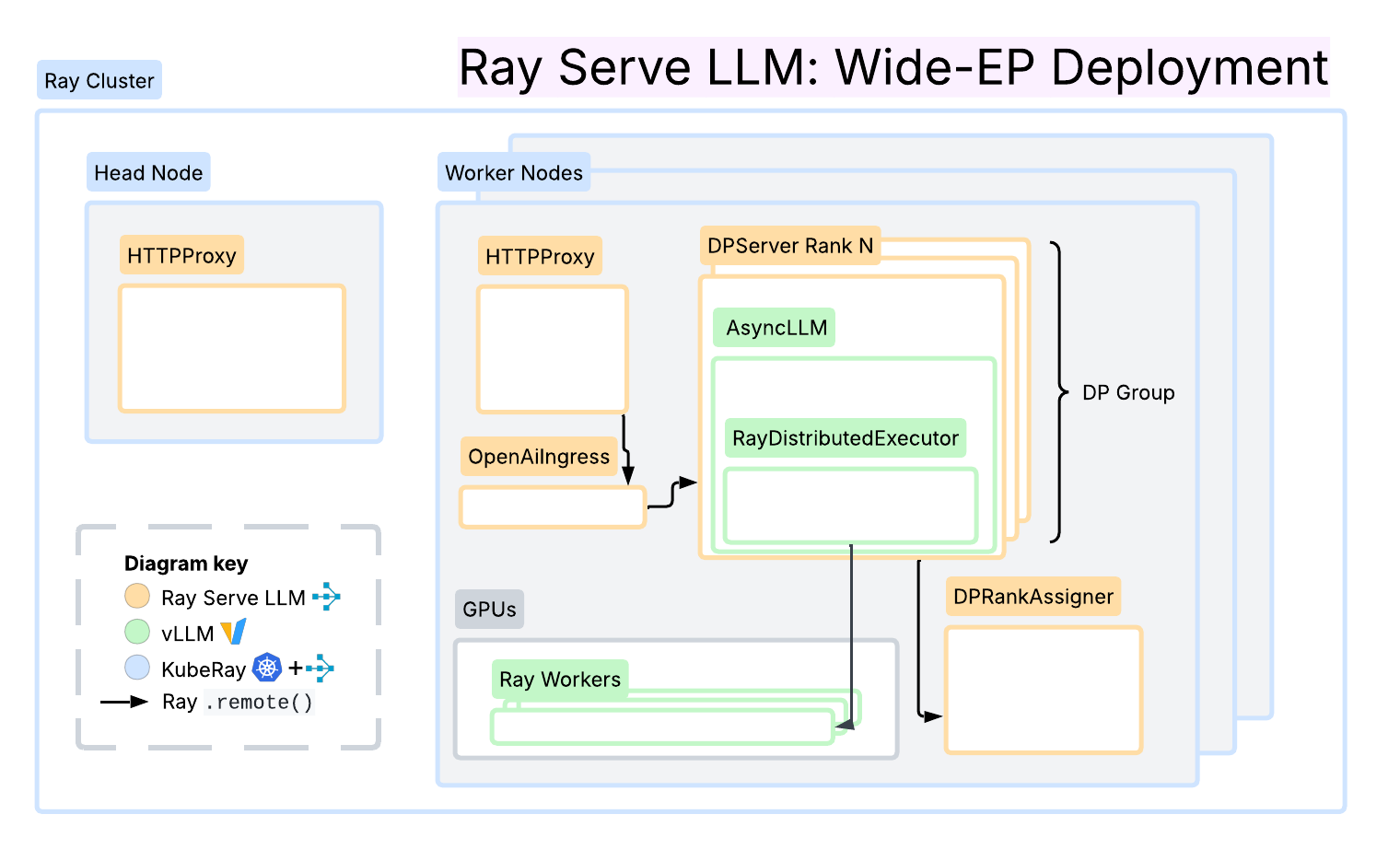
Ray Serve LLM
Ray Serve LLM 基于 Ray Serve 原语构建,为预填充/解码分解、数据并行注意力和前缀缓存亲和性请求路由提供了一流的服务模式,专注于在 Ray 集群(包括 Kubernetes 上的 KubeRay)中部署的模块化和便捷性。一个关键的区别在于它与更广泛的 Ray 生态系统(包括数据处理和强化学习 (RL))的无缝集成。
该框架集成了 NIXL 和 LMCache 连接器以实现高效的 KV 传输,并利用 Ray 的分布式计算原语,根据负载特性实现每个阶段的独立自动扩缩。总而言之,该解决方案为推理工作负载提供了一个灵活且可编程的层,可以轻松扩展和组合以实现多样化的服务模式。
路线图
vLLM 持续改进中,目前正在进行以下工作:
- 弹性专家并行
- 长上下文服务
- 通过 CPU 进行 KV 缓存传输
- 完全确定性和批次不变性
- 大型 MoE 优化,例如 DeepSeek-R1 和 gpt-oss 模型的算子融合
- 改进 FlashInfer 与最新内核的集成,例如 SwapAB
- 支持分解式服务部署中独立的 TP 大小
- GB200 大规模服务优化
如需最新参考,请访问 roadmap.vllm.ai。
总结
- vLLM 已完全迁移到 V1 引擎,该引擎在 DeepSeek 风格的 MoE 部署中展现出高吞吐量,并以 wide-EP 实现了 2.2k tok/s/H200 的性能。
- Wide-EP 最大化了 MLA 架构的 KV 缓存效率,而双批次重叠和 EPLB 减少了通信瓶颈和负载不平衡。
- 分解式预填充/解码进一步优化了 MoE 工作负载的预填充和解码部署,并提供 llm-d、Dynamo 和 Ray Serve LLM 等部署选项。