vLLM V1:vLLM 核心架构的重大升级
![]()
我们激动地宣布 vLLM V1 的 alpha 版本发布,这是对 vLLM 核心架构的重大升级。基于我们在过去 1.5 年 vLLM 开发中吸取的经验教训,我们重新审视了关键的设计决策,整合了各种功能,并简化了代码库,以增强灵活性和可扩展性。V1 已经实现了最先进的性能,并且有望获得更多的优化。最棒的是,用户可以无缝启用 V1 —— 只需设置 VLLM_USE_V1=1 环境变量,无需对现有 API 进行任何更改。在未来几周的测试和反馈收集之后,我们计划将 V1 过渡为默认引擎。
为什么选择 vLLM V1?
从 vLLM V0 中学习
在过去的 1.5 年中,vLLM 在支持各种模型、功能和硬件后端方面取得了显著成功。然而,当我们的社区横向扩展时,我们在简化系统以及在堆栈中垂直整合各种优化方面面临挑战。功能通常是独立开发的,使得有效且清晰地组合它们变得困难。随着时间的推移,技术债务累积,促使我们重新审视我们的基础设计。
V1 的目标
基于上述动机,vLLM V1 的设计目标是:
- 提供一个简单、模块化且易于 hack 的代码库。
- 确保高性能,并且 CPU 开销接近于零。
- 将关键优化整合到一个统一的架构中。
- 通过默认启用功能/优化,实现 零配置。
V1 的范围
vLLM V1 引入了对其核心组件的全面重新架构,包括调度器、KV 缓存管理器、worker、采样器和 API 服务器。然而,它仍然与 vLLM V0 共享许多代码,例如模型实现、GPU 内核、分布式控制平面和各种实用函数。这种方法使 V1 能够在利用 V0 建立的广泛覆盖范围和稳定性的同时,显着增强性能和降低代码复杂性。
vLLM V1 的新特性?
1. 优化的执行循环和 API 服务器
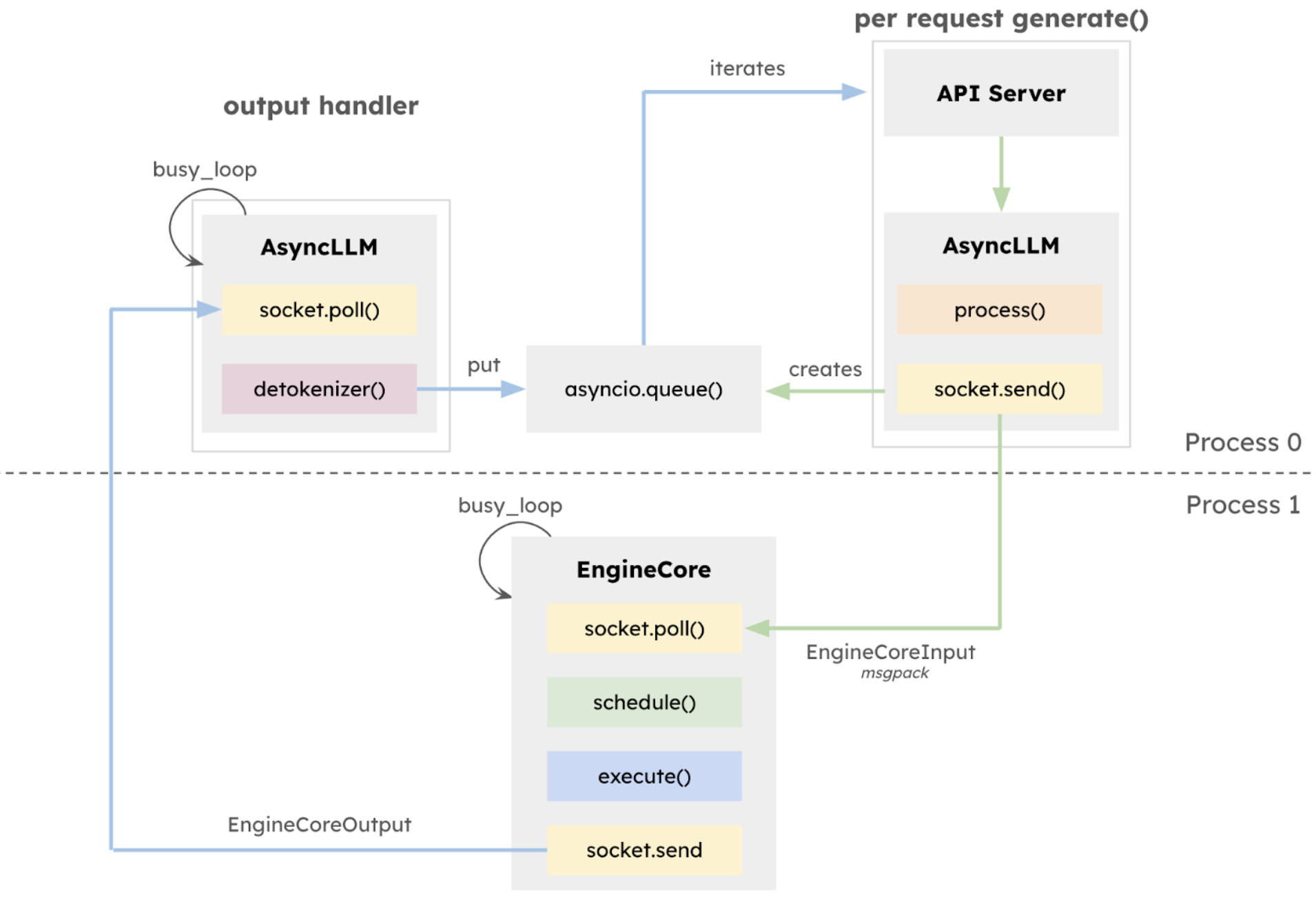
作为一个成熟的连续批处理引擎和兼容 OpenAI 的 API 服务器,vLLM 的核心执行循环依赖 CPU 操作来管理模型前向传递之间的请求状态。随着 GPU 变得越来越快,并显著减少了模型执行时间,用于运行 API 服务器、调度工作、准备输入、反token化输出以及向用户流式传输响应等任务的 CPU 开销变得越来越明显。对于像 Llama-8B 这样在 NVIDIA H100 GPU 上运行的小型模型,这个问题尤其突出,因为在 GPU 上的执行时间低至约 5 毫秒。
在 v0.6.0 版本 中,vLLM 引入了一个利用 ZeroMQ for IPC 的多进程 API 服务器,实现了 API 服务器和 AsyncLLM 之间的重叠。vLLM V1 通过将多进程架构更深入地集成到 AsyncLLM 的核心中来扩展这一点,创建了一个隔离的 EngineCore 执行循环,该循环专门专注于调度器和模型执行器。这种设计允许 CPU 密集型任务(如 token 化、多模态输入处理、反token化和请求流式传输)与核心执行循环之间更大的重叠,从而最大化模型吞吐量。
2. 简单且灵活的调度器
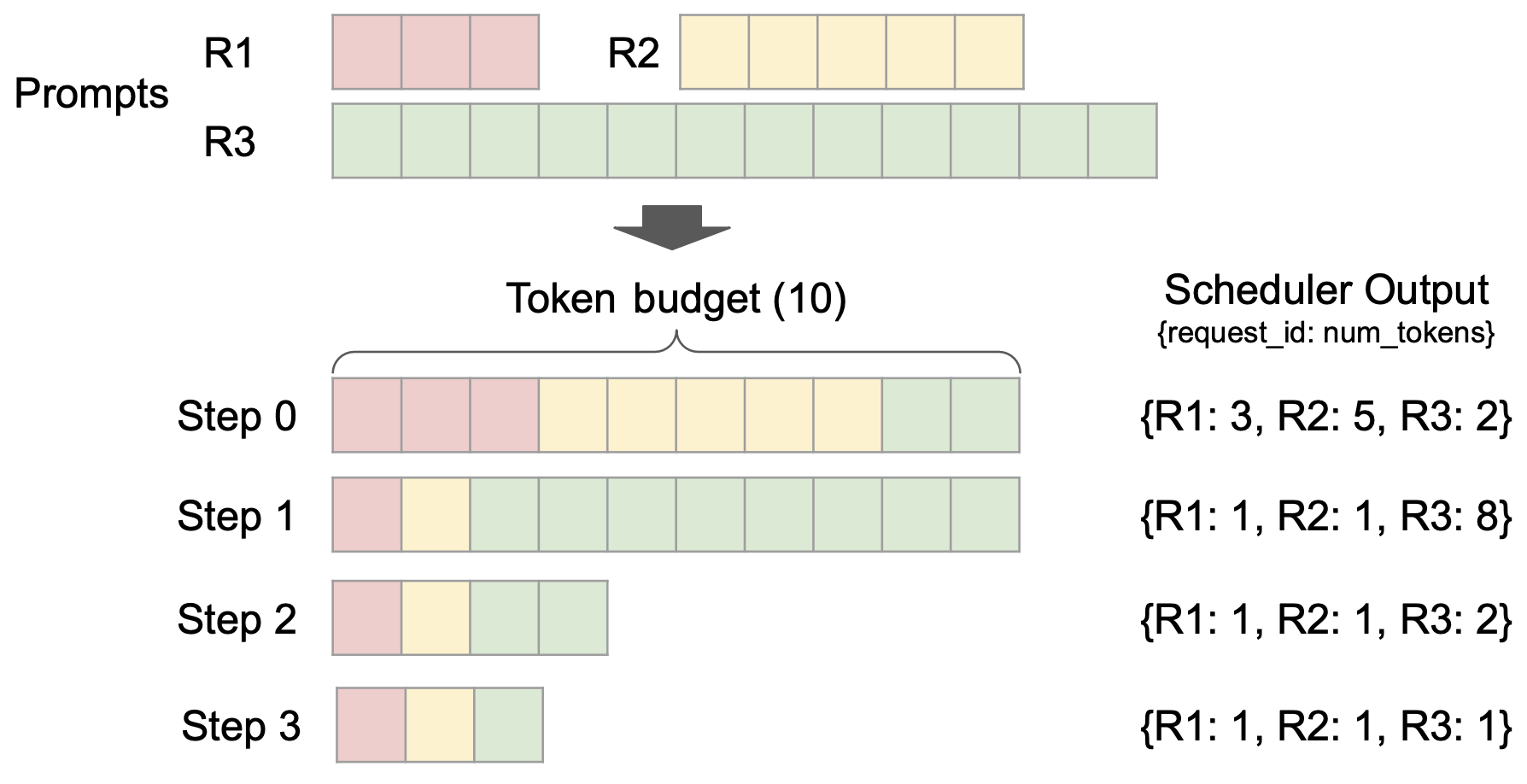
vLLM V1 引入了一个简单而灵活的调度器。它消除了传统的“预填充”和“解码”阶段之间的区别,统一对待用户给定的 prompt tokens 和模型生成的输出 tokens。调度决策表示为一个简单的字典,例如,{request_id: num_tokens},它指定了在每个步骤中要为每个请求处理的 tokens 数量。我们发现这种表示足够通用,可以支持分块预填充、前缀缓存和推测解码等功能。例如,分块预填充调度可以无缝实现:在固定的 tokens 预算下,调度器动态决定为每个请求分配多少 tokens(如上图所示)。
3. 零开销前缀缓存
与 V0 一样,vLLM V1 使用基于哈希的前缀缓存和基于 LRU 的缓存驱逐。在 V0 中,启用前缀缓存有时会导致显著的 CPU 开销,当缓存命中率较低时,会导致性能明显下降。因此,默认情况下它是禁用的。在 V1 中,我们优化了数据结构以实现恒定时间的缓存驱逐,并仔细地最小化了 Python 对象创建开销。这使得 V1 的前缀缓存引入的性能下降几乎为零,即使缓存命中率为 0% 也是如此。
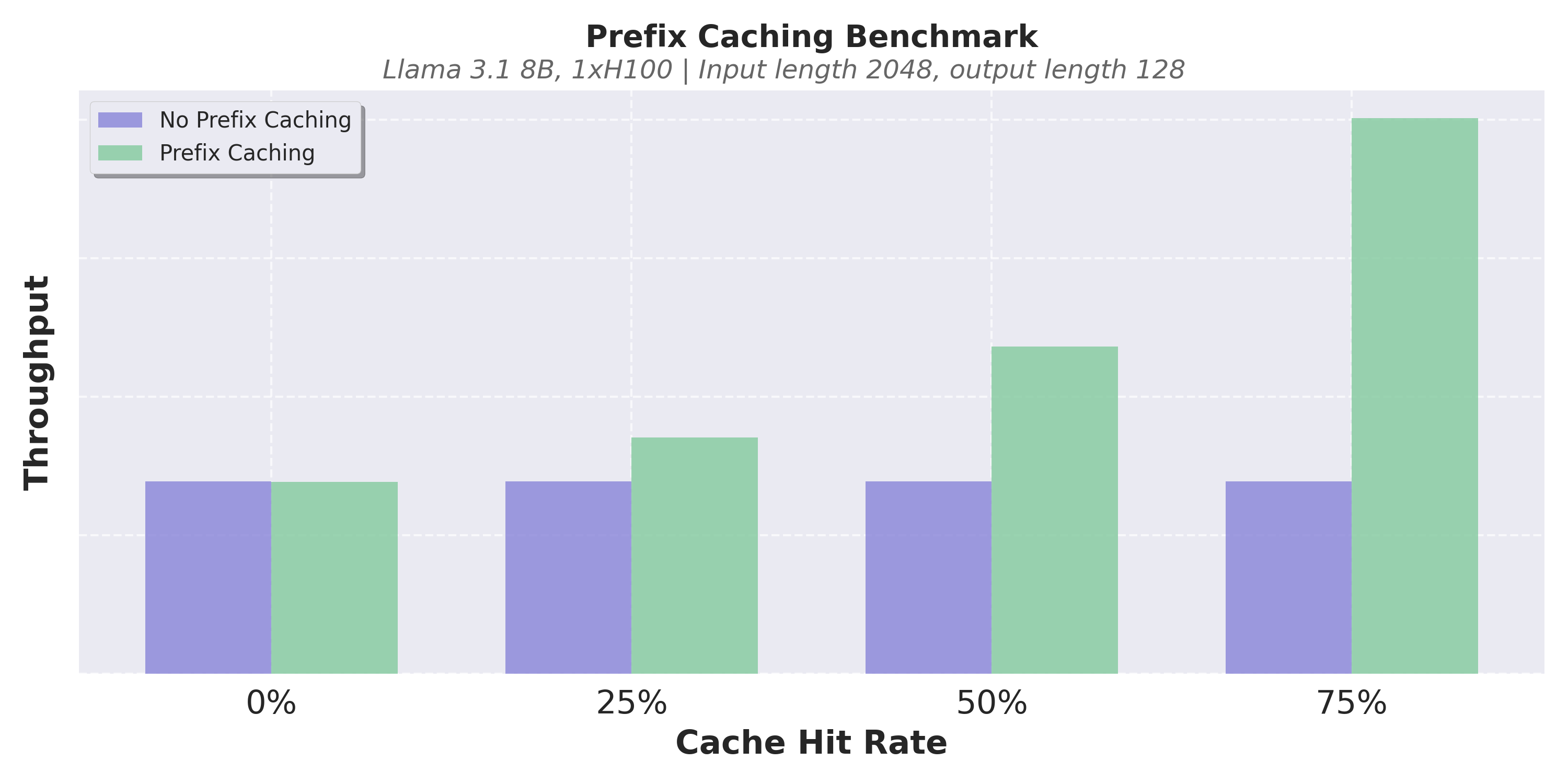
以下是一些基准测试结果。在我们的实验中,我们观察到,即使缓存命中率为 0%,V1 的前缀缓存也只会导致吞吐量下降不到 1%,而当缓存命中率较高时,它可以将性能提高数倍。由于近乎零开销,我们现在在 V1 中默认启用前缀缓存。
4. 用于张量并行推理的清晰架构
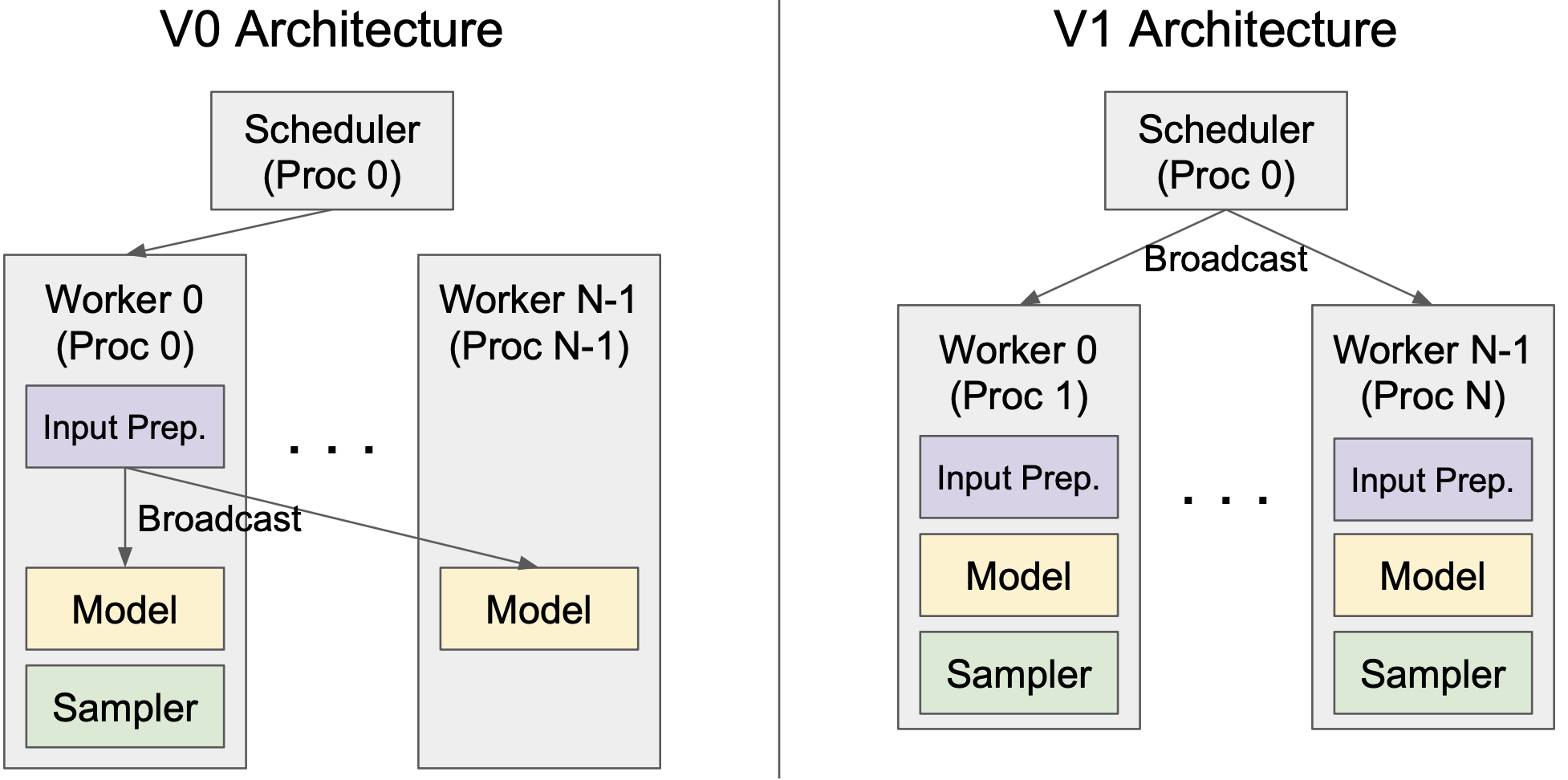
vLLM V1 引入了一个用于张量并行推理的清晰高效的架构,有效地解决了 V0 的局限性。在 V0 中,调度器和 Worker 0 位于同一进程中,以减少将输入数据广播到 workers 时的进程间通信开销。然而,这种设计引入了不对称架构,增加了复杂性。V1 通过在 worker 端缓存请求状态并在每个步骤仅传输增量更新(差异)来克服这一点。这种优化最大限度地减少了进程间通信,允许调度器和 Worker 0 在单独的进程中运行,从而产生清晰的对称架构。此外,V1 抽象出了大部分分布式逻辑,使 workers 在单 GPU 和多 GPU 设置中都以相同的方式运行。
5. 高效的输入准备

在 vLLM V0 中,模型的输入张量和元数据在每个步骤都会重新创建,这通常会导致显著的 CPU 开销。为了优化这一点,V1 实现了 Persistent Batch 技术,该技术缓存输入张量,并在每个步骤仅对其应用差异。此外,V1 通过广泛使用 Numpy 操作而不是 Python 的原生操作,最大限度地减少了更新张量时的 CPU 开销。
6. torch.compile 和分段 CUDA 图

V1 利用 vLLM 的 torch.compile 集成来自动优化模型。这使得 V1 能够高效地支持各种模型,同时最大限度地减少编写自定义内核的需求。此外,V1 引入了分段 CUDA 图,以缓解 CUDA 图的局限性。我们正在准备关于 torch.compile 集成和分段 CUDA 图的专门博客文章,所以请继续关注更多更新!
7. 增强对多模态 LLM 的支持
vLLM V1 将多模态大型语言模型 (MLLM) 视为一等公民,并在其支持中引入了多项关键改进。
首先,V1 通过将多模态输入预处理移动到非阻塞进程来优化它。例如,图像文件(例如,JPG 或 PNG)必须转换为像素值张量,裁剪和转换后才能馈送到模型中。这种预处理可能会消耗大量的 CPU 周期,可能会使 GPU 处于空闲状态。为了解决这个问题,V1 将预处理任务卸载到单独的进程,防止它阻塞 GPU worker,并添加预处理缓存,以便在请求之间共享相同的多模态输入时可以重用已处理的输入。
其次,V1 为多模态输入引入了前缀缓存。除了 token ID 的哈希值之外,图像哈希值也用于识别图像输入的 KV 缓存。这种改进对于包含图像输入的多轮对话尤其有利。
第三,V1 为带有“encoder cache”的 MLLM 启用了分块预填充调度。在 V0 中,图像输入和文本输入必须在同一步骤中处理,因为 LLM 解码器的 token 依赖于视觉嵌入,而视觉嵌入在步骤后会被丢弃。借助 encoder cache,V1 临时存储视觉嵌入,允许调度器将文本输入分成块并在多个步骤中处理它们,而无需在每个步骤都重新生成视觉嵌入。
8. FlashAttention 3
vLLM V1 的最后一块拼图是集成 FlashAttention 3。鉴于 V1 中高度的动态性(例如在同一批次中组合预填充和解码),一个灵活且高性能的注意力内核至关重要。FlashAttention 3 有效地满足了这一要求,为广泛的功能提供了强大的支持,同时在各种用例中保持了出色的性能。
性能
得益于广泛的架构增强,vLLM V1 实现了最先进的吞吐量和延迟,与 V0 相比,吞吐量提高了高达 1.7 倍(不包括多步调度)。这些显著的性能提升源于整个堆栈中全面的 CPU 开销降低。对于像 Qwen2-VL 这样的视觉语言模型 (VLM),改进更加明显,这要归功于 V1 对 VLM 的增强支持。
- 文本模型:Llama 3.1 8B 和 Llama 3.3 70B
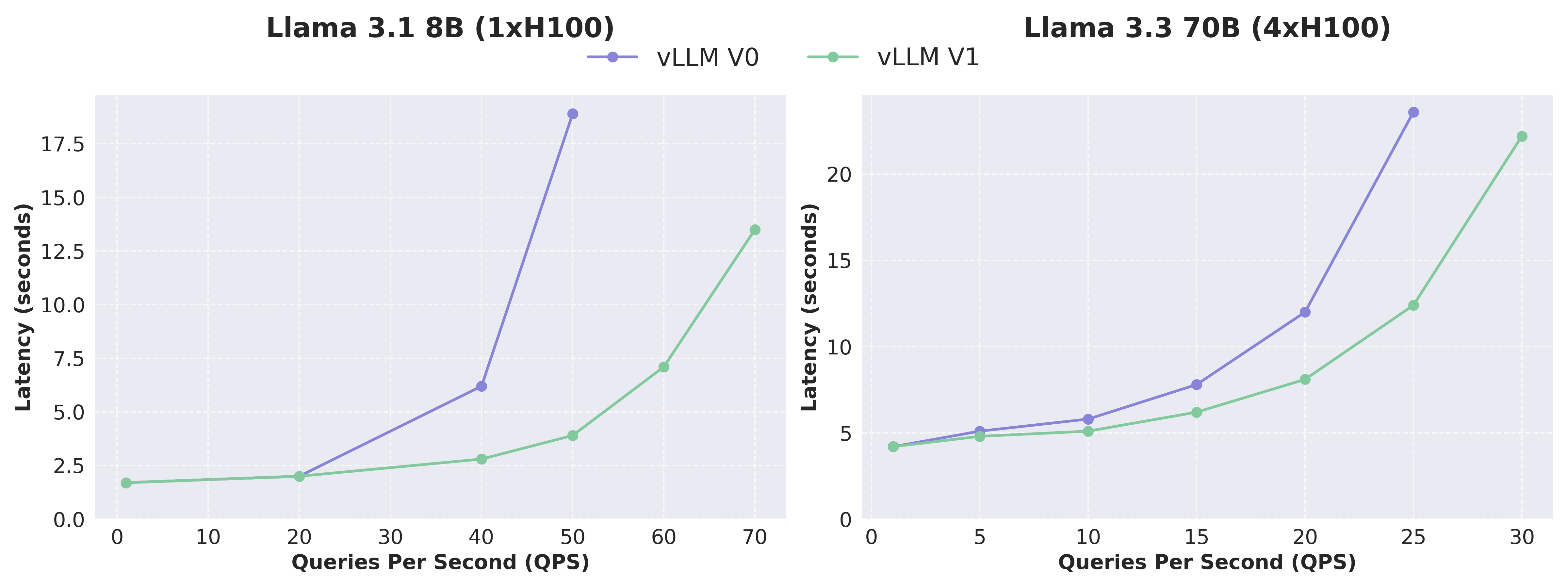
我们使用 ShareGPT 数据集测量了 vLLM V0 和 V1 在 Llama 3.1 8B 和 Llama 3.3 70B 模型上的性能。V1 展示了始终低于 V0 的延迟,尤其是在高 QPS 下,这要归功于它实现的更高吞吐量。鉴于 V0 和 V1 使用的内核几乎相同,性能差异主要归因于 V1 中的架构改进(降低了 CPU 开销)。
- 视觉语言模型:Qwen2-VL
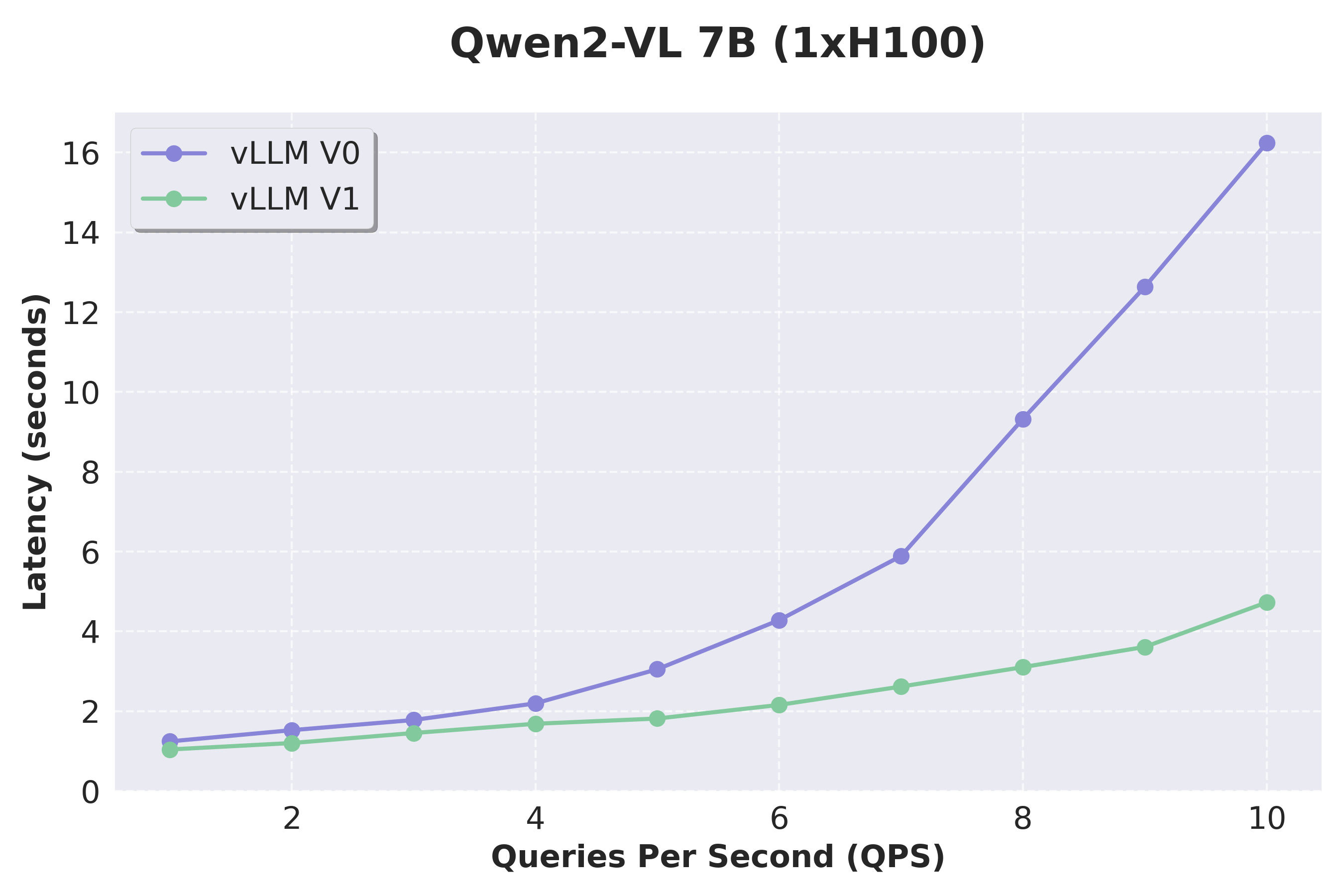
我们通过使用 VisionArena 数据集测试 Qwen2-VL 来评估 VLM 的性能。V1 实现了比 V0 更大的加速,这要归功于其改进的 VLM 支持,这得益于两项关键改进:将输入处理卸载到单独的进程,以及为多模态查询实现更灵活的调度。我们还要指出,前缀缓存现在在 V1 中原生支持多模态模型,但在此处将跳过基准测试结果。
- 展望未来
虽然这些改进意义重大,但我们认为这仅仅是开始。重新设计的架构提供了一个坚实的基础,这将有助于新功能的快速开发。我们期待在未来几周内分享更多的增强功能。请继续关注更多更新!
局限性与未来工作
虽然 vLLM V1 显示出令人鼓舞的结果,但它仍处于 alpha 阶段,并且缺少 V0 的一些功能。以下是一些澄清:
模型支持
V1 支持仅解码器 Transformer 模型,如 Llama,混合专家 (MoE) 模型,如 Mixtral,以及一些 VLM,如 Qwen2-VL。支持所有量化方法。但是,V1 目前不支持编码器-解码器架构,如多模态 Llama 3.2、基于 Mamba 的模型,如 Jamba,或嵌入模型。请查看 我们的文档 以获取更详细的支持模型列表。
功能限制
V1 目前缺少对 log probs、prompt log probs 采样参数、流水线并行、结构化解码、推测解码、Prometheus 指标和 LoRA 的支持。我们正在积极努力弥合这一功能差距,并向 V1 引擎添加全新的优化。
硬件支持
V1 目前仅支持 Ampere 或更高版本的 NVIDIA GPU。我们正在积极努力将支持扩展到其他硬件后端,如 TPU。
最后,请注意,您可以通过不设置 VLLM_USE_V1=1 来继续使用 V0 并保持向后兼容性。
如何开始使用
要使用 vLLM V1:
- 使用
pip install vllm --upgrade安装最新版本的 vLLM。 - 设置环境变量
export VLLM_USE_V1=1。 - 使用 vLLM 的 Python API 或兼容 OpenAI 的服务器 (
vllm serve <model-name>)。您无需对现有 API 进行任何更改。
请试用并分享您的反馈!
致谢
我们衷心感谢 vLLM V1 的设计基于并增强了几个开源 LLM 推理引擎,包括 LightLLM、LMDeploy、SGLang、TGI 和 TRT-LLM。这些引擎对我们的工作产生了重大影响,我们从中获得了宝贵的见解。
V1 重新架构是整个 vLLM 团队和社区持续共同努力的成果。以下是对此里程碑做出贡献的不完整列表:
- UC Berkeley、Neural Magic (现为 Red Hat)、Anyscale 和 Roblox 主要共同推动了这项工作。
- Woosuk Kwon 发起了该项目并实现了调度器和模型运行器。
- Robert Shaw 实现了优化的执行循环和 API 服务器。
- Cody Yu 实现了文本和图像输入的高效前缀缓存。
- Roger Wang 领导了 V1 中整体增强的 MLLM 支持。
- Kaichao You 领导了 torch.compile 集成并实现了分段 CUDA 图。
- Tyler Michael Smith 使用 Python 多进程实现了张量并行支持。
- Rui Qiao 使用 Ray 实现了张量并行支持,并且正在实现流水线并行支持。
- Lucas Wilkinson 添加了对 FlashAttention 3 的支持。
- Alexander Matveev 实现了多模态输入的优化预处理器,并且正在实现 TPU 支持。
- Sourashis Roy 在采样器中实现了 logit penalties。
- Cyrus Leung 领导了 MLLM 输入处理重构工作,并帮助将其集成到 V1。
- Russell Bryant 解决了几个与多进程相关的问题。
- Nick Hill 优化了引擎循环和 API 服务器。
- Ricky Xu 和 Chen Zhang 帮助重构了 KV 缓存管理器。
- Jie Li 和 Michael Goin 帮助进行了 MLLM 支持和优化。
- Aaron Pham 正在实现结构化解码支持。
- Varun Sundar Rabindranath 正在实现多 LoRA 支持。
- Andrew Feldman 正在实现 log probs 和 prompt log probs 支持。
- Lily Liu 正在实现推测解码支持。
- Kuntai Du 正在实现预填充解聚和 KV 缓存传输支持。
- Simon Mo 和 Zhuohan Li 为 V1 系统设计做出了贡献。