追求 100% 准确率:深入探究 Kimi K2 在 vLLM 上的工具调用调试
长话短说 (TL;DR): 为了与 vLLM 获得最佳兼容性,请使用在 commit 94a4053eb8863059dd8afc00937f054e1365abbd (Kimi-K2-0905) 或 commit 0102674b179db4ca5a28cd9a4fb446f87f0c1454 (Kimi-K2) 之后更新了聊天模板的 Kimi K2 模型。这些更新是针对每个模型单独提交的。
引言
Agentic(智能体)工作流正在重塑我们与大语言模型的交互方式,而强大的工具调用能力是推动这场革命的引擎。月之暗面(Moonshot AI)的 Kimi K2 模型以其卓越的工具调用能力而闻名。为了在高性能的 vLLM 服务引擎上验证其性能,我使用了官方的 K2-Vendor-Verifier 基准测试。
我的目标雄心勃勃:复现月之暗面原生 API 上近乎完美的性能。他们的官方端点设立了很高的标准,执行数千次工具调用,无一出现 schema 验证错误——这是可靠性的黄金标准。
基准测试:在月之暗面 API 上运行 K2-Vendor-Verifier
| 模型名称 | 提供商 | 完成原因:stop | 完成原因:tool_calls | 完成原因:其他 | Schema 验证错误 | 成功工具调用次数 |
|---|---|---|---|---|---|---|
Moonshot AI |
MoonshotAI | 2679 | 1286 | 35 | 0 | 1286 |
Moonshot AI Turbo |
MoonshotAI | 2659 | 1301 | 40 | 0 | 1301 |
然而,我初次尝试在 vLLM 上运行 K2 的结果却令人震惊。开箱即用的性能不仅不理想,简直是完全无法工作。
vLLM 上的初步测试结果
- vLLM 版本:
v0.11.0 - HF 模型:
moonshotai/Kimi-K2-Instruct-0905,commit09d5f937b41ae72c90d7155c9a901e2b5831dfaf
| 模型名称 | 完成原因:stop | 完成原因:tool_calls | 完成原因:其他 | Schema 验证错误 | 成功工具调用次数 |
|---|---|---|---|---|---|
Kimi-K2-Instruct-0905(初始 HF 版本) |
3705 | 248 | 44 | 30 | 218 |
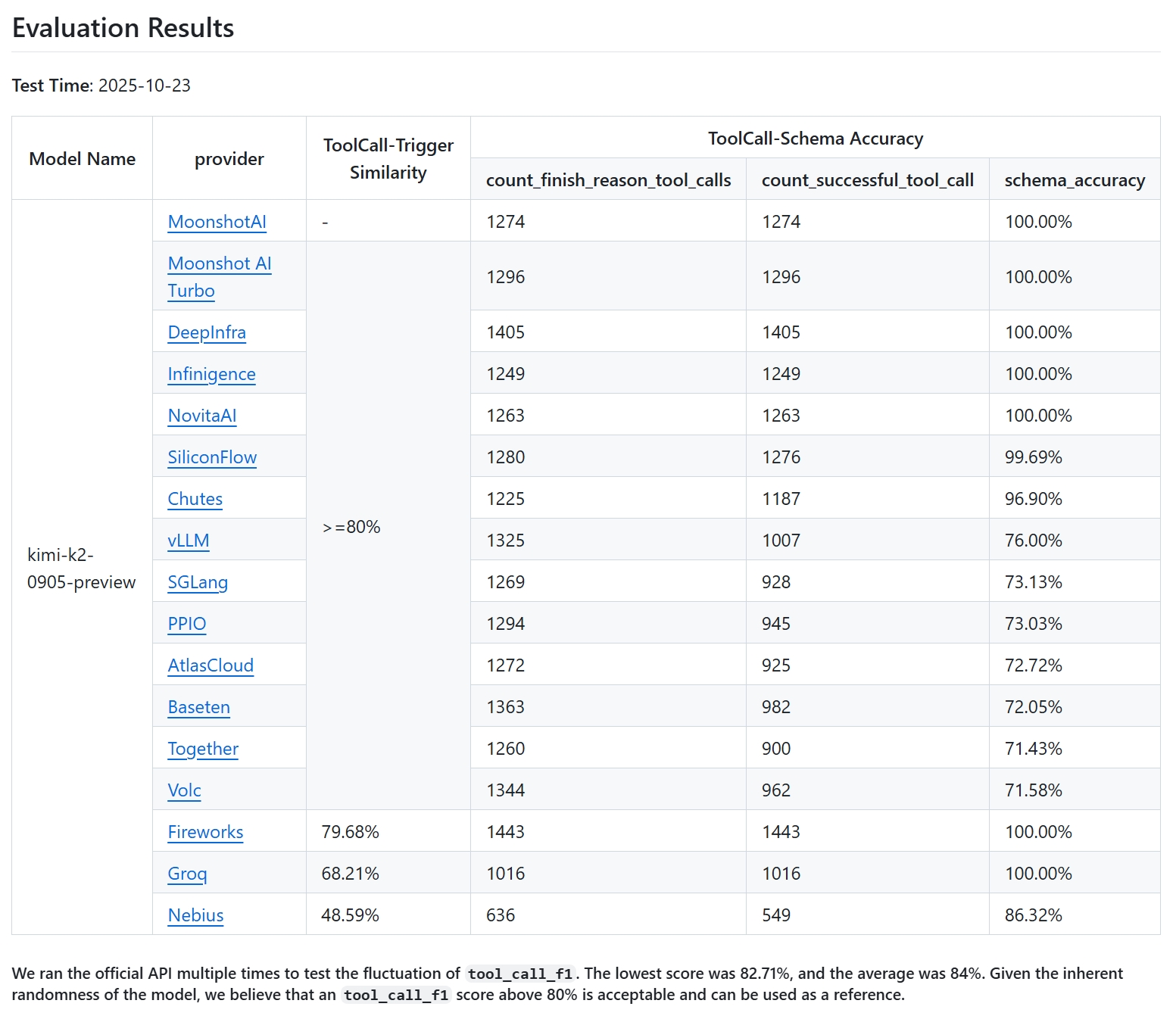
在超过 1200 次潜在的工具调用中,只有 218 次被成功解析——成功率低于 20%。这不仅仅是一个小 bug,而是模型和服务引擎之间通信的根本性崩溃。这篇博客文章记录了我深入调试这一差异的过程,揭示了 Kimi K2 的 chat_template 与 vLLM 之间三个关键的兼容性问题。这段经历不仅帮助我们显著提升了性能,也为任何将复杂模型与现代服务框架集成的人提供了宝贵的经验。
调试之旅:揭示三大核心问题
问题一:缺失的 add_generation_prompt
我的第一个线索是模型行为的根本性崩溃。在基准测试中,本应触发工具调用的请求却以 finish_reason: stop 结束。但根本问题更为广泛:模型根本没有生成结构化的助手回复。它不是在回应用户,而只是用纯文本继续对话,这种行为在任何聊天场景中都会降低性能,而不仅仅是在工具调用中。
调查过程
为了隔离问题,我设计了一个关键实验。我没有使用 vLLM 的高级 /v1/chat/completions 端点,而是采用了一个两步手动流程:首先,我外部调用 tokenizer 的 apply_chat_template 函数来生成完整的提示字符串。然后,我将这个字符串发送到更底层的 /v1/completions 端点。这个手动过程绕过了 vLLM 内部的模板应用,并且至关重要地解决了大部分失败案例。问题显然出在 vLLM 使用 聊天模板的方式上。
根本原因
深入研究发现,Kimi tokenizer 的 apply_chat_template 函数签名中包含 **kwargs,用于接受额外的、模型特定的参数。其中一个参数 add_generation_prompt=True 对于正确格式化提示以表示助手回合的开始至关重要,它能引导模型生成工具调用。
一个正确的提示应该以特殊 token 结尾,以引导模型扮演助手的角色
Correct Prompt Suffix: ...<|im_assistant|>assistant<|im_middle|>
然而,由于 vLLM 没有传递 add_generation_prompt=True,提示在用户消息之后就被截断了。这个格式错误的提示使模型缺少了开始其回合的关键指令。结果,它不知道应该生成工具调用、文本回复还是任何结构化响应,从而完全偏离了方向。发生这种情况的原因是,出于安全考虑(详见 PR #25794),vLLM 会检查函数签名,并且只传递明确定义的参数。由于 add_generation_prompt 隐藏在 **kwargs 中,vLLM 将其丢弃,导致提示格式化在没有提示的情况下失败了。
解决方案
在确定了根本原因后,我与 Kimi 团队合作。他们响应非常迅速,并根据我的发现,在 Hugging Face Hub 上更新了模型的 tokenizer_config.json。解决方法是明确声明 add_generation_prompt 是聊天模板支持的参数。这使得 vLLM 能够正确传递该参数,从而修复了导致工具调用失败的主要来源。此外,我提交了这个 PR,在 tokenizer 通过 **kwargs 接受参数时,将标准的聊天模板参数列入白名单,以防止工具调用在无提示的情况下失败。
问题二:空的 content 如何让提示偏离轨道
第一个问题解决后,一类新的、更微妙的提示格式错误浮出水面。
调查过程
我将这些错误追溯到包含历史工具调用的对话中,其中 content 字段是一个空字符串('')。我发现了一个细微但关键的转换:vLLM 为了追求标准化的内部表示,会自动将一个简单的空字符串 content: '' 提升为一个更复杂的字典列表结构:content: [{'type': 'text', 'text': ''}]。
根本原因
Kimi 基于 Jinja 的聊天模板设计用于渲染字符串类型的 content。当它意外地收到一个列表时,它无法正确处理,而是将列表的字面字符串表示插入到最终的提示中。
错误的提示片段
...<|im_end|><|im_assistant|>assistant<|im_middle|>[{'type': 'text', 'text': ''}]<|tool_calls_section_begin|>...
正确的提示片段
...<|im_end|><|im_assistant|>assistant<|im_middle|><|tool_calls_section_begin|>...
这个关键的格式错误造成了一个格式不正确的提示,足以混淆模型的生成逻辑。
解决方案
我提议修改 chat_template 逻辑,使其更具鲁棒性。Kimi 团队表示同意并迅速实施了更新。现在,该模板会明确检查 content 字段的类型。如果它是一个字符串,就直接渲染;如果它是一个可迭代对象(如列表),则会正确处理它,从而防止格式错误。
问题三:过于严格的工具调用 ID 解析器
最后,我注意到即使模型生成了语法正确的工具调用,vLLM 有时也无法解析它。这个问题尤其隐蔽,因为它往往不是源于当前回合,而是源于提供给模型的对话历史。
调查过程
通过检查 vLLM 的原始 text_completion 输出,罪魁祸首变得显而易见。我发现在某些边缘情况下,特别是当被格式错误的对话历史误导时,模型会生成不严格符合 Kimi 官方规范的工具调用 ID。例如,考虑以下输出:
...<|tool_calls_section_begin|><|tool_call_begin|>search:2<|tool_call_argument_begin|>...
在这里,模型输出的 ID 是 search:2。然而,Kimi 的官方文档指定的格式是 functions.func_name:idx。
根本原因
为什么模型会生成一个不合规的 ID?正如 Kimi 团队解释的那样,一个常见的原因是被对话历史“误导”。Kimi-K2 模型期望历史消息中的所有工具调用 ID 都遵循 functions.func_name:idx 格式。然而,如果来自不同系统的历史消息包含一个格式不正确的工具调用 ID,比如 search:0,Kimi 模型可能会对这种陌生的格式感到困惑,并试图在其响应中生成一个“相似”但不正确的 ID。
有趣的是,这在 Kimi 的官方 API 上不是问题,因为在调用 K2 模型之前,他们的 API 会自动重命名所有历史工具调用 ID,使其符合 functions.func_name:idx 标准。这个预处理步骤起到了一个保护作用,而这在我的直接 vLLM 设置中是缺失的。
vLLM 的工具调用解析器逻辑过于脆弱,无法处理这种偏差。它严格依赖官方格式,使用类似于 function_id.split('.')[1].split(':')[0] 的代码来提取函数名。当遇到 search:2 时,初始的 . 分割失败,引发了 IndexError,导致整个有效的工具调用被丢弃。
解决方案
Kimi 团队推荐的最有效的修复方法是,用户和供应商采用类似的预处理步骤:在将所有历史工具调用 ID 发送给模型之前,确保将其规范化为 functions.func_name:idx 格式。在我的案例中,修复前两个提示格式问题也显著减少了这些不合规 ID 的出现频率,因为格式正确的上下文使模型更有可能生成正确的输出。此外,我已向 vLLM 社区提议改进解析器的鲁棒性,以更好地处理微小的格式偏差(见此 PR)。
最终结果与新发现
在 Kimi 团队应用了所有修复并在 Hub 上更新了 tokenizer 之后,我重新运行了 K2-Vendor-Verifier,看到了巨大的改进。
vLLM 上的最终测试结果(修复后)
| 指标 | 值 | 描述 |
|---|---|---|
| 工具调用 F1 分数 | 83.57% | 精确率和召回率的调和平均值,衡量模型是否在正确的时间触发工具调用。 |
| 精确率 (Precision) | 81.96% | TP / (TP + FP)。 |
| 召回率 (Recall) | 85.24% | TP / (TP + FN)。 |
| Schema 准确率 | 76.00% | 语法正确并通过验证的工具调用的百分比。 |
| 成功工具调用次数 | 1007 | 成功解析和验证的工具调用总数。 |
| 触发的工具调用总数 | 1325 | 模型尝试调用工具的总次数。 |
| Schema 验证错误 | 318 | 解析或验证失败的已触发工具调用数量。 |
| 总体成功率 | 99.925% | 在总共 4000 个请求中成功完成的百分比 (3997/4000)。 |
成功解析的工具调用数量从 218 次飙升至 971 次——实现了 4.4 倍的提升,使我们更接近官方 API 的性能。然而,一个新的问题浮出水面:出现了 316 个 schema_validation_error_count。深入研究后,我发现在 vLLM 上的模型有时会调用**在当前请求中未声明**的工具(例如,即使当前回合未提供 img_gen 工具,也会使用聊天历史中的该工具)。
这是一个已知的模型幻觉问题。像月之暗面的 API 这样的专有服务部署了一个关键的保护措施,称为“强制执行器”(Enforcer)。该组件充当守门员,实施约束解码,以确保模型*只能*生成与请求中明确提供的工具相对应的 token。vLLM 目前缺少此功能,这为开源社区未来的贡献提供了一个激动人心的机会。Kimi 团队正在积极与 vLLM 团队合作,将“强制执行器”组件集成到 vLLM 中。
关键经验与最佳实践
这次深入探究为所有在 LLM 和服务基础设施交叉领域工作的人提供了几个宝贵的教训:
- 细节决定成败,尤其在聊天模板中:
chat_template是模型与其服务框架之间关键的“握手协议”。在集成新模型时,务必根据框架的具体行为和假设,仔细验证模板逻辑的每一部分。 - 揭开抽象层的面纱: 像
/chat/completions这样的高级 API 很方便,但可能会掩盖根本原因。在调试时,不要犹豫,直接使用像/completions这样的底层端点。手动构建输入是隔离问题的强大技巧。 - 一个专业提示:Token ID 是最终的真相: 对于最细微的问题,检查发送给模型的最终 token ID 序列是唯一确定的方法。虽然我没有在上述问题中用到它,但这是工具箱中一个至关重要的工具。使用 OpenAI 兼容 API 返回 token ID 等技术可以救你于水火。有兴趣的读者可以参考我们之前的 Agent Lightning 博文。
- 理解框架的设计哲学: vLLM 对
**kwargs的严格处理不是一个 bug,而是一个深思熟虑的安全选择。理解这些设计决策有助于快速识别根本原因,而不是纠结于意外的行为。 - 开放生态系统的挑战: 像工具调用“强制执行器”这样的高级功能是成熟的专有服务的标志。在像 vLLM 这样的开源项目中稳健而优雅地实现这些功能,是社区需要应对的一个重要挑战。
结论
通过系统性和协作性的调试,我们成功解决了 Kimi K2 模型在 vLLM 上的关键工具调用兼容性问题,将其成功率提高了 4 倍以上,使其性能达到了预期水平。这个过程不仅是一项技术挑战,也证明了在一个复杂的软件生态系统中,细致、有条不紊的调查的力量。
我希望这份详细的记录能为其他将复杂模型集成到 vLLM 及其他框架的开发者提供一个有用的路线图。随着开源社区的不断成熟,我们期待为每个人带来更无缝的模型集成体验和更强大的智能体能力。
致谢
我谨向 Kimi 团队的工程师们表示诚挚的感谢。他们深厚的技术专长对于查明根本原因至关重要,并且在问题确定后,他们迅速在 Hugging Face Hub 上实施了必要的修复。没有他们的积极合作与支持,这次探索及其成功的结果是不可能实现的。
此外,我要感谢 vLLM 团队的 Kaichao You 和 Chauncey Jiang,他们帮助我加入了 vLLM 项目,并详细解释了 vLLM 工具调用功能的全部细节。vLLM 在 LLM 服务领域扮演着重要角色,深入研究 vLLM 帮助我理解了 LLM 的核心机制。