告别重分词漂移:在智能体强化学习中,通过 OpenAI 兼容 API 返回 Token ID 至关重要
摘要 (TL;DR): 智能体(Agent)通常通过 OpenAI 兼容的 API 端点调用大语言模型(LLM),这些端点过去只返回基于字符串的输入和输出。在智能体强化学习 (Agent RL) 中,这可能导致训练和推理之间的不一致,我们称之为重分词漂移 (Retokenization Drift) 现象。该现象的发生是因为 token 在推理时被解码成字符串,随后在训练时又被重新编码成 token;尽管对应的字符串完全相同,但这两组 token 可能会有所不同。现在,你可以让 vLLM 的 OpenAI 兼容端点同时返回提示(prompt)和生成响应的确切 token ID。只需将 "return_token_ids": true 传递给 /v1/chat/completions 或 /v1/completions,你就会在常规文本输出的同时收到 prompt_token_ids 和 token_ids。这使得智能体强化学习变得更加稳健,因为漂移现象将不复存在。这与 Agent Lightning 完美结合,在 Agent Lightning 中,每次模型调用都被视为一个独立的更新样本,无需拼接;只需通过启用 return_token_ids 来记录返回的 ID 即可。
相关链接
- 文档:OpenAI 兼容服务器
- 可体验此功能的项目:Agent Lightning(GitHub, 文档)
为什么 Token ID 对智能体强化学习至关重要
针对大语言模型的强化学习(RL for LLMs)是在 token 序列上进行训练的,因此训练器需要行为策略(behavior policy)采样出的确切 token ID。在单轮对话(single-turn)设置中,这过去很简单,因为调用 vLLM 的底层 generate 函数会直接返回 token。
在智能体(agent)设置中,大多数智能体框架调用的是 OpenAI 风格的 chat.completions / completions API。智能体之所以更喜欢这些 API 而不是原始的 generate 函数,是因为它们提供了智能体技术栈所依赖的更高层级的功能,例如聊天模板和角色(系统/用户/助手)、工具/函数调用、结构化输出等。然而,这些 API 过去只返回字符串,这在智能体强化学习中可能会引发问题。以前,存储的文本必须在训练期间被重新分词,但由于重分词漂移,这种做法在实践中既不稳定又不准确。
你在强化学习中会看到的症状包括:不稳定的学习曲线(如下图所示),以及你认为已经优化的数据与模型实际采样的数据之间难以调试的差异。
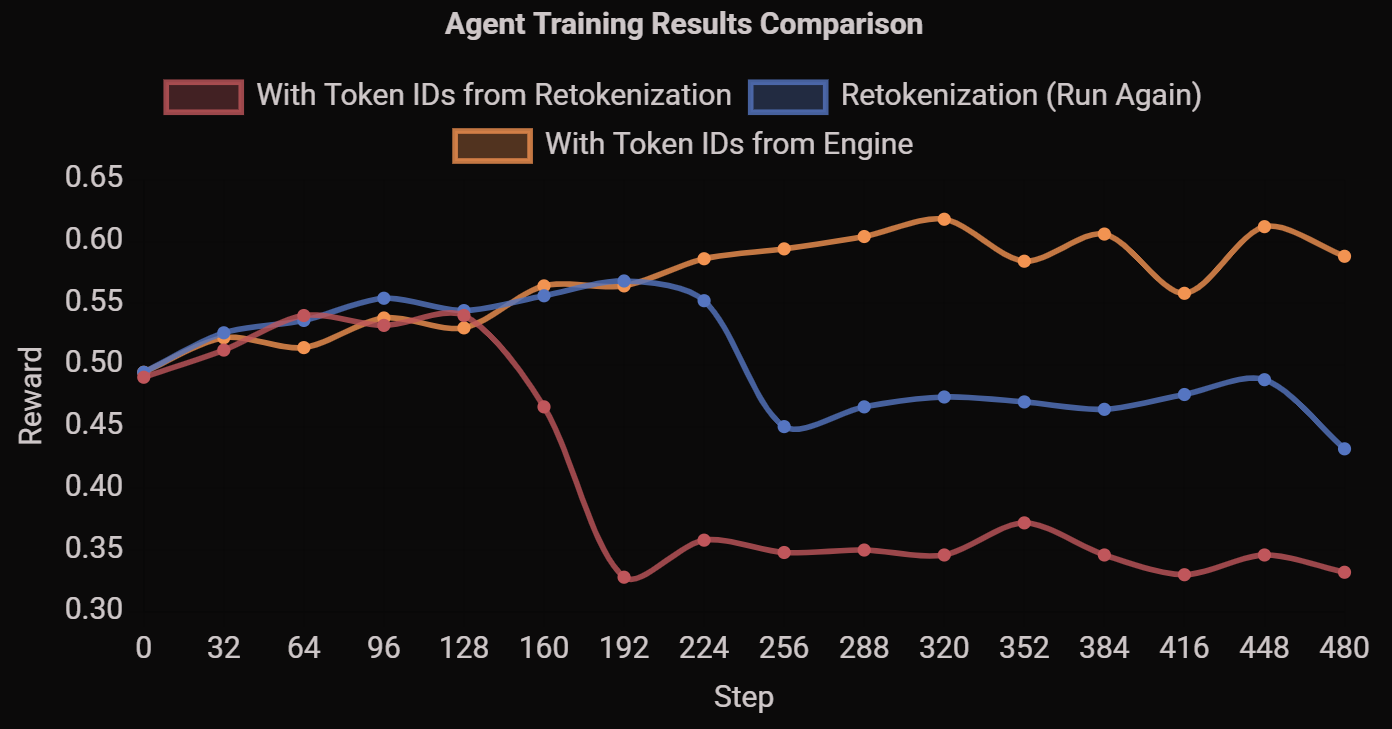
红色和蓝色曲线是在相同设置下(即存储文本并在训练中重分词)获得的结果,而黄色曲线则直接使用了来自推理引擎的 token。
这种漂移可能由以下三个原因造成。
- 非唯一的“HAVING”。在实践中,这种情况经常出现:一个单词在生成时可能由两个 token 组成(例如
H+AVING),但当你稍后在训练中对该文本重新分词时,可能会得到不同的分割(例如HAV+ING)。虽然文本看起来完全相同,但 ID 却不同,这导致你的学习器在错误的序列上进行优化。

单词 "HAVING" 对应了不同的 token。
- 工具调用序列化。一个生成的工具调用文本,如
<tool_call>{ "name": ... }</tool_call>,会被工具调用解析器解析成一个对象,这个对象是聊天补全 API 所需的。随后,该对象又被渲染回<tool_call>{ "name": ... }</tool_call>并再次进行重分词。工具调用的解析和重新渲染可能会导致空格和格式的变化。在某些情况下,JSON 错误甚至可能被工具调用解析器自动修正。这掩盖了模型真实的生成错误,并阻碍了通过训练来修复它们。 - 聊天模板差异。不同框架中使用的聊天模板可能略有不同。例如,同一个 LLaMA 模型可以适配多种聊天模板(在 vLLM 中有多种,在 HuggingFace 中有一种)。当推理和训练使用不同框架时,这种差异会产生不同的 token。
这三个因素导致了重分词漂移,进而引发训练不稳定,原因可能是它们造成了推理和训练之间的不一致,从而导致了离策略(off-policy)的强化学习更新。同策略(On-policy)对于稳定的强化学习训练至关重要,细微的变化都可能产生巨大影响。由重分词漂移引起的离策略效应甚至不是在 token 级别发生的,因此无法通过 token 级别的重要性采样(importance sampling)来纠正。
另一种方案是保存模型生成的 token ID,就像在单轮对话设置中那样。这要求智能体必须在 token 级别与推理引擎进行通信。然而,大多数智能体——尤其是那些使用 LangChain 等框架构建的智能体——依赖于 OpenAI 兼容的 API,无法自行进行分词或解码。关于这部分的更多讨论,请参见此处。
解决方案与新功能
一个更好的解决方案是使用直接返回 token ID 的 OpenAI 兼容 API。Agent Lightning 和 vLLM 团队合作,将此功能直接添加到了 vLLM 核心中。从 vLLM v0.10.2 开始,OpenAI 兼容的 API 包含了一个 return_token_ids 参数,允许在请求聊天消息的同时请求 token ID。当你在请求中将其设置为 true 时,响应将包含两个额外的字段:
prompt_token_ids:输入的 token ID(经过任何聊天模板处理后),以及token_ids:为补全内容生成的 token ID,通过completion.choices传递。
响应中的其他所有内容都保持与 OpenAI 兼容,因此现有的客户端可以继续正常工作。
Agent Lightning (v0.2) 简介
在 Agent Lightning(简称 AGL)的初始版本(v0.1)中,我们为任何智能体提供了一个灵活的强化学习训练框架。它具有几个核心特性:
- 与现有智能体无缝集成,(几乎)无需任何代码更改!
- 可与任何智能体框架(LangChain、OpenAI Agent SDK、Microsoft Agent Framework 等)构建;甚至可以不使用智能体框架(纯 Python 程序)。
- 对 LLM 的输入没有限制,支持灵活的编排,如摘要、多智能体协作以及其他复杂工作流。
Agent Lightning 首次发布时,我们实现了一个经过插桩的 vLLM 服务器,它通过猴子补丁(monkey-patch)的方式修改了 vLLM 的 OpenAI 服务器,使其能够返回 token ID。现在,AGL 会自动为每个请求添加 return_token_ids,以便引擎在其响应中包含 token ID。然后,借助 AGL 内置的追踪(tracing)功能,我们能够自动收集训练器端所需的数据,包括这些 token ID。
智能体优化的中间件
从更精确的数据收集角度出发,在 v0.2 版本中,我们更清晰地定位了 AGL 在智能体优化中的角色。从概念上讲,Agent Lightning(或 AGL)为智能体优化,特别是智能体强化学习,引入了一个可持续的中间件层和标准化的数据协议。

Agent Lightning 概念概览。
Agent Lightning 设计了一套模块化、可互操作的组件,共同实现了可扩展且高效的智能体强化学习。每个组件都扮演着独特的角色,同时通过标准化的数据协议和明确定义的接口进行通信。
- 智能体运行器 (Agent Runner) — 负责执行智能体以完成指定任务。它接收任务,将其委托给智能体执行,收集结果和中间数据,并将这些信息报告回数据存储。智能体运行器与 LLM 端分开运行,因此可以部署在不同的资源上(例如 CPU),并且可以水平扩展以支持大量并发的智能体实例。
- 算法(模型训练器)(Algorithm (Model Trainer)) — 托管用于推理和训练的大语言模型(LLM)。该组件负责协调整个强化学习循环,包括任务采样、轨迹管理 (rollout management) 以及基于收集到的经验数据进行模型更新。它通常在 GPU 资源上运行,并通过共享的数据协议与智能体运行器进行异步交互。
- 数据存储 (Data Store) — 作为中央存储库,负责管理智能体强化学习生态系统内所有的数据交换和存储。它提供标准化的接口和统一的数据模式,以确保异构组件之间的互操作性。通过这种设计,算法和智能体运行器可以间接而有效地进行通信,从而实现灵活且可扩展的协作。例如,使用标准化的
rollouts,算法可以异步地将任务委托给智能体运行器,后者执行任务并通过spans数据结构将执行轨迹报告回来。

Agent Lightning 中的训练循环。
在这种以数据存储为中心的设计理念下,所有的智能体训练迭代都被抽象为两个步骤。第一步是收集智能体运行数据(在 AGL 中称为 spans)并将其存储到数据存储中;第二步是从存储中检索所需数据,并将其发送到算法端进行训练。
这种抽象化的视角带来了几个优势。首先,它提供了更大的算法灵活性:数据收集可以依赖于各种追踪器或发出自定义消息,从而可以轻松地定义不同的奖励或捕获任何中间变量。在算法方面,可以通过查询 spans 来访问所需数据,而自定义的适配器则支持自由的数据转换。
这种设计还支持算法定制,例如信用分配、使用部分数据进行辅助模型学习、通过数据调整来改进训练等。此外,在这个框架内,我们可以扩展到更多类型的算法,比如自动提示调优 (APO),以及筛选高奖励数据并通过 Unsloth 进行拟合。
这种设计的第二个主要优势在于,它能够通过模块化分离来降低整体系统复杂性,同时使不同组件能够利用不同的资源和优化策略。一个智能体强化学习训练系统本质上是复杂的,因为它利用动态的、由环境驱动的交互,使模型能够从经验数据中持续学习。一个典型的智能体强化学习技术栈由几个关键组件组成,包括智能体框架(如 LangChain, MCP)、LLM 推理引擎(如 vLLM)和训练框架(如 Megatron-LM)。如果没有解耦的架构,这些组件的独立性和异构性会导致巨大的系统复杂性。相比之下,解耦设计允许系统适应不同的资源需求:例如,智能体端可能需要更高的 CPU 容量,而 LLM 推理和训练通常是 GPU 密集型的。这种模块化结构还有利于每个组件的独立水平扩展,从而提高了效率和可维护性。
更多材料
- 完整文档
- 鸟瞰视图
- 使用 verl 训练一个 SQL 智能体(含多智能体编排)
- 使用自动提示优化训练一个房间选择智能体,其中提示编排由 POML 提供支持。
- 使用 Unsloth 训练一个数学智能体(使用 OpenAI Agents SDK 与 MCP 构建)
祝您训练愉快!⚡
致谢
我们衷心感谢 vLLM 的维护者们,包括 Kaichao You、Nick Hill、Aaron Pham、Cyrus Leung、Robert Shaw 和 Simon Mo。没有他们的支持与合作,这次整合是不可能完成的。
Agent Lightning 是一个来自微软研究院的开源项目。我们衷心感谢微软研究院对这次开源探索的支持。Yuge Zhang 是这项工作的主要贡献者。