MiniMax-M1 混合架构与 vLLM 的强强联合:长上下文、快推理
本文探讨了 vLLM 如何高效支持 MiniMax-M1 的混合架构。我们将讨论该模型的独特功能、高效推理面临的挑战,以及在 vLLM 中实现的技术解决方案。
引言
人工智能的飞速发展催生了日益强大的大语言模型(LLM)。MiniMax-M1 是一款广受欢迎的开源大规模专家混合(MoE)推理模型,自发布以来备受关注。其创新的混合架构为大语言模型的未来指明了方向,在长上下文推理和复杂任务处理方面实现了突破。与此同时,vLLM 作为一个高性能的 LLM 推理与服务库,为 MiniMax-M1 提供了强有力的支持,使其高效部署成为可能。
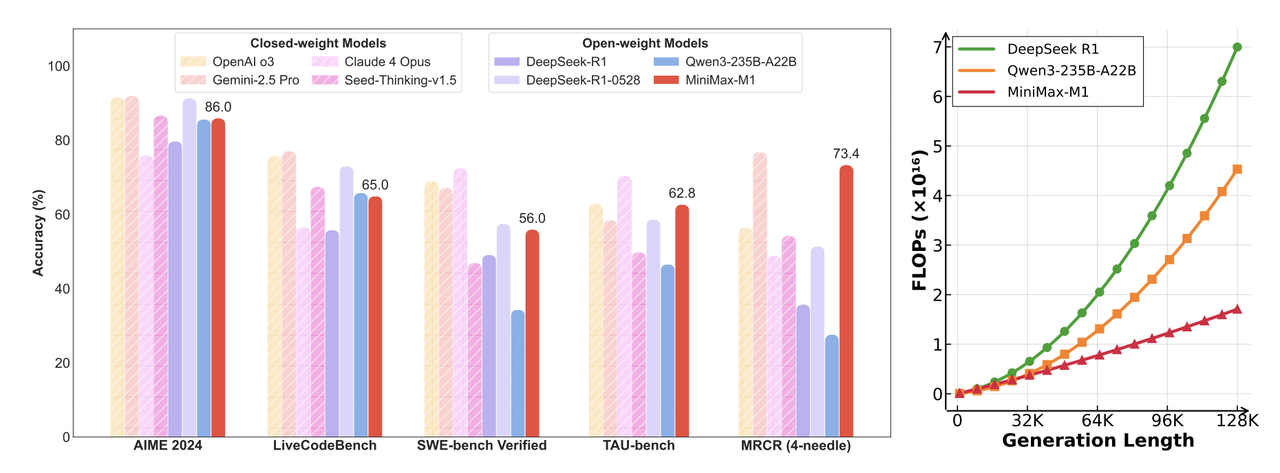
- 左图: 在数学、代码、软件工程、工具使用和长上下文理解等任务上,领先的商业模型和开源模型的基准比较。MiniMax-M1 在开源模型中处于领先地位。
- 右图: 理论推理浮点运算次数(FLOPs)随 Token 长度的变化。与 DeepSeek R1 相比,MiniMax-M1 在生成 10 万 Token 序列时仅需其 25% 的 FLOPs。
使用 vLLM 部署 MiniMax-M1
我们推荐使用 vLLM 部署 MiniMax-M1 以获得最佳性能。我们的测试展示了以下主要优势:
- 卓越的吞吐量
- 高效智能的内存管理
- 对批处理请求的强大支持
- 深度优化的后端性能
模型下载
您可以从 Hugging Face 下载模型
# Install the Hugging Face Hub CLI
pip install -U huggingface-hub
# Download the MiniMax-M1-40k model
huggingface-cli download MiniMaxAI/MiniMax-M1-40k
# For the 80k version, uncomment the following line:
# huggingface-cli download MiniMaxAI/MiniMax-M1-80k
部署
以下是使用 vLLM 和 Docker 快速部署 MiniMax-M1 的指南
# Set environment variables
IMAGE=vllm/vllm-openai:latest
MODEL_DIR=<model storage path>
NAME=MiniMaxImage
# Docker run configuration
DOCKER_RUN_CMD="--network=host --privileged --ipc=host --ulimit memlock=-1 --rm --gpus all --ulimit stack=67108864"
# Start the container
sudo docker run -it \
-v $MODEL_DIR:$MODEL_DIR \
--name $NAME \
$DOCKER_RUN_CMD \
$IMAGE /bin/bash
# Launch MiniMax-M1 Service
export SAFETENSORS_FAST_GPU=1
export VLLM_USE_V1=0
vllm serve \
--model <model storage path> \
--tensor-parallel-size 8 \
--trust-remote-code \
--quantization experts_int8 \
--max_model_len 4096 \
--dtype bfloat16
MiniMax-M1 混合架构亮点
专家混合(MoE)
MiniMax-M1 采用了专家混合(MoE)架构,总参数量达 4560 亿。在推理过程中,动态路由算法会根据输入 Token 的语义特征,激活一个稀疏的专家子集(约 459 亿参数,占总数的 10%)。这种稀疏激活由一个门控网络管理,该网络负责计算专家的选择概率。
这种方法显著提高了计算效率:在分类任务中,它最多可减少 90% 的计算成本,同时保持与稠密模型相当的准确率。
Lightning Attention
Lightning Attention 通过引入线性化近似技术,解决了传统注意力机制的二次复杂度瓶颈。它借助动态内存分块和梯度近似,将 Softmax 注意力转换为矩阵乘法的线性组合。
在代码补全基准测试中,对于 10 万 Token 的序列,Lightning Attention 将内存使用量减少了 83%,推理延迟降低了 67%。
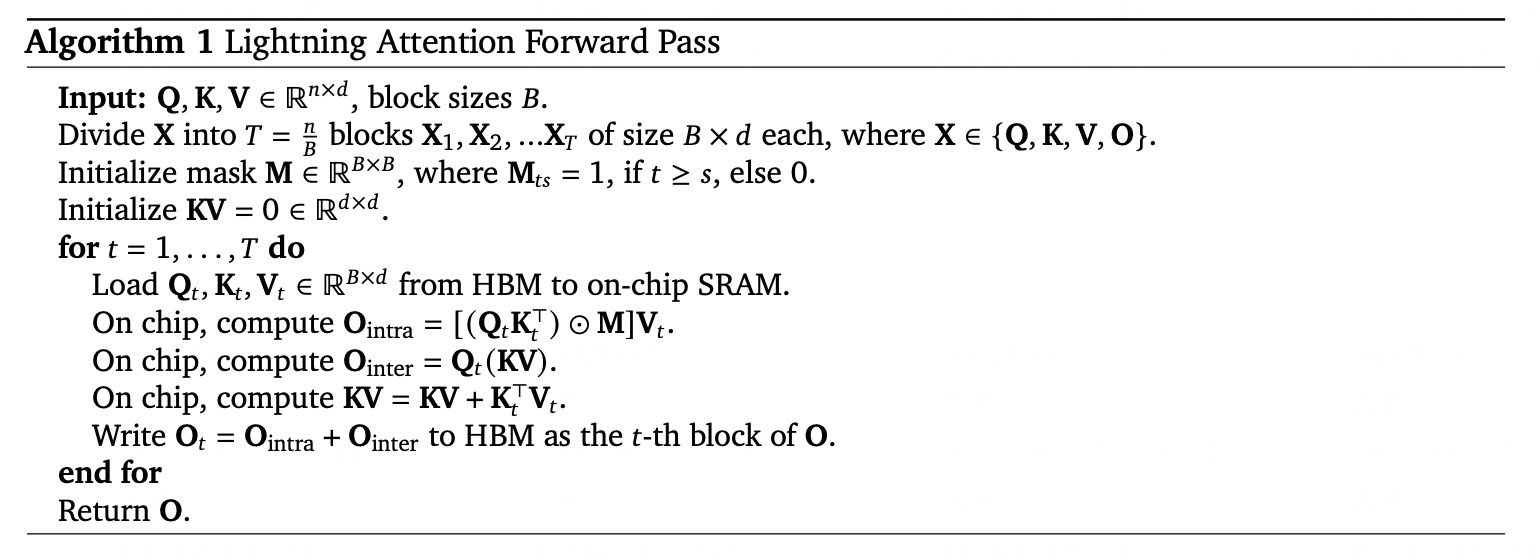
高效计算与激活策略
得益于其混合架构,MiniMax-M1 实现了高效计算和可扩展的推理。Lightning Attention 机制显著提升了运行时性能,而稀疏专家激活策略则避免了不必要的计算。这使得在有限的硬件资源下也能实现强大的性能。
要了解更多关于 MiniMax-M1 的信息,请参阅这篇论文。
使用 vLLM 实现高效推理
先进的内存管理
vLLM 引入了 PagedAttention 技术,以更高效地管理注意力键值缓存(KV Cache)。vLLM 将 KV 缓存划分为多个内存页,而不是连续存储,从而大大减少了内存碎片和过度分配。这使得 vLLM 能够将内存浪费降至 4% 以下,而传统方法则高达 60%-80%。
对于像 MiniMax-M1 这样支持超长上下文的模型来说,这种高效的内存处理至关重要,它能确保推理过程平稳稳定,避免内存瓶颈。
深度的核函数级别优化
vLLM 集成了广泛的 CUDA 核函数优化,包括与 FlashAttention、FlashInfer 的集成,并支持 GPTQ、AWQ、INT4、INT8 和 FP8 等量化格式。
这些增强功能进一步提升了 MiniMax-M1 推理的底层计算效率。量化以极小的精度损失降低了内存和计算开销,而 FlashAttention 则加速了注意力计算本身——从而在实际应用中显著加快了推理速度。
vLLM 中的 Lightning Attention
作为一种前沿的注意力机制,Lightning Attention 在 vLLM 中通过 Triton 实现,利用了其灵活性和高性能计算特性。一个基于 Triton 的执行框架全面支持 Lightning Attention 的核心计算逻辑,使其能够在 vLLM 生态系统内无缝集成和部署。
未来工作
展望未来,vLLM 社区正在积极探索对混合架构的进一步优化。值得注意的是,混合内存分配器的开发有望实现更高效的内存管理,以满足像 MiniMax-M1 这类模型的独特需求。
此外,我们计划全面支持 vLLM v1,预计将混合模型架构迁移到 v1 框架中。这些进展有望释放更多性能提升,并为未来的发展提供更坚实的基础。
结论
MiniMax-M1 的混合架构为下一代大语言模型铺平了道路,在长上下文推理和复杂任务处理方面提供了强大的能力。vLLM 则通过高度优化的内存处理、强大的批处理请求管理和深度调优的后端性能对其进行了补充。
MiniMax-M1 和 vLLM 的结合为高效、可扩展的人工智能应用奠定了坚实的基础。随着生态系统的发展,我们期待这种协同作用将在代码生成、文档分析和对话式人工智能等广泛用例中,催生出更智能、响应更快、能力更强的解决方案。
致谢
我们衷心感谢 vLLM 社区提供的宝贵支持与合作。我们特别感谢 Tyler Michael Smith、Simon Mo、Cyrus Leung、Roger Wang、Zifeng Mo 和 Kaichao You 做出的重要贡献。我们同样感谢 MiniMax 工程团队的努力,特别是 Gangying Qing、Jun Qing 和 Jiaren Cai,他们的奉献使这项工作成为可能。