vLLM v0.6.0:吞吐量提升 2.7 倍,延迟降低 5 倍
概括: vLLM 在 Llama 8B 模型上实现了 2.7 倍的吞吐量提升和 5 倍的 TPOT(每输出令牌时间)加速,在 Llama 70B 模型上实现了 1.8 倍的吞吐量提升和 2 倍的 TPOT 降低。
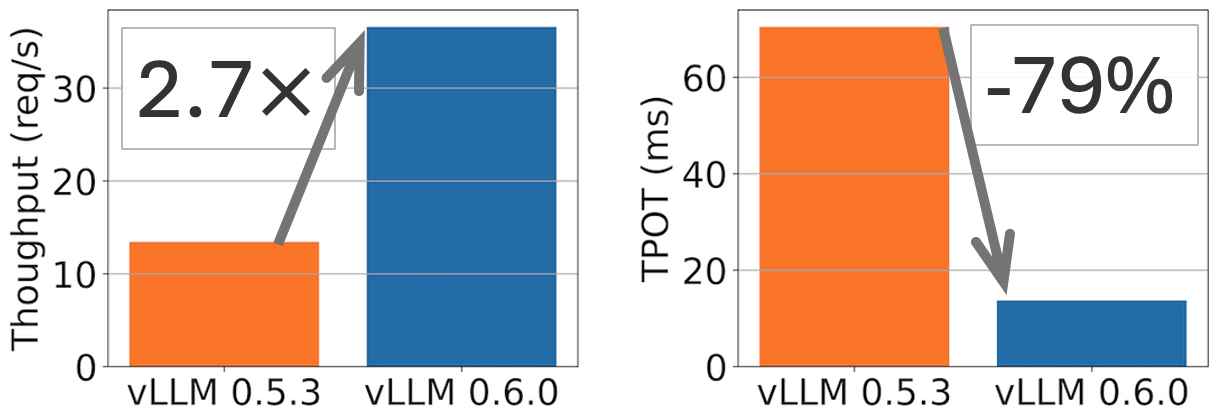
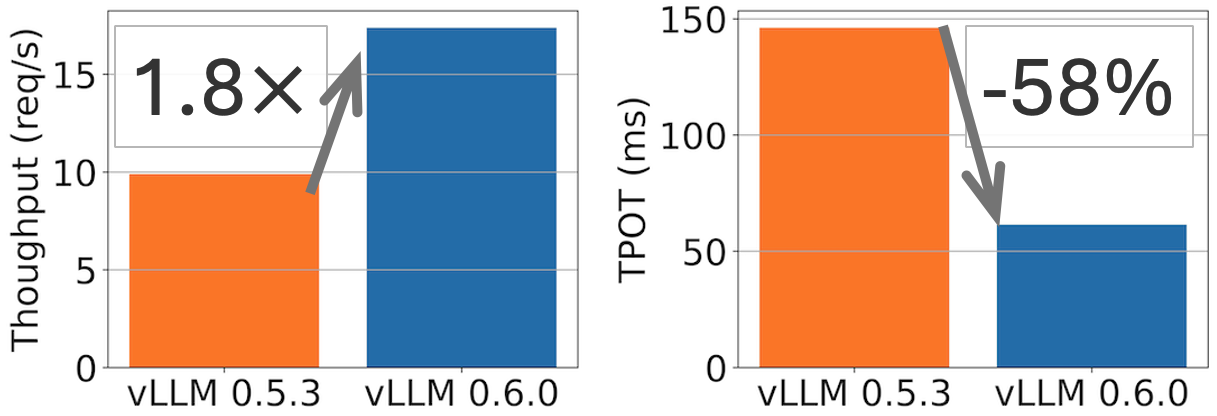
vLLM v0.5.3 和 v0.6.0 在 ShareGPT 数据集(500 个提示)上,Llama 8B 模型于 1xH100 和 70B 模型于 4xH100 的性能比较。TPOT 在 32 QPS 下测量。
一个月前,我们发布了性能路线图,承诺将性能作为我们的首要任务。今天,我们发布了 vLLM v0.6.0,与 v0.5.3 相比,吞吐量提高了 1.8-2.7 倍,在保持丰富功能和出色可用性的同时,达到了最先进的性能。
我们将首先诊断之前 vLLM 中的性能瓶颈。然后,我们将描述我们在过去一个月中实施和落地的解决方案。最后,我们将展示最新 vLLM 版本 v0.6.0 和其他推理引擎的基准测试。
性能诊断
LLM 推理需要 CPU 和 GPU 之间的紧密协作。尽管主要的计算发生在 GPU 中,但 CPU 在服务和调度请求方面也发挥着重要作用。如果 CPU 调度速度不够快,GPU 将闲置等待 CPU,这最终会导致 GPU 利用率低下并阻碍推理性能。
一年前,当 vLLM 首次发布时,我们主要针对内存有限的 GPU 上的相对大型模型进行优化(例如 NVIDIA A100-40G 上的 Llama 13B)。随着具有更大内存的更快 GPU(如 NVIDIA H100)变得更加普及,并且模型针对推理进行了更多优化(例如,采用 GQA 和量化等技术),推理引擎其他 CPU 部分所花费的时间成为了一个重要的瓶颈。具体来说,我们的性能分析结果表明,对于在 1 个 H100 GPU 上运行的 Llama 3 8B 模型:
- HTTP API 服务器占总执行时间的 33%。
- 总执行时间的 29% 花费在调度上,包括收集上一步的 LLM 结果,调度请求以运行下一步,以及准备这些请求作为 LLM 的输入。
- 最后,只有 38% 的时间用于 LLM 的实际 GPU 执行。
我们通过以上基准测试发现了 vLLM 中的两个主要问题:
- CPU 开销过高。 vLLM 的 CPU 组件花费了惊人的长时间。为了使 vLLM 的代码易于理解和贡献,我们将 vLLM 的大部分代码保留在 Python 中,并使用了许多 Python 原生数据结构(例如,Python 列表和字典)。这变成了一个显著的开销,导致调度和数据准备时间过长。
- 不同组件之间缺乏异步性。 在 vLLM 中,许多组件(例如,调度器和输出处理器)以同步方式执行,从而阻塞 GPU 执行。这主要是由于 1) 我们最初假设模型执行速度会比 CPU 部分慢得多,以及 2) 许多复杂的调度情况(例如,束搜索调度)易于实现。然而,这个问题导致 GPU 等待 CPU,从而降低了其利用率。
总而言之,vLLM 的性能瓶颈主要由阻塞 GPU 执行的 CPU 开销引起。在 vLLM v0.6.0 中,我们引入了一系列优化措施,以最大限度地减少这些开销。
性能增强
为了确保我们能够让 GPU 保持繁忙,我们进行了多项增强:
将 API 服务器和推理引擎分离到不同的进程中 (PR #6883)
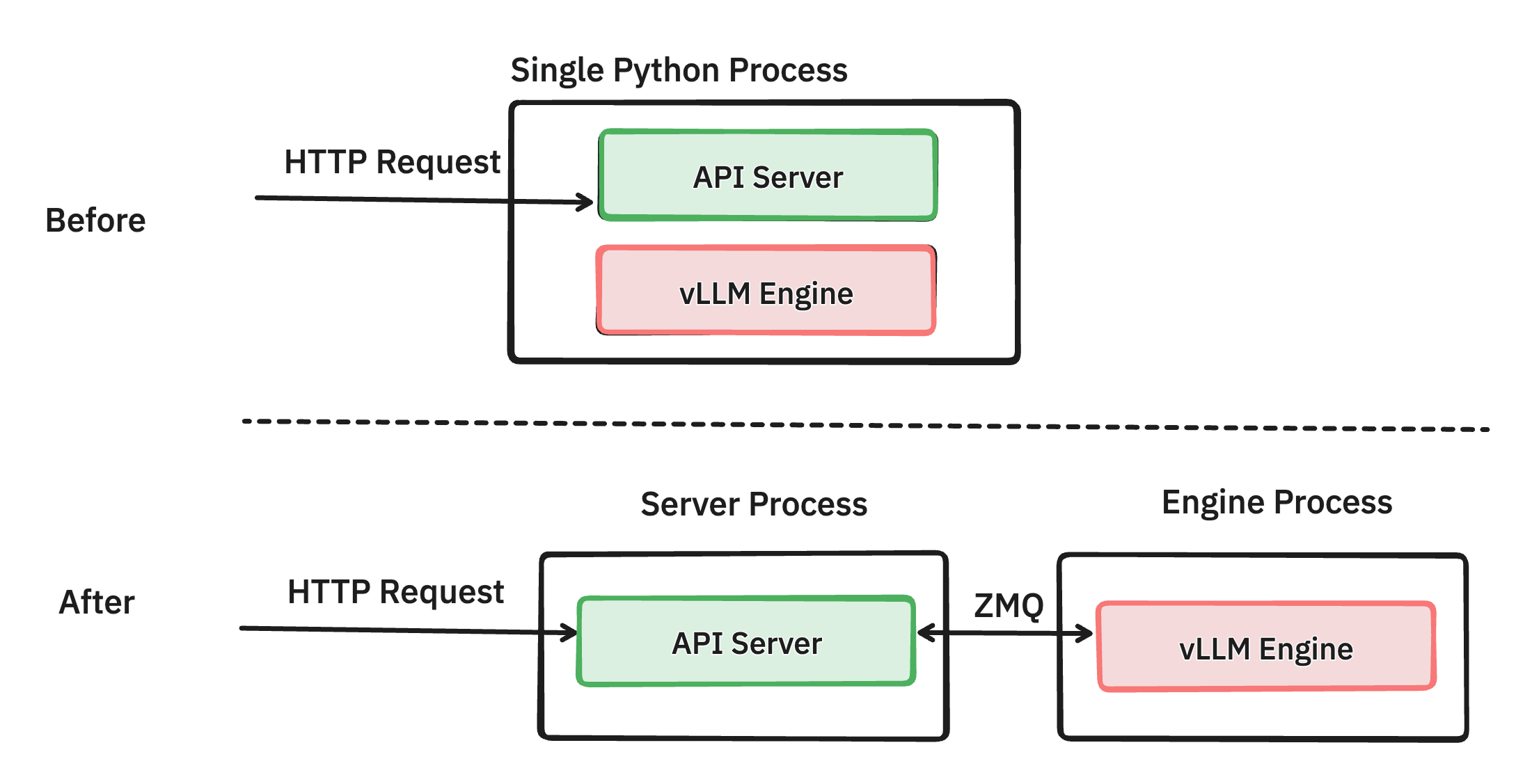
通过仔细的性能分析,我们发现管理网络请求和格式化 OpenAI 协议的响应会消耗相当多的 CPU 周期,尤其是在启用令牌流式传输的高负载下。例如,Llama3 8B 在轻负载下每 13 毫秒可以生成 1 个令牌。这意味着前端需要每秒流回 76 个对象,并且随着数百个并发请求,这种需求进一步增加。这对以前版本的 vLLM 提出了挑战,因为 API 服务器和推理引擎在同一进程中运行。因此,推理引擎和 API 服务器协程必须竞争 Python GIL,导致 CPU 争用。
我们的解决方案是将 API 服务器(处理请求验证、分词和 JSON 格式化)与引擎(管理请求调度和模型推理)分离出来。我们使用低开销的 ZMQ 将这两个 Python 进程连接起来。通过消除 GIL 约束,这两个组件可以更有效地运行,而不会发生 CPU 争用,从而提高了性能。
即使在拆分这两个进程之后,我们发现引擎中如何处理请求以及如何与 http 请求交互方面仍有很大的改进空间。我们正在积极致力于进一步提高 API 服务器的性能 (PR #8157),目标是在不久的将来使其与离线批量推理一样高效。
提前批量调度多个步骤 (PR #7000)
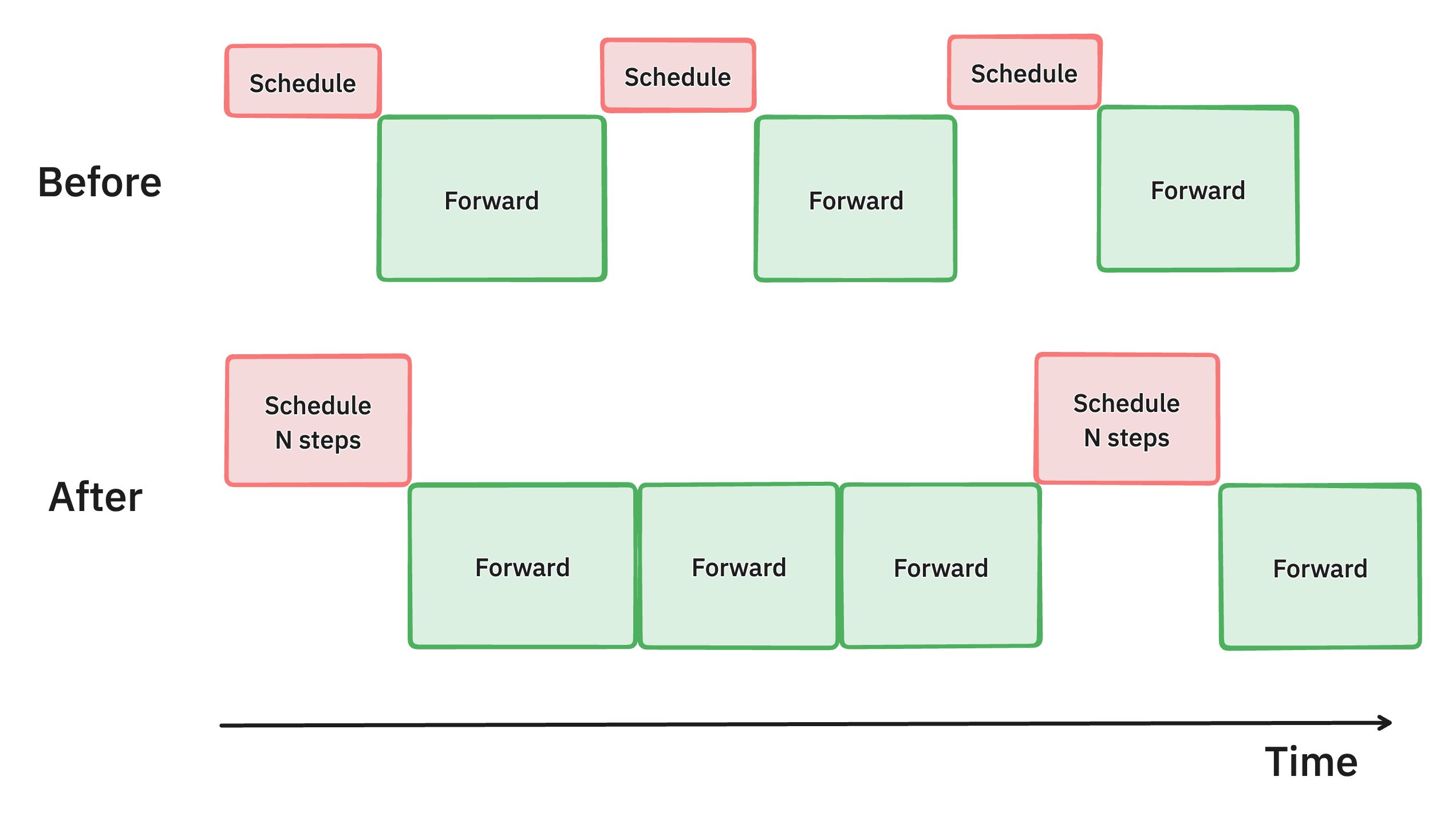
vLLM 中多步调度方法的示意图。通过一次批量处理多个调度步骤,我们使 GPU 比以前更繁忙,从而减少延迟并提高吞吐量。
我们确定,vLLM 调度器和输入准备的 CPU 开销导致 GPU 利用率不足,从而导致吞吐量欠佳。为了解决这个问题,我们引入了多步调度,它执行一次调度和输入准备,并使模型连续运行 n 步。通过确保 GPU 可以在 n 步之间继续处理,而无需等待 CPU,这种方法将 CPU 开销分散到多个步骤中,显著减少了 GPU 空闲时间并提高了整体性能。
这使在 4xH100 上运行 Llama 70B 模型的吞吐量提高了 28%。
异步输出处理 (PR #7049, #7921, #8050)
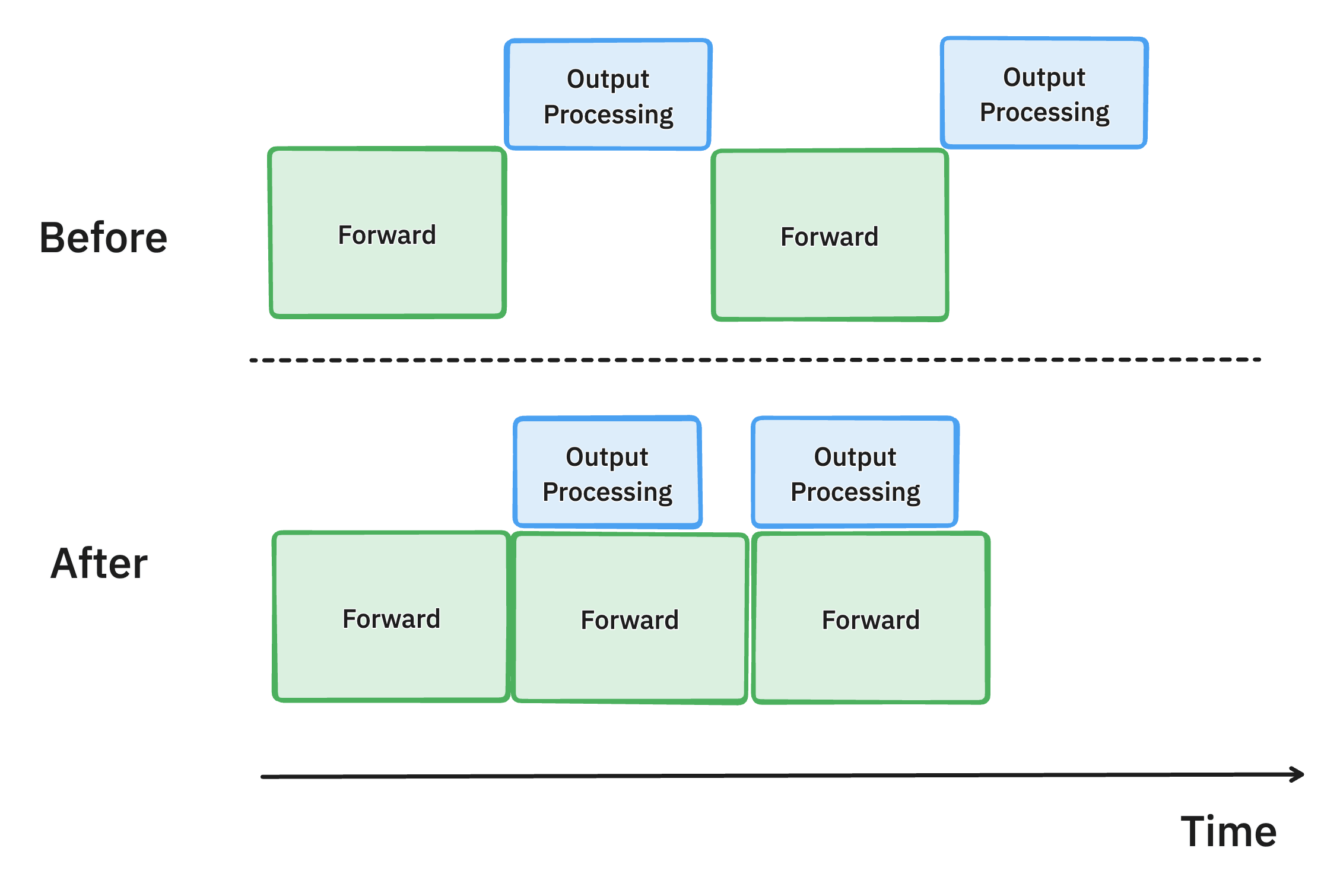
vLLM 中异步输出处理的示意图。通过将输出数据结构处理的 CPU 工作与 GPU 计算重叠,我们减少了 GPU 空闲时间并提高了吞吐量。
为了继续努力最大限度地提高 GPU 利用率,我们还改进了 vLLM 中模型输出的处理方式。
以前,在生成每个令牌后,vLLM 会将模型输出从 GPU 移动到 CPU,检查停止条件以确定请求是否已完成,然后执行下一步。这种输出处理通常很慢,涉及对生成的令牌 ID 进行反分词和执行字符串匹配,并且开销随着批处理大小的增加而增加。
为了解决这种低效率问题,我们引入了异步输出处理,它将输出处理与模型执行重叠。现在,vLLM 不会立即处理输出,而是延迟它,在执行第 n+1 步时处理第 n 步输出的处理。这种方法假设第 n 步中的任何请求都没有满足停止条件,从而导致每个请求额外执行一步的轻微开销。然而,GPU 利用率的显著提高弥补了这一成本,从而提高了整体性能。
这使在 4xH100 上运行 Llama 70B 模型的每输出令牌时间缩短了 8.7%。
其他优化
为了进一步降低 CPU 开销,我们仔细检查了整个代码库,并执行了以下优化:
- 随着请求的到来和完成,Python 将不断分配新对象并再次释放它们。为了减轻这种开销,我们创建了一个对象缓存 (#7162) 来保存这些对象,这显著提高了 24% 的端到端吞吐量。
- 当从 CPU 向 GPU 发送数据时,我们尽可能使用非阻塞操作 (#7172)。CPU 可以启动许多复制操作,而 GPU 正在复制数据。
- vLLM 支持多种注意力后端和采样算法。对于具有简单采样请求的常用工作负载 (#7117),我们引入了一条快速代码路径,跳过了复杂的步骤。
在过去的一个月里,vLLM 社区为这些优化付出了许多努力。我们将继续优化代码库以提高效率。
性能基准测试
通过以上努力,我们很高兴分享 vLLM 的性能与上个月的 vLLM 相比有了很大提高。根据我们的性能基准测试,它达到了最先进的性能。
服务引擎。 我们将 vLLM v0.6.0 与 TensorRT-LLM r24.07、SGLang v0.3.0 和 lmdeploy v0.6.0a0 进行了基准测试。对于其他基准测试,我们使用它们的默认设置。对于 vLLM,我们通过设置 --num-scheduler-steps 10 启用了多步调度。我们正在积极努力使其成为默认设置。
数据集。 我们使用以下三个数据集对不同的服务引擎进行基准测试:
- ShareGPT:从 ShareGPT 数据集中随机抽取的 500 个提示,具有固定的随机种子。
- 平均输入令牌数:202,平均输出令牌数:179
- 预填充密集型数据集:从 sonnet 数据集中合成生成的 500 个提示,平均约有 462 个输入令牌和 16 个输出令牌。
- 解码密集型数据集:从 sonnet 数据集中合成生成的 500 个提示,平均约有相同数量的 462 个输入令牌和 256 个输出令牌。
模型。 我们在两个模型上进行了基准测试:Llama 3 8B 和 70B。我们没有使用最新的 Llama 3.1 模型,因为带有 TensorRT LLM 后端 v0.11 的 TensorRT-LLM r24.07 不支持它 (问题链接)。
硬件。 我们使用 A100 和 H100 进行基准测试。它们是用于推理的两个主要高端 GPU。
指标。 我们评估以下指标:
- 首个令牌时间 (TTFT,以毫秒为单位测量)。我们在图中显示了均值和均值标准误差。
- 每输出令牌时间 (TPOT,以毫秒为单位测量)。我们在图中显示了均值和均值标准误差。
- 吞吐量 (以每秒请求数衡量)。
- 吞吐量是在 QPS inf (意味着所有请求一次性到达) 下测量的。
基准测试结果
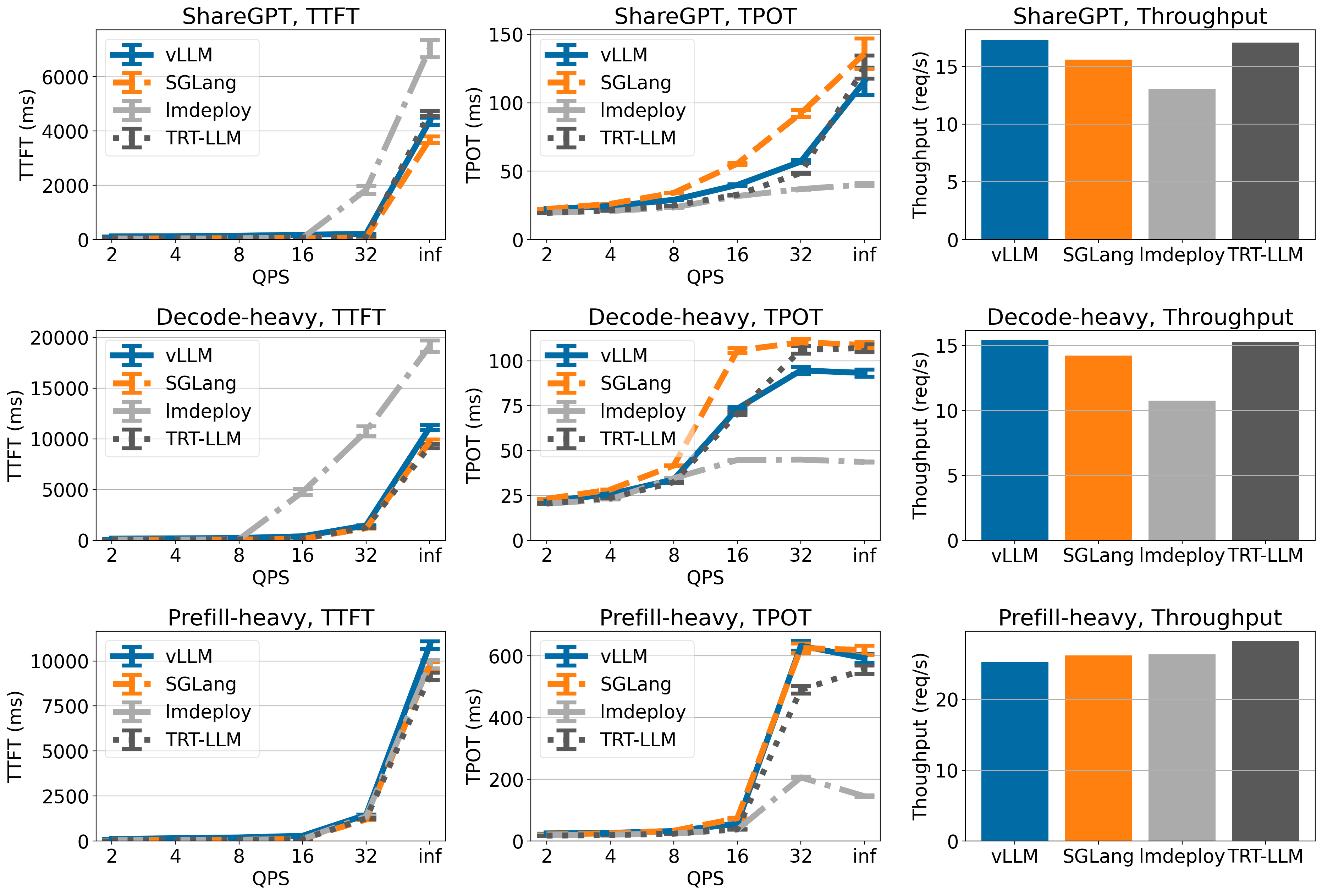
在 ShareGPT 和解码密集型数据集中,当服务 Llama-3 模型时,vLLM 在 H100 上实现了最高的吞吐量。
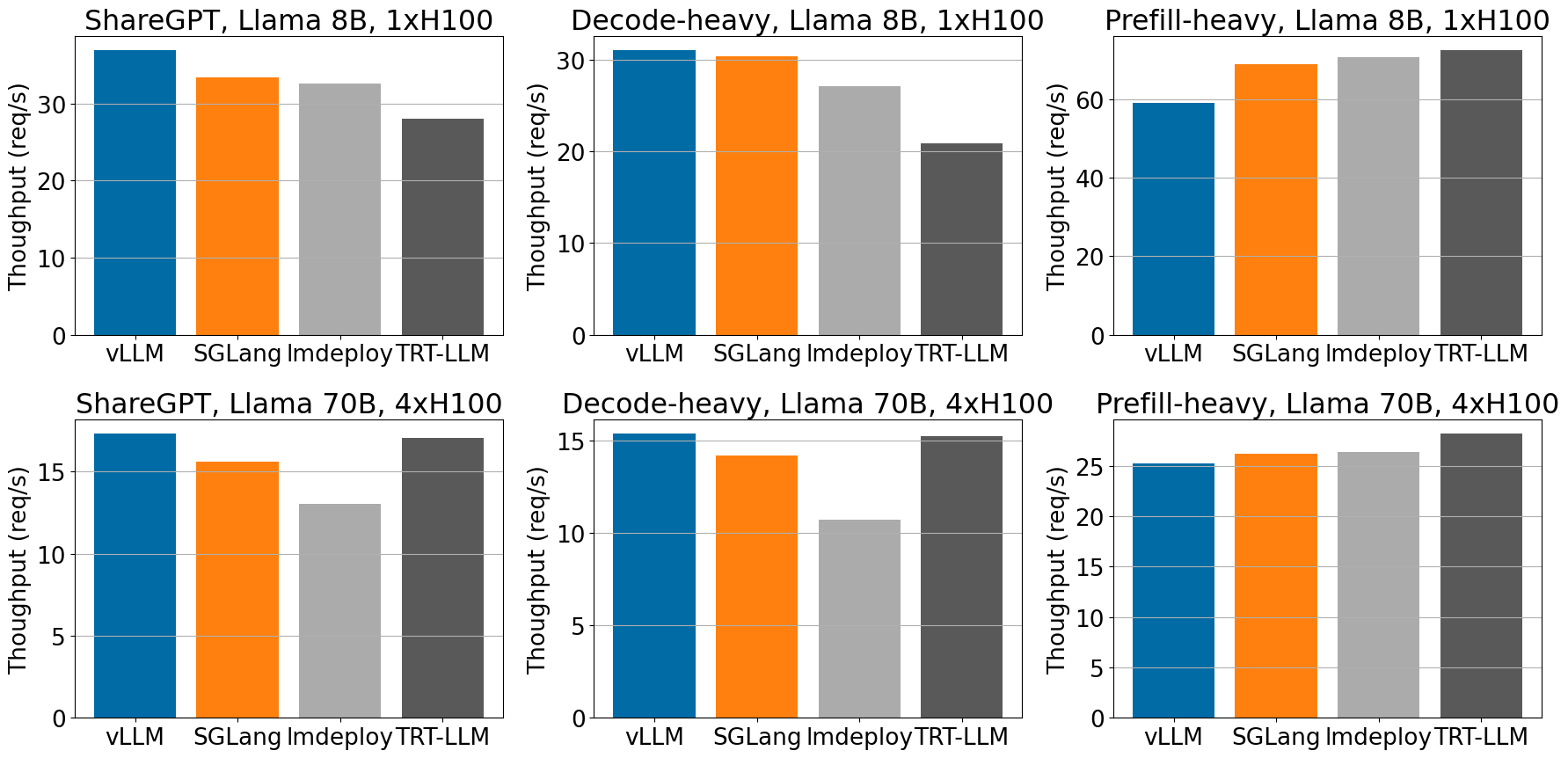
在不同的工作负载中,对于 H100 上的 Llama 8B 和 70B 模型,与其他框架相比,vLLM 实现了高吞吐量。
对于其余的性能基准测试,以及捕获的首个令牌时间 (TTFT) 和每输出令牌时间 (TPOT) 的详细指标,请参阅附录以获取更多数据和分析。您可以关注 此 github issue 来重现我们的基准测试。
当前优化的局限性。 尽管我们当前的优化措施带来了显著的吞吐量提升,但我们当前的优化措施也存在性能权衡,特别是来自多步调度:
- 不稳定的令牌间延迟: 在我们当前的多步调度实现中,我们还在批处理中返回多个步骤的输出令牌。从最终用户的角度来看,他们将收到批量回复的令牌。我们正在通过将中间令牌流式传输回引擎来解决这个问题。
- 在低请求速率下 TTFT 较高: 新请求只能在当前多步执行完成后开始执行。因此,较高的
--num-scheduler-steps将导致在低请求速率下 TTFT 较高。我们的实验侧重于高 QPS 下的排队延迟,因此这种影响在附录的结果中并不显著。
结论与未来工作
在这篇文章中,我们讨论了 vLLM 中的性能增强,这些增强带来了 1.8-2.7 倍的吞吐量提升,并与其他推理引擎相媲美。我们仍然致力于稳步提高性能,同时不断扩展我们的模型覆盖范围、硬件支持和多样化功能。对于本文讨论的功能,我们将继续加强它们以实现生产就绪。
重要的是,我们还将专注于改进 vLLM 的核心,以降低复杂性,从而降低贡献的门槛,并释放更多性能增强。
参与其中
如果您还没有这样做,我们强烈建议您更新 vLLM 版本(请参阅此处的说明)并亲自试用!我们一直很乐意了解更多关于您的用例以及我们如何为您改进 vLLM 的信息。可以通过 vllm-questions@lists.berkeley.edu 联系 vLLM 团队。vLLM 也是一个社区项目,如果您有兴趣参与和贡献,我们欢迎您查看我们的路线图并查看适合新手的问题来解决。通过在 X 上关注我们,随时关注更多更新。
如果您在湾区,您可以在以下活动中与 vLLM 团队会面:vLLM 第六次与 NVIDIA 的聚会 (09/09)、PyTorch 大会 (09/19)、CUDA MODE IRL 聚会 (09/21) 和 Ray Summit 上的首个 vLLM 专题 (10/01-02)。
无论您身在何处,都不要忘记注册参加在线双周 vLLM 办公时间!每两周都会讨论新的主题。下一次将深入探讨性能增强。
致谢
这篇博文由伯克利的 vLLM 团队起草。性能提升来自 vLLM 社区的集体努力:来自 Neural Magic 的 Robert Shaw 和来自 IBM 的 Nick Hill、Joe Runde 领导了 API 服务器重构,来自 UCSD 的 Will Lin 和来自 Anyscale 的 Antoni Baum、Cody Yu 领导了多步调度工作,来自 Databricks 的 Megha Agarwal 和来自 Neural Magic 的 Alexander Matveev 领导了异步输出处理,以及来自 vLLM 社区的许多贡献者贡献了各种优化。所有这些努力使我们齐心协力,获得了巨大的性能提升。
附录
我们在本节中包含详细的实验结果。
Llama 3 8B 于 1xA100
在 Llama 3 8B 上,vLLM 在 ShareGPT 和解码密集型数据集上实现了与 TensorRT-LLM 和 SGLang 相当的 TTFT 和 TPOT。与其他引擎相比,LMDeploy 的 TPOT 较低,但 TTFT 总体上较高。在吞吐量方面,TensorRT-LLM 在所有引擎中吞吐量最高,而 vLLM 在 ShareGPT 和解码密集型数据集上吞吐量排名第二。
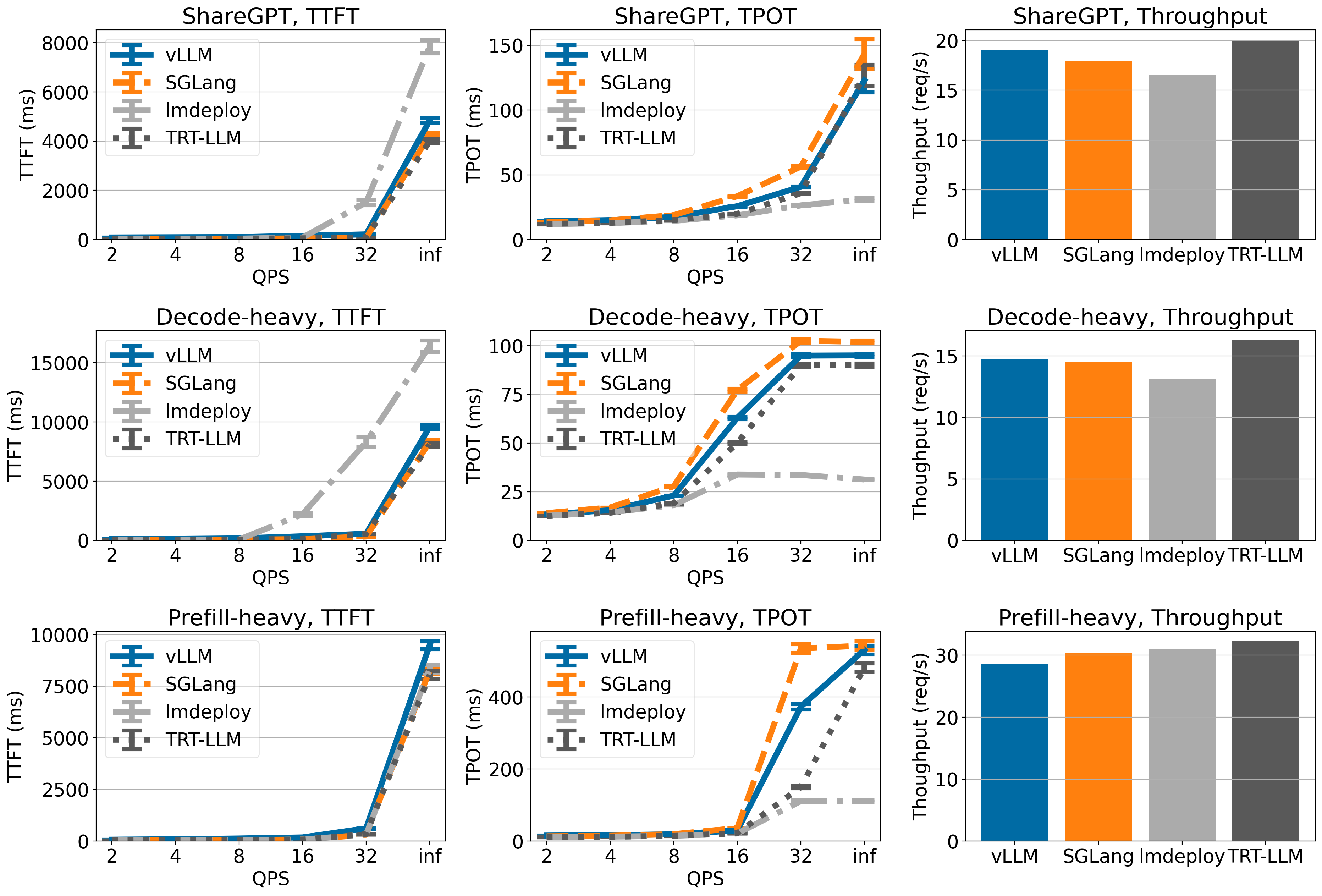
Llama 3 70B 于 4xA100
在 Llama 3 70B 上,vLLM、SGLang 和 TensorRT-LLM 具有相似的 TTFT 和 TPOT(LMDeploy 的 TPOT 较低,但 TTFT 较高)。在吞吐量方面,vLLM 在 ShareGPT 数据集上实现了最高的吞吐量,并且在其他数据集上与其他引擎相比具有相当的吞吐量。
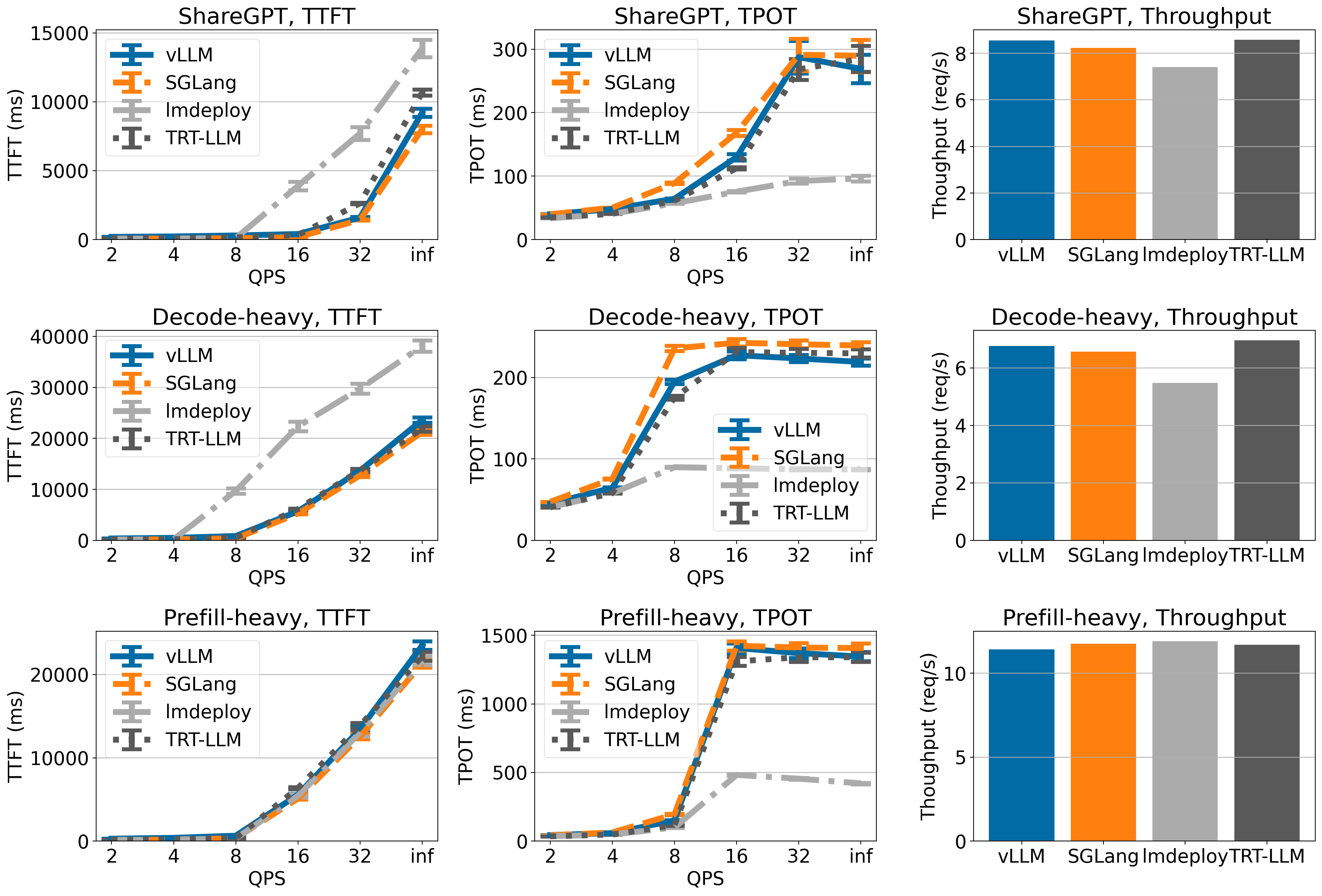
Llama 3 8B 于 1xH100
vLLM 在 ShareGPT 和解码密集型数据集上实现了最先进的吞吐量,尽管在预填充密集型数据集上吞吐量较低。
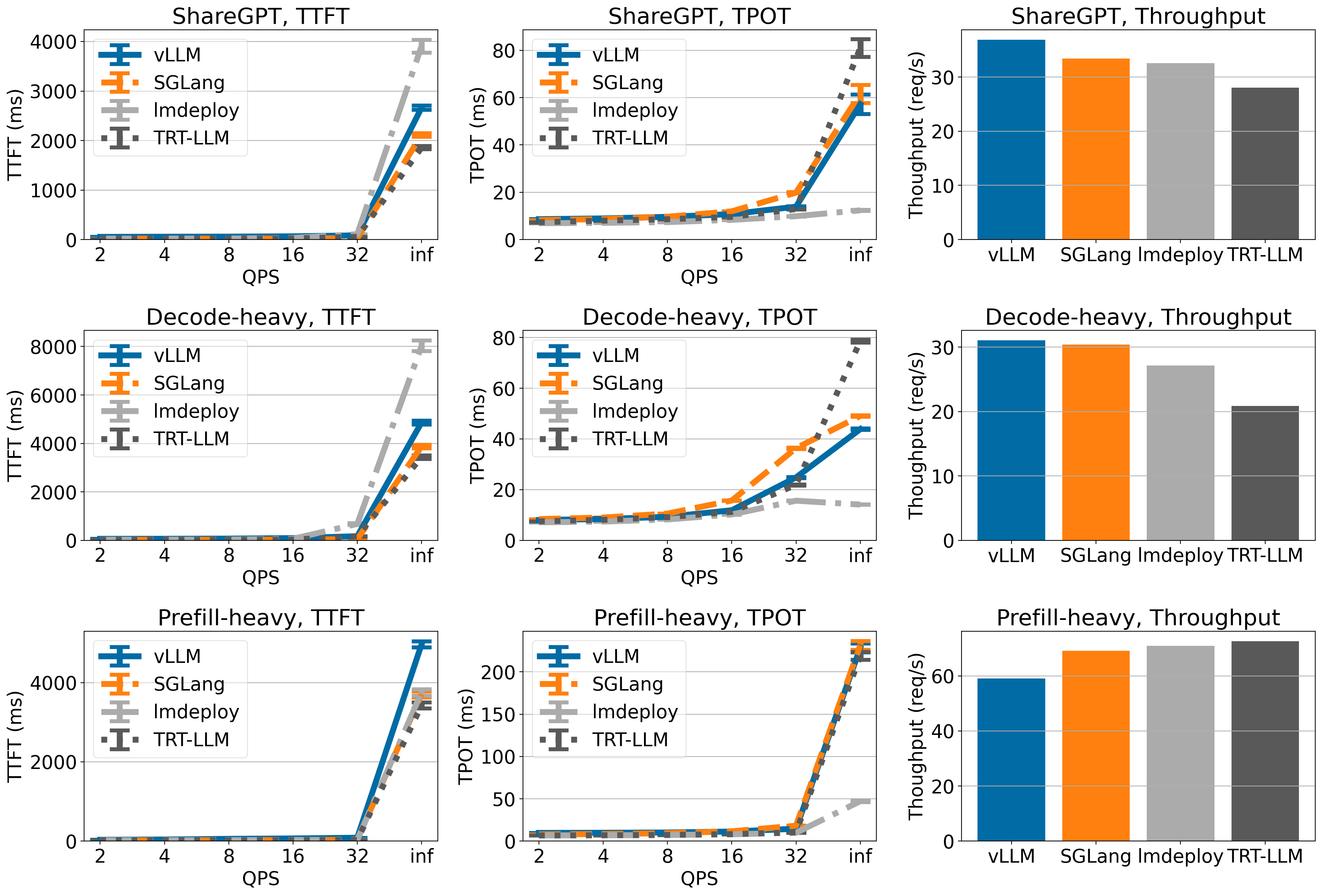
Llama 3 70B 于 4xH100
vLLM 在 ShareGPT 和解码密集型数据集上具有最高的吞吐量(尽管吞吐量仅略高于 TensorRT-LLM),但在预填充密集型数据集上,vLLM 的吞吐量较低。