在 AMD MI300X 上部署 LLM:最佳实践
TL;DR(太长不看版): vLLM 在 AMD MI300X 上释放了惊人的性能,对于 Llama 3.1 405B 模型,吞吐量比 Text Generation Inference (TGI) 高 1.5 倍,首个令牌生成时间 (TTFT) 快 1.7 倍。对于 Llama 3.1 70B 模型,吞吐量比 TGI 高 1.8 倍,TTFT 快 5.1 倍。本指南探讨了 8 个关键的 vLLM 设置,以最大限度地提高效率,向您展示如何利用 AMD 上的开源 LLM 推理能力。如果您只想查看最佳参数,请跳转至快速入门指南。
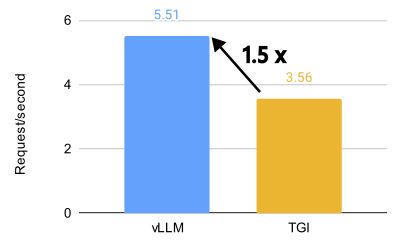
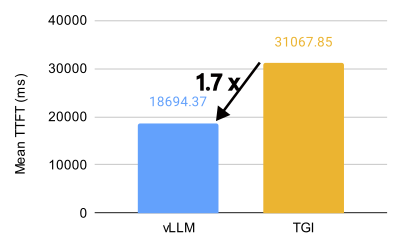
vLLM 与 TGI 在 8 个 MI300X 上对 Llama 3.1 405B 模型的性能比较(BF16,32 QPS)。
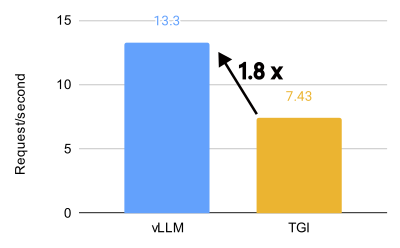
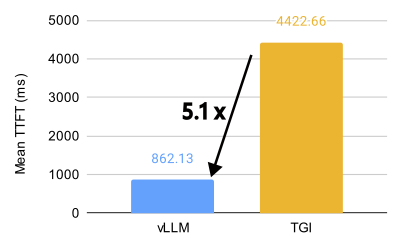
vLLM 与 TGI 在 8 个 MI300X 上对 Llama 3.1 70B 模型的性能比较(BF16,32 QPS)。
简介
Meta 最近宣布,他们正在 AMD MI300X GPU 上运行 100% 的实时 Llama 3.1 405B 模型流量,展示了 AMD 的 ROCm 平台在大型语言模型 (LLM) 推理方面的强大性能和就绪状态。这一令人振奋的消息恰逢 ROCm 6.2 发布,新版本显著改进了对 vLLM 的支持,使得利用 AMD GPU 的强大功能进行 LLM 推理变得比以往任何时候都更容易。
ROCm 是 AMD 对 CUDA 的回应,可能对某些人来说不太熟悉,但它正迅速成熟为一个强大且高性能的替代方案。借助 vLLM,利用这种强大功能比以往任何时候都更容易。我们将向您展示如何操作。
vLLM 与 TGI 对比
vLLM 在 AMD MI300X 上释放了惊人的性能,对于 Llama 3.1 405B 模型,吞吐量比 Text Generation Inference (TGI) 高 1.5 倍,首个令牌生成时间 (TTFT) 快 1.7 倍。对于 Llama 3.1 70B 模型,吞吐量比 TGI 高 1.8 倍,TTFT 快 5.1 倍。
在 Llama 3.1 405B 模型上,在各种每秒查询数 (QPS) 场景中,vLLM 在首个令牌生成时间 (TTFT) 和吞吐量方面都表现出明显优于 TGI 的性能。对于 TTFT,在优化的配置中,16 QPS 下,vLLM 的平均响应时间比 TGI 快约 3.8 倍。在吞吐量方面,vLLM 始终优于 TGI,在优化的设置中,在 1000 QPS 下,ShareGPT 数据集上的最高吞吐量为 5.76 个请求/秒,而 TGI 为 3.55 个请求/秒。
即使在默认配置中,vLLM 也显示出优于 TGI 的性能。例如,在 16 QPS 下,vLLM 的默认配置实现了 4.05 个请求/秒的吞吐量,而 TGI 为 2.58 个请求/秒。这种性能优势在不同的 QPS 水平上都得以保持,突显了 vLLM 在处理大型语言模型推理任务方面的效率。
.png)
.png)
vLLM 与 TGI 在 8 个 MI300X 上对 Llama 3.1 405B 模型的性能比较(BF16,QPS 16、32、1000;命令参见附录)。
如何以最佳性能运行 vLLM
关键设置和配置
我们已经广泛测试了各种 vLLM 设置,以确定 MI300X 的最佳配置。以下是我们所了解到的
- 分块预填充 (Chunked Prefill):经验法则是,在大多数情况下,在 MI300X 上禁用它以获得更好的性能。
- 多步调度 (Multi-Step Scheduling):使用多步调度可以显著提高 GPU 利用率和整体性能。将
--num-scheduler-steps设置为 10 到 15 之间的值,以优化 GPU 利用率和性能。 - 前缀缓存 (Prefix Caching):在特定场景中,将前缀缓存与分块预填充相结合可以提高性能。但是,如果用户请求的前缀缓存命中率较低,则可能建议禁用分块预填充和前缀缓存。
- 图捕获 (Graph Capture):当处理支持长上下文长度的模型时,将
--max-seq-len-to-capture设置为 16384。但是,请注意,增加此值并不总是保证性能提升,有时甚至可能由于次优的 bucket 大小而导致性能下降。 - AMD 特定优化:禁用 NUMA 平衡和调整
NCCL_MIN_NCHANNELS可以进一步提高性能。 - KV 缓存数据类型:为了获得最佳性能,请使用默认的 KV 缓存数据类型,它会自动匹配模型的数据类型。
- 张量并行 (Tensor Parallelism):为了优化吞吐量,请使用可容纳模型权重和上下文的最小张量并行度 (TP),并运行多个 vLLM 实例。为了优化延迟,请将 TP 设置为节点中 GPU 的数量。
- 最大序列数:为了优化性能,请根据 GPU 的内存和计算资源将
--max-num-seqs增加到 512 或更高。这可以显著提高资源利用率和吞吐量,特别是对于处理较短输入和输出的模型。 - 使用 CK Flash Attention:CK Flash Attention 实现比 triton 实现快得多。
详细分析和实验
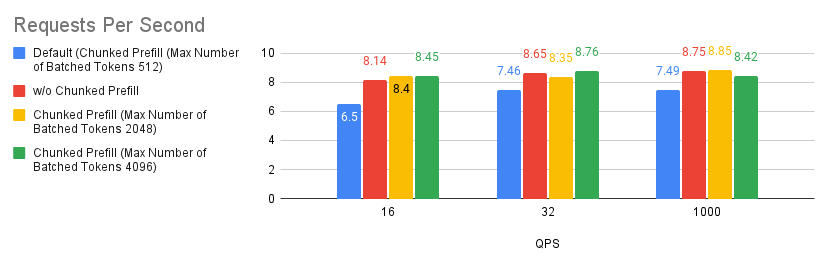
案例 1:分块预填充
分块预填充是 vLLM 中的一项实验性功能,允许将大型预填充请求分成较小的块,并与解码请求一起批量处理。这通过将计算密集型预填充请求与内存密集型解码请求重叠来提高系统效率。您可以通过在 LLM 构造函数中设置 --enable_chunked_prefill=True 或使用 --enable-chunked-prefill 命令行选项来启用它。
根据我们运行的实验,我们发现调整分块预填充值比禁用分块预填充功能略有改进。但是,如果您不确定是否启用分块预填充,只需从禁用它开始,您通常应该期望获得比使用默认设置更好的性能。这仅适用于 MI300X GPU。
.png)
.png)
案例 2:调度器步数
多步调度已在 vLLM v0.6.0 中引入,有望提高 GPU 利用率和整体性能。正如这篇博客文章中详细介绍的那样,这种性能提升背后的魔力在于它能够执行一次调度和输入准备,并连续运行模型多个步骤而不会中断 GPU。通过巧妙地将 CPU 开销分散到这些步骤中,它可以显著减少 GPU 空闲时间并大幅提升性能。
要启用多步调度,请将 --num-scheduler-steps 参数设置为大于 1 的数字,这是默认值(值得一提的是,我们发现使用多步调度可能会随着值的升高而提供递减的回报,因此,我们将上限保持在 15)。

.png)
.png)
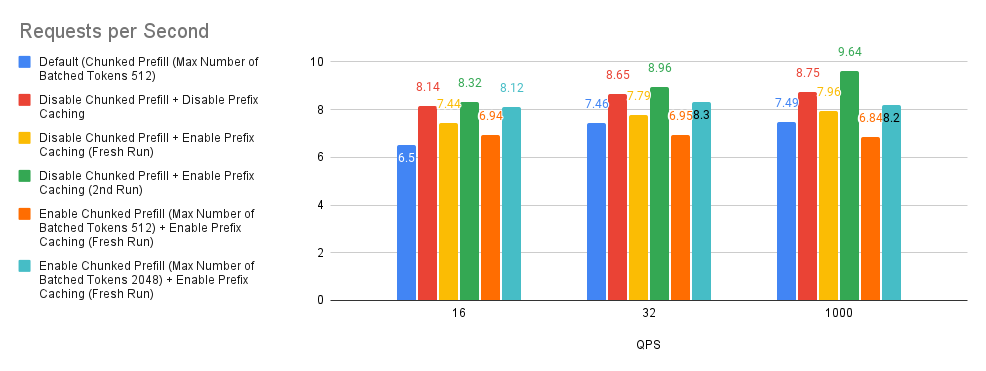
案例 3:分块预填充和前缀缓存
分块预填充和前缀缓存是 vLLM 中的优化技术,它们通过将大型预填充分解为更小的块以实现高效批处理,以及重用跨查询共享前缀的缓存 KV(键值)计算来提高性能。
默认情况下,如果模型的上下文长度超过 32k 个令牌,vLLM 将自动启用分块预填充功能。默认情况下,要分块预填充的最大令牌数设置为 512。
在我们深入研究图表之前,我们将首先尝试解释实验中使用的术语。Fresh Run(全新运行) 指的是前缀缓存内存根本未填充的情况。2nd Run(第二次运行) 指的是在 Fresh Run 之后再次重新运行基准测试脚本。一般来说,当在 2nd Run 上重新运行 ShareGPT 基准数据集时,我们获得大约 50% 的前缀缓存命中率。
查看下面的图表,我们可以对这个实验做出三个观察结果。
- 基于 Bar 2(红色)与基线(蓝色)的比较,性能有巨大提升。
- 基于 Bar 3(黄色)、Bar 5(橙色)和 Bar 6(青色)与基线的比较,分块预填充性能取决于用户请求输入提示长度分布。
- 在我们的实验中,我们发现 Bar 3(黄色)和 Bar 4(绿色)的前缀缓存命中率约为 0.9% 和 50%。基于 Bar 3(黄色)和 Bar 4(绿色)与基线和 Bar 2(红色)的比较,这告诉我们,如果用户请求没有高前缀缓存命中率,则可以考虑禁用分块预填充和前缀缓存,这可能是一个好的经验法则。
.png)
.png)
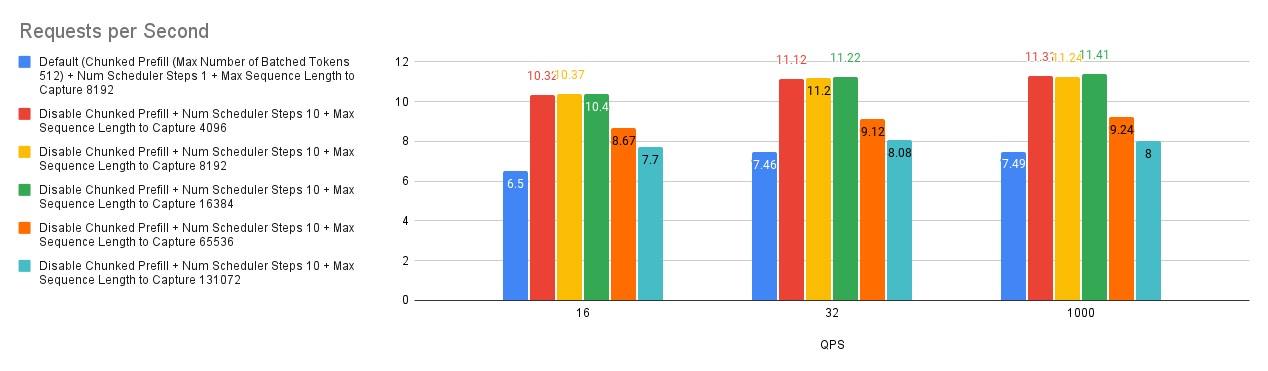
案例 4:最大序列长度捕获
vLLM 中的 --max-seq-len-to-capture 参数控制 CUDA/HIP 图可以处理的最大序列长度,这通过捕获和重放 GPU 操作来优化性能。如果序列超过此长度,系统将恢复为 eager 模式,逐个执行操作,这可能效率较低。这适用于常规模型和编码器-解码器模型。
我们的基准测试揭示了一个有趣的趋势:增加 --max-seq-len-to-capture 并不总是能提高性能,有时甚至会降低性能。这可能是由于 vLLM 如何为不同的序列长度创建 bucket。
原因如下
- Bucketing(分桶):vLLM 使用 bucket 对相似长度的序列进行分组,从而优化每个 bucket 的图捕获。
- Optimal Buckets(最佳 Bucket):最初,bucket 是细粒度的(例如,[4, 8, 12,…, 2048, 4096]),从而允许对各种序列长度进行有效的图捕获。
- Coarser Buckets(更粗糙的 Bucket):增加
--max-seq-len-to-capture可能会导致更粗糙的 bucket(例如,[4, 8, 12, 2048, 8192])。 - Performance Impact(性能影响):当输入序列落入这些更大、精度较低的 bucket 中时,捕获的 CUDA/HIP 图可能不是最优的,这可能会导致性能下降。
因此,虽然使用 CUDA/HIP 图捕获更长的序列看起来是有益的,但至关重要的是要考虑对 bucketing 和整体性能的潜在影响。找到最佳的 --max-seq-len-to-capture 值可能需要进行实验,以平衡图捕获效率与适用于您的特定工作负载的适当 bucket 大小。
.png)
.png)
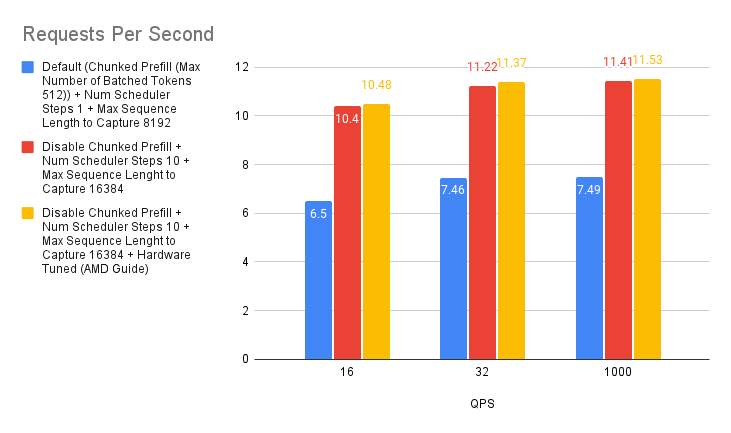
案例 5:AMD 推荐的环境变量
为了进一步优化 vLLM 在 AMD MI300X 上的性能,我们可以利用 AMD 特定的环境变量。
- 禁用 NUMA 平衡:非统一内存访问 (NUMA) 平衡有时会阻碍 GPU 性能。正如 AMD MAD 仓库中建议的那样,禁用它可以防止潜在的 GPU 挂起并提高整体效率。可以使用以下命令实现此目的
# disable automatic NUMA balancing sh -c 'echo 0 > /proc/sys/kernel/numa_balancing' # check if NUMA balancing is disabled (returns 0 if disabled) cat /proc/sys/kernel/numa_balancing 0 - 调整 NCCL 通信:NVIDIA Collective Communications Library (NCCL) 用于 GPU 间通信。对于 MI300X,AMD vLLM 分支性能文档建议将
NCCL_MIN_NCHANNELS环境变量设置为 112,以潜在地提高性能。
在我们的测试中,启用这两个配置产生了轻微的性能提升。这与 “NanoFlow: Towards Optimal Large Language Model Serving Throughput” 论文中的发现一致,该论文表明,虽然优化网络通信是有益的,但由于 LLM 推理主要由计算密集型和内存密集型操作主导,因此影响可能有限。
即使收益可能很小,微调这些环境变量也有助于从您的 AMD 系统中榨取最大性能。
.png)
.png)
案例 6:KVCache 类型 Auto/FP8
默认情况下,vLLM 将自动分配与模型数据类型匹配的 KV 缓存类型。但是,vLLM 也支持 MI300X 上的原生 FP8,我们可以利用它来减少 KVCache 的内存需求,从而增加模型的可部署上下文长度。
我们通过使用 Auto KVCache 类型和 KV 缓存类型 FP8 进行实验,并将其与默认基线进行比较。我们可以从下图看到,使用 Auto KVCache 类型(红色)比使用设置为 FP8 的 KV 缓存类型(黄色)实现了更高的每秒请求数。理论上,这可能是由于 Llama-3.1-70B-Instruct (bfloat16) 模型中的量化开销造成的,但由于开销成本似乎很小,因此在某些情况下,为了获得 KVCache 需求的巨大减少,这仍然可能是一个很好的权衡。

.png)
.png)
案例 7:TP 4 和 TP 8 之间的性能差异
张量并行是一种用于分配大型模型计算负载的技术。它的工作原理是将单个张量拆分到多个设备上,从而允许并行处理特定操作或层。这种方法减少了模型的内存占用,并实现了跨多个 GPU 的扩展。
虽然增加张量并行度可以通过提供更多计算资源来提高性能,但收益并不总是线性的。这是因为随着更多设备的参与,通信开销会增加,而每个 GPU 上的工作负载会减少。考虑到 MI300X 的强大处理能力,每个 GPU 较小的工作负载实际上可能导致利用率不足,进一步阻碍性能扩展。
因此,当优化吞吐量时,我们建议启动多个 vLLM 实例,而不是激进地增加张量并行度。这种方法往往会产生更线性的性能提升。但是,如果最小化延迟是首要任务,则增加张量并行度可能是更有效的策略。
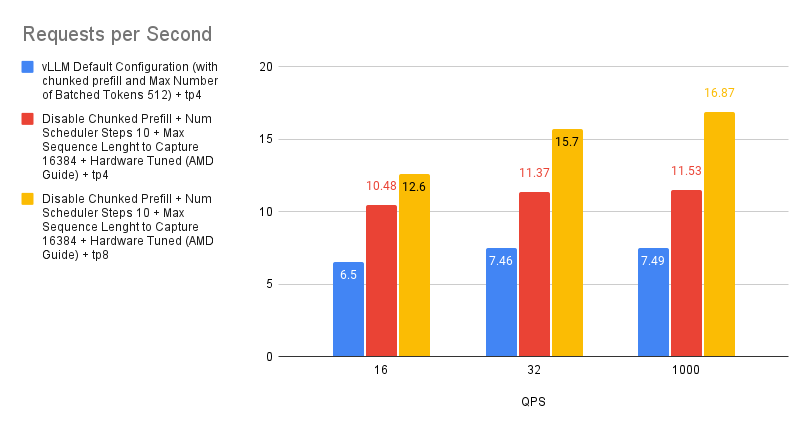
.png)
.png)
案例 8:最大(并行)序列数的影响
--max-num-seqs 参数指定每次迭代可以处理的最大序列数。此参数控制批处理中并发请求的数量,从而影响内存使用和性能。在 ShareGPT 基准测试中,由于样本的输入和输出长度较短,因此托管在 MI300X 上的 Llama-3.1-70B-Instruct 可以在每次迭代中处理大量请求。在我们的实验中,即使 --max-num-seqs 设置为 1024,--max-num-seqs 仍然是一个限制因素。
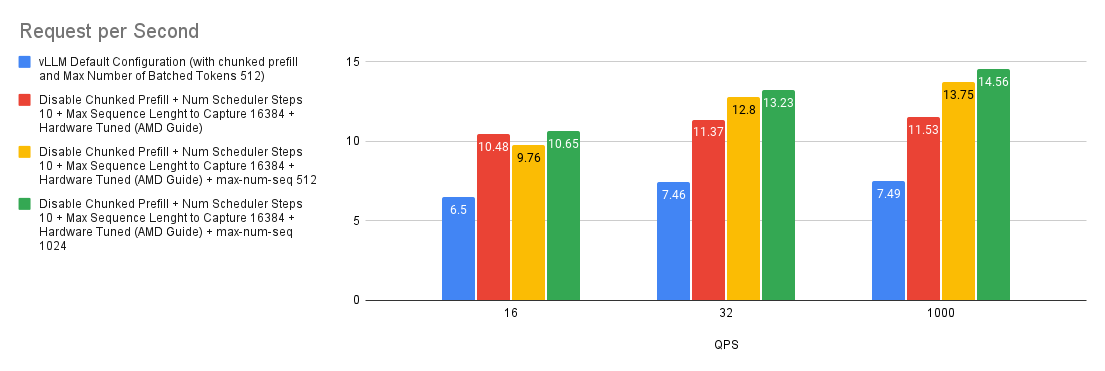
.png)
.png)
快速入门指南
如果您不确定部署设置和用户请求的分布,您可以
- 使用 CK Flash Attention*(虽然我们在此处没有展示,但 CK Flash Attention 实现比 triton 对应实现快得多)
export VLLM_USE_TRITON_FLASH_ATTN=0
- 禁用分块预填充
--enable-chunked-prefill=False - 禁用前缀缓存
- 如果模型支持长上下文长度,请将
--max-seq-len-to-capture设置为 16384 - 将
--num-scheduler-steps设置为 10 或 15。 - 设置 AMD 环境
sh -c 'echo 0 > /proc/sys/kernel/numa_balancing'export NCCL_MIN_NCHANNELS=112
- 将
--max-num-seqs增加到 512 及以上,具体取决于 GPU 的内存和计算资源。
VLLM_USE_TRITON_FLASH_ATTN=0 vllm serve meta-llama/Llama-3.1-70B-Instruct --host 0.0.0.0 --port 8000 -tp 4 --max-num-seqs 1024 --max-seq-len-to-capture 16384 --served-model-name meta-llama/Llama-3.1-70B-Instruct --enable-chunked-prefill=False --num-scheduler-steps 15 --max-num-seqs 1024
为了快速设置,我们已将 vLLM 0.6.2(commit:cb3b2b9ba4a95c413a879e30e2b8674187519a93)的 Docker 镜像编译到 Github Container Registry。要获取下载镜像
# v0.6.2 post
docker pull ghcr.io/embeddedllm/vllm-rocm:cb3b2b9
# P.S. We also have compiled the image for v0.6.3.post1 at commit 717a5f8
docker pull ghcr.io/embeddedllm/vllm-rocm:v0.6.3.post1-717a5f8
要使用镜像启动 docker 容器,请运行
sudo docker run -it \
--network=host \
--group-add=video \
--ipc=host \
--cap-add=SYS_PTRACE \
--security-opt seccomp=unconfined \
--device /dev/kfd \
--device /dev/dri \
-v /path/to/hfmodels:/app/model \ # if you have pre-downloaded the model weight, else ignore
ghcr.io/embeddedllm/vllm-rocm:cb3b2b9 \
bash
现在使用我们找到的参数启动 LLM 服务器
VLLM_USE_TRITON_FLASH_ATTN=0 vllm serve meta-llama/Llama-3.1-70B-Instruct --host 0.0.0.0 --port 8000 -tp 4 --max-num-seqs 1024 --max-seq-len-to-capture 16384 --served-model-name meta-llama/Llama-3.1-70B-Instruct --enable-chunked-prefill=False --num-scheduler-steps 15 --max-num-seqs 1024
结论
本指南探讨了 vLLM 在 AMD MI300X GPU 上部署大型语言模型的强大功能。通过细致地调整分块预填充、多步调度和 CUDA 图捕获等关键设置,我们展示了如何实现相对于标准配置和替代服务解决方案的显著性能提升。vLLM 释放了显著更高的吞吐量和更快的响应时间,使其成为在 AMD 硬件上部署 LLM 的理想选择。
但是,重要的是要承认我们的探索主要集中在具有短输入和输出的通用聊天机器人使用上。还需要进一步研究以优化 vLLM 用于特定用例,如摘要或长篇内容生成。此外,深入研究 Triton 和 CK attention 内核之间的性能差异可能会产生进一步的见解。
我们还要感谢 Leonard Lin 的 这篇精彩的博客文章,它介绍了如何进一步优化 vLLM for MI300X,包括 hipBLAS vs hipBLASLt、CK Flash Attention vs Triton Flash Attention、张量并行 vs 流水线并行等。
致谢
本博客文章由 Embedded LLM 团队起草,感谢 Hot Aisle Inc. 赞助 MI300X 用于 vLLM 基准测试。
附录
服务器规格
以下是惊人的 Hot Aisle 服务器的配置
- CPU:2 个 Intel Xeon Platinum 8470
- GPU:8 个 AMD Instinct MI300X 加速器 我们在基准测试中使用的模型和软件如下
- 模型:meta-llama/Llama-3.1-405B-Instruct 和 meta-llama/Llama-3.1-70B-Instruct
- vLLM (v0.6.2):vllm-project/vllm:用于 LLM 的高吞吐量和内存高效的推理和服务引擎 (github.com) commit: cb3b2b9ba4a95c413a879e30e2b8674187519a93
- 数据集:ShareGPT
- 基准测试脚本:存储库中的 benchmarks/benchmark_serving.py
我们已经从存储库中的 Dockerfile.rocm 构建了 ROCm 兼容的 vLLM docker(我们已经推送了我们用于运行基准测试的 vLLM 版本的 docker 镜像。通过 docker pull ghcr.io/embeddedllm/vllm-rocm:cb3b2b9 获取它)。所有基准测试都在 docker 容器实例中运行,并使用 4 个 MI300X GPU 和 CK Flash Attention 运行,VLLM_USE_TRITON_FLASH_ATTN=0.
详细基准测试配置
| 配置 | 命令 |
|---|---|
| vLLM 默认配置 | VLLM_RPC_TIMEOUT=30000 VLLM_USE_TRITON_FLASH_ATTN=0 vllm serve Llama-3.1-405B-Instruct -tp 8 --max-num-seqs 1024 --max-num-batched-tokens 1024 |
| TGI 默认配置 | ROCM_USE_FLASH_ATTN_V2_TRITON=false TRUST_REMOTE_CODE=true text-generation-launcher --num-shard 8 --sharded true --max-concurrent-requests 1024 --model-id Llama-3.1-405B-Instruct |
| vLLM(本指南) | VLLM_RPC_TIMEOUT=30000 VLLM_USE_TRITON_FLASH_ATTN=0 vllm serve Llama-3.1-405B-Instruct -tp 8 --max-seq-len-to-capture 16384 --enable-chunked-prefill=False --num-scheduler-steps 15 --max-num-seqs 1024 |
| TGI(本指南) | ROCM_USE_FLASH_ATTN_V2_TRITON=false TRUST_REMOTE_CODE=true text-generation-launcher --num-shard 8 --sharded true --max-concurrent-requests 1024 --max-total-tokens 131072 --max-input-tokens 131000 --model-id Llama-3.1-405B-Instruct |