编码器解耦:用于可扩展多模态模型服务的
动机:为什么要在大型多模态模型服务中解耦编码器?
现代大型多模态模型(LMMs)引入了一个独特的服务时瓶颈:在任何文本生成开始之前,所有图像都必须由视觉编码器(例如 ViT)处理。这个编码器阶段的计算特性与文本预填充和解码截然不同。在同一个GPU 实例上运行编码器 + 预填充 + 解码——这是目前常见的方法——会造成根本性的低效率。
编码器与文本生成共存的问题
1. 编码器-预填充-解码干扰
当前管线 (E+PD 在同一个 GPU 上)
[E PD] -> [E PD] -> [E PD]- 所有请求都必须完成两个阶段才能继续下一个。
- 编码器工作不能与其它请求的预填充/解码重叠。
影响
- 编码器速度慢且不固定(取决于分辨率、图像数量、复杂性)。
- 当与纯文本请求混合时,单个 LMM 输入可能会使整个批次停滞。
- 预填充和流式解码延迟变得不稳定和不可预测。
- 计算密集型编码器和内存密集型解码必须共享相同的硬件和并行策略,这对两者来说都是次优的。
2. 耦合且低效的资源分配
三个阶段有不同的最优配置文件
- 编码器:一次性、计算密集型、高度并行。
- 预填充:高内存带宽、大型 GEMM 运算。
- 解码:严重内存密集型、长时、顺序。
共存强制在所有阶段采用一种并行方案和一种资源比率,这意味着
- 您无法在不过度配置文本生成 GPU 的情况下扩展编码器吞吐量。
- 偶尔的多模态请求会产生过高的成本和低效率。
解决方案:编码器解耦
将视觉编码器分离成独立的、可扩展的服务,将带来显著的优势。
1. 流水线执行并消除干扰
通过解耦
E → P D (Request 1)
......E → P D (Request 2)
..........E → P D (Request 3)
- 请求 N 的编码器可以在请求 N-1 正在预填充或解码时运行。
- 纯文本请求完全绕过编码器,永远不会等待图像作业。
- 这消除了编码器引起的排队延迟。
- 系统变为流水线并行,提高了吞吐量并平滑了延迟。
2. 独立、细粒度扩展
每个阶段最终可以根据自身需求曲线进行扩展
- 根据多模态图像量扩展编码器 GPU。
- 根据总请求率和输出长度扩展预填充/解码 GPU。
这可以防止浪费
- 不再需要仅仅为了处理罕见的图像峰值而购买大型解码集群。
- 每个池都使用正确的硬件和并行策略。
3. 编码器输出缓存和重用
集中式编码器服务自然支持跨请求缓存
- 常用图像(例如徽标、图表、产品照片)的嵌入只需计算一次,并在不同用户/请求之间重复使用。
- 缓存请求的编码器成本为零,直接减少了 TTFT(首个令牌生成时间)。
- 随着缓存命中率的提高,编码器负载显著降低。
设计
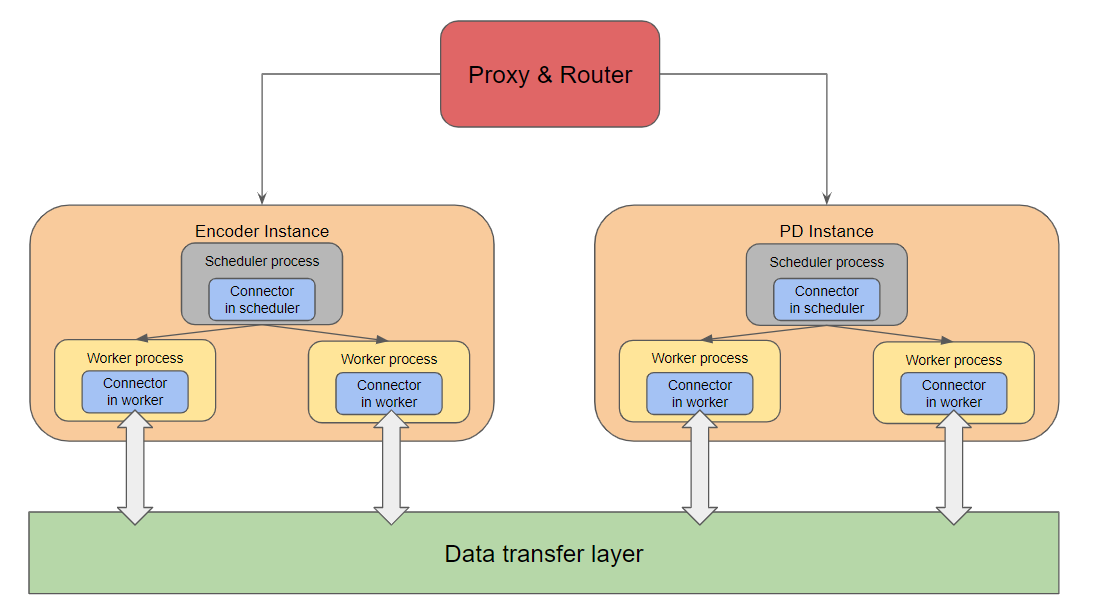
组件
代理与路由器
- 编排请求流。
- 将多模态 (MM) 输入发送到编码器实例。
- 等待编码器完成,然后将原始请求(图像嵌入现在可在远程存储中获取)转发到预填充/解码 (PD) 实例。
数据传输层
- 用于编码器生成的多模态嵌入(编码器缓存,或 EC,嵌入)的远程存储。
- 作为编码器工作器和 PD 工作器之间的共享传输介质。
EC 连接器
- 工作器/调度器与数据传输层之间的桥梁。
- 处理编码器缓存的存储和检索。
角色
- 调度器端连接器:
- 确定在当前调度迭代中应加载或保存哪些多媒体嵌入。
- 生成描述下游工作器所需缓存操作的元数据。
- 工作器端连接器:
- 执行实际的加载/保存操作(读/写远程存储)。
- 管理每个工作器的运行时嵌入传输。
工作流程
数据流图
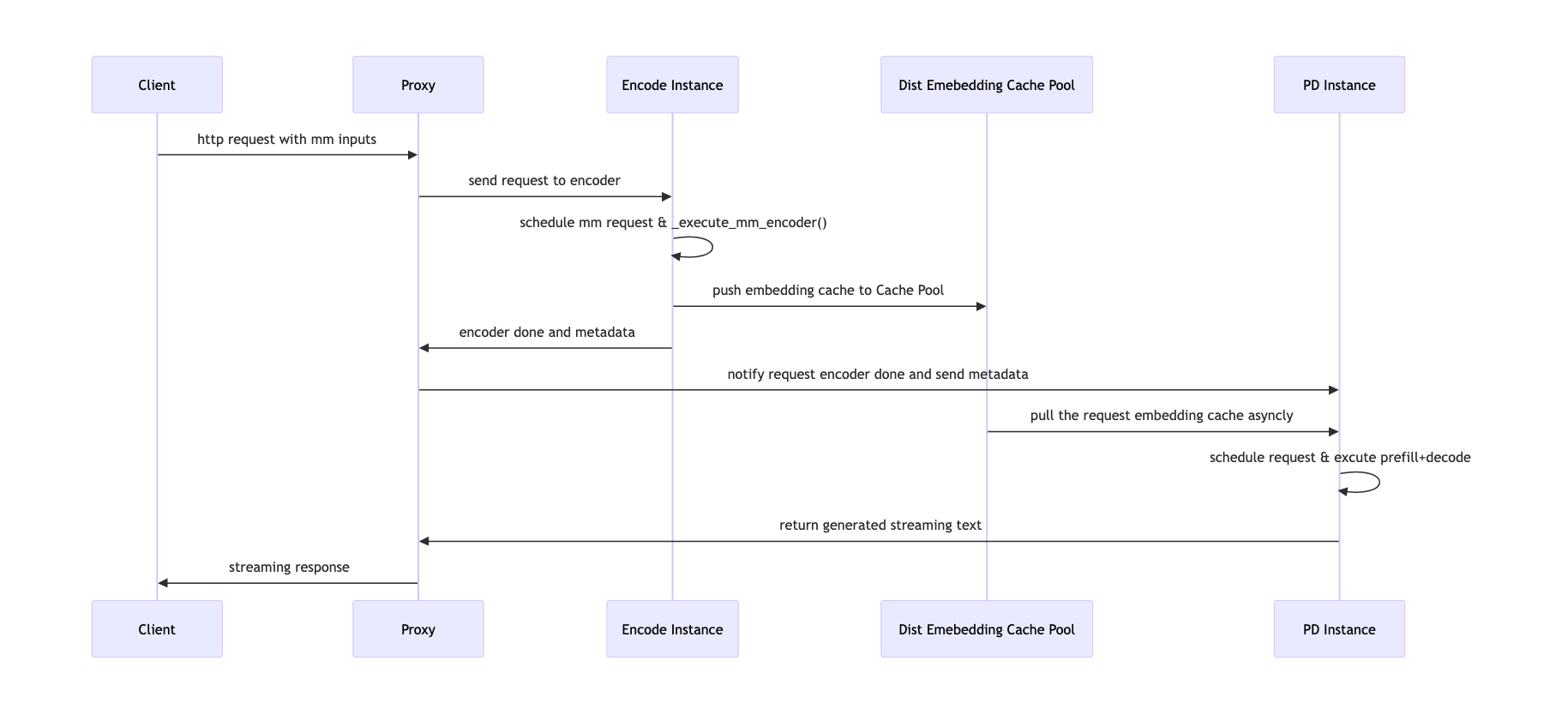
请求生命周期
- 代理接收请求
- 从原始请求中提取多模态输入。
- 创建 N 个编码器作业(每个 MM 输入一个)并将其分派到编码器实例。
- 编码器调度
- 编码器调度器运行作业,计算嵌入。
- 通过 EC 连接器将计算出的嵌入存储到远程存储中。
- 编码器完成
- 所有嵌入存储完成后,编码器工作器通知代理。
- 代理将请求转发到 PD 实例
- 原始请求(包含图像哈希但无像素数据)被发送到预填充/解码节点。
- PD 执行
- PD 实例使用 EC 连接器从远程存储加载 MM 嵌入。
- 正常执行预填充和解码,将嵌入直接注入到模型运行器缓存中。
实现
核心组件
1. ECConnectorRole
定义连接器实例的运行位置
class ECConnectorRole(enum.Enum):
SCHEDULER = 0 # in scheduler process
WORKER = 1 # in worker process
2. ECConnectorMetadata
调度器端和工作器端连接器之间共享的抽象同步/状态对象
class ECConnectorMetadata(ABC):
pass
3. ECConnectorBase
所有连接器的抽象接口。
关键字段
role:调度器或工作器config:连接器特定配置metadata:ECConnectorMetadata
关键方法
has_caches(request):检查远程嵌入是否已存在build_connector_meta(sched_output):确定工作器必须加载哪些缓存update_state_after_alloc(request, item):根据缓存命中/未命中更新缓存分配save_caches(encoder_cache):将编码器输出推送到远程存储start_load_caches(metadata):在预填充/解码执行之前在 PD 端加载缓存
调度器端行为
1. 连接器初始化
调度器
if self.vllm_config.ec_transfer_config is not None:
self.ec_connector = ECConnectorFactory.create_connector(
config=self.vllm_config,
role=ECConnectorRole.SCHEDULER,
)
工作器
def ensure_ec_transfer_initialized(vllm_config):
global _EC_CONNECTOR_AGENT
if vllm_config.ec_transfer_config is None:
return
if vllm_config.ec_transfer_config.is_ec_transfer_instance and _EC_CONNECTOR_AGENT is None:
_EC_CONNECTOR_AGENT = ECConnectorFactory.create_connector(
config=vllm_config,
role=ECConnectorRole.WORKER,
)
2. 远程缓存检查
调度媒体项时
remote_cache_has_item = self.ec_connector.has_caches(request)
3. 缓存状态更新
调度后
for i in external_load_encoder_input:
self.encoder_cache_manager.allocate(request, i)
if self.ec_connector:
self.ec_connector.update_state_after_alloc(request, i)
4. 元数据构造
在调度器迭代结束时
ec_meta = self.ec_connector.build_connector_meta(scheduler_output)
scheduler_output.ec_connector_metadata = ec_meta
工作器端行为
工作器使用 ECConnectorModelRunnerMixin 将连接器操作集成到 GPU 模型运行器中。
执行集成
编码器端(保存到远程存储)
计算嵌入后
for (mm_hash, pos_info), output in zip(mm_hashes_pos, encoder_outputs):
self.encoder_cache[mm_hash] = scatter_mm_placeholders(...)
self.maybe_save_ec_to_connector(self.encoder_cache, mm_hash)
预填充/解码端(加载远程嵌入)
媒体编码器路径被一个加载器包装,该加载器在运行本地编码器之前注入缓存的嵌入
with self.maybe_get_ec_connector_output(
scheduler_output,
encoder_cache=self.encoder_cache,
) as ec_connector_output:
self._execute_mm_encoder(scheduler_output)
mm_embeds, is_mm_embed = self._gather_mm_embeddings(scheduler_output)
性能结果
环境:4×A100 80G
数据集:随机多模态数据集(vllm bench serve --dataset-name random-mm)
输入:400 / 2000 个文本令牌;每个请求 1-4 张图像(640×640 → 每张约 400 个视觉令牌)
输出:150 个令牌
QPS 范围:4-24
模型:Qwen3‑VL‑4B‑Instruct
基线:1 个编码器 + 3 个 PD 实例 (1E3PD) vs 数据并行(--data-parallel-size 4)
生产级 LMM 服务系统需要严格的尾部延迟保证——通常是 P99 TTFT 和 P99 TPOT——以实现最坏情况下的可靠性。我们定义 goodput 为满足两个 SLO(我们的评估中,TTFT 为 20000 毫秒,TPOT 为 100 毫秒)的最大可持续请求率。
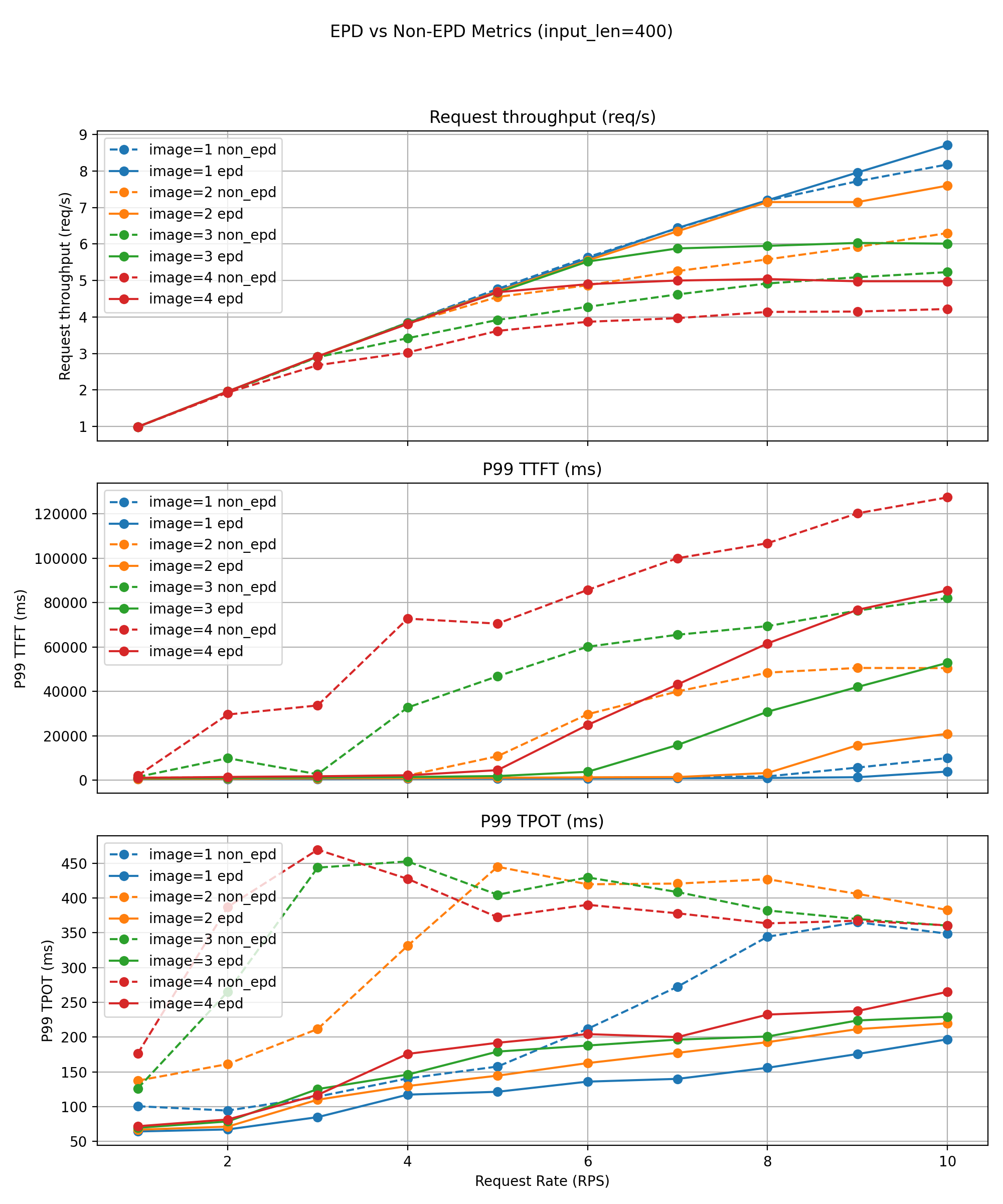
短文本工作负载(约 400 个令牌)
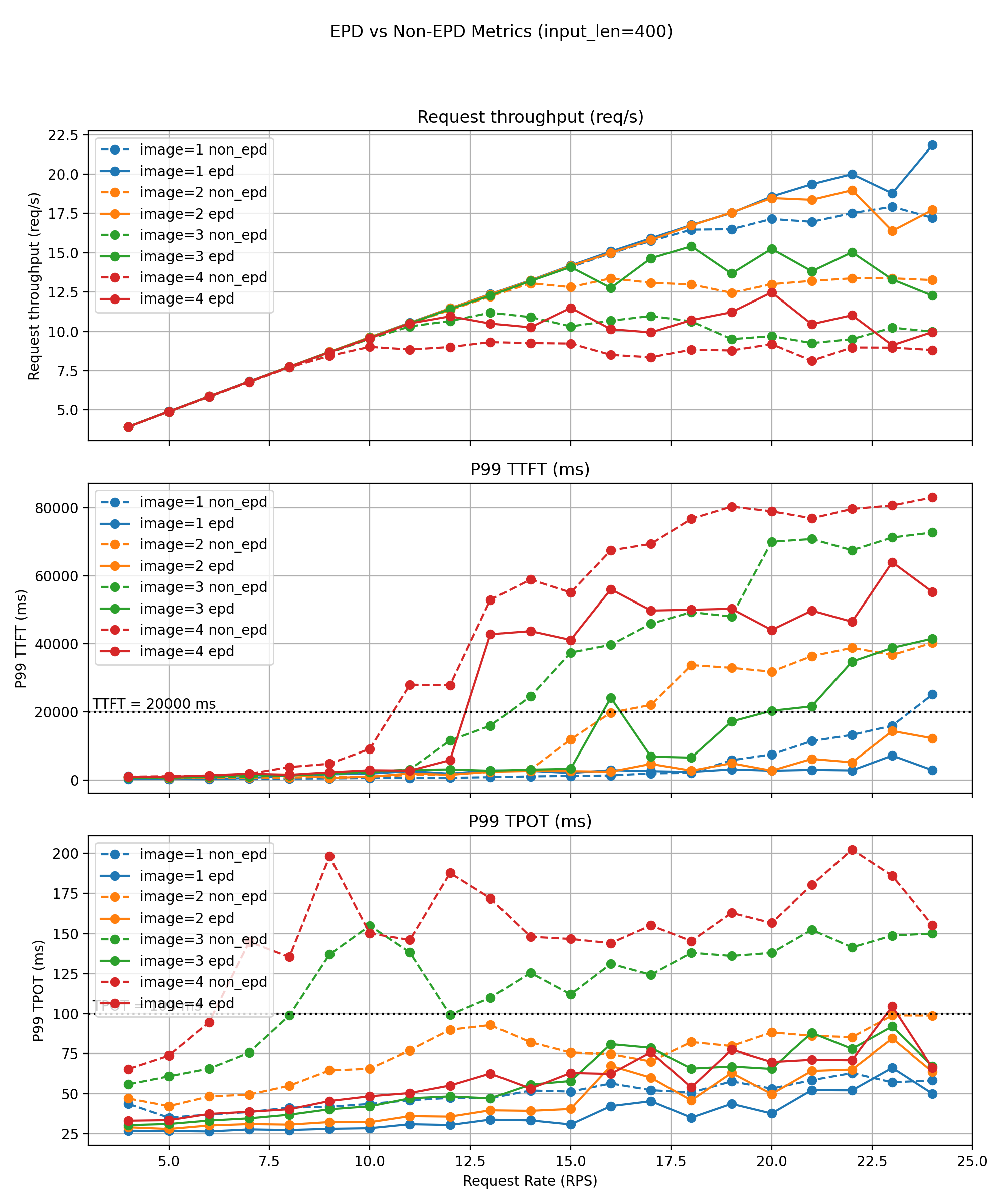
对于短文本请求,EPD 的好处随着每个请求的图像数量急剧增加。
- 单图像:良好的 goodput 适度提升 (23 → 24 QPS)。
- 四图像:goodput 翻倍 (6 → 12 QPS)。
尾部延迟显著改善
- P99 TTFT/TPOT 通常比非 EPD 基线低 20-50%。
吞吐量与速率曲线显示
- 如果没有 EPD,多图像工作负载在大约 12-14 QPS 时会变得不稳定,此时 P99 TPOT 会飙升 30-50%,违反了 SLO。
- EPD 大幅提高了这个不稳定性阈值,并保持更平滑、增长更慢的延迟曲线,这得益于消除了编码器-解码器干扰,以及纯文本请求能够完全绕过多模态工作负载。
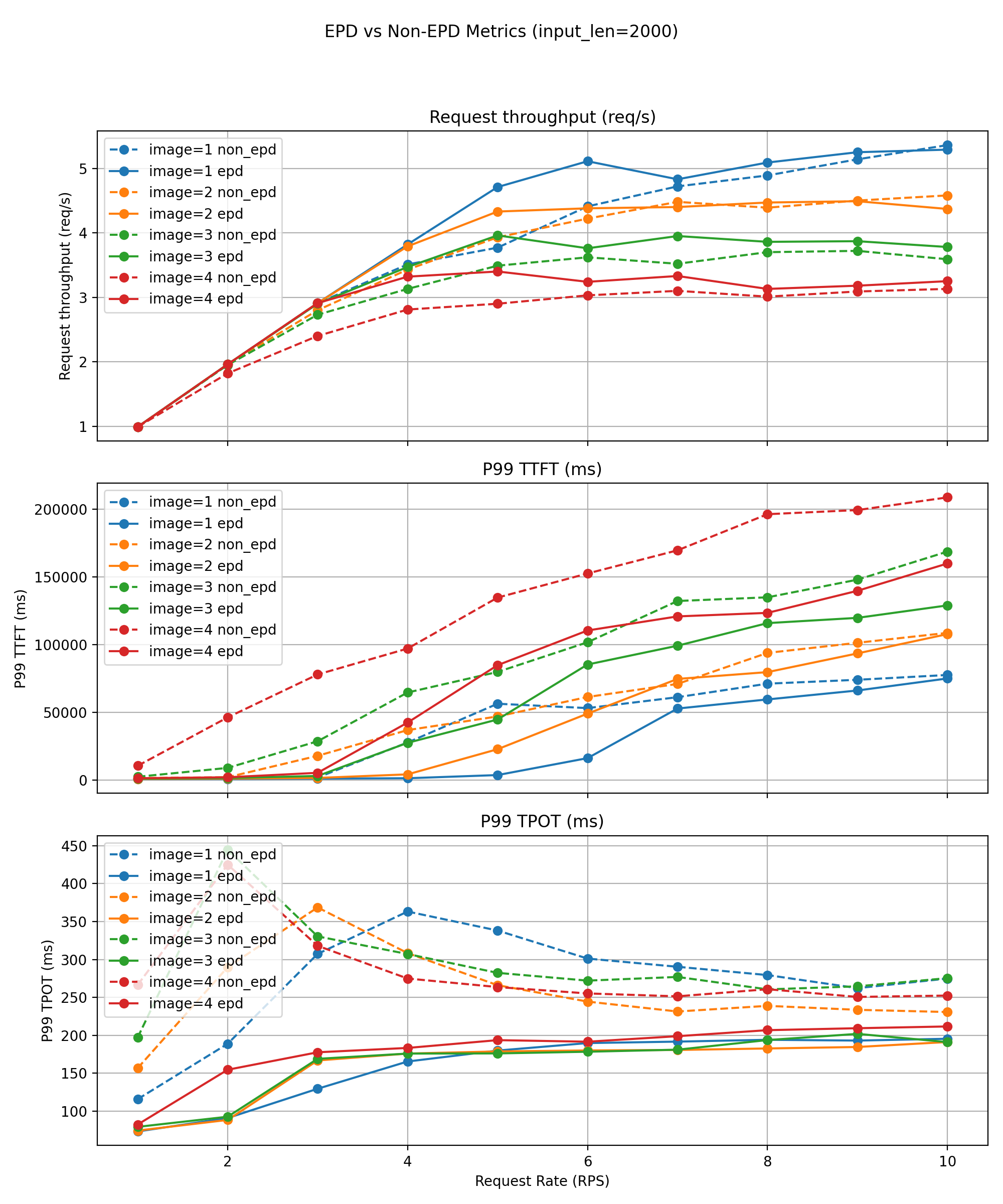
长文本工作负载(约 2000 个令牌)
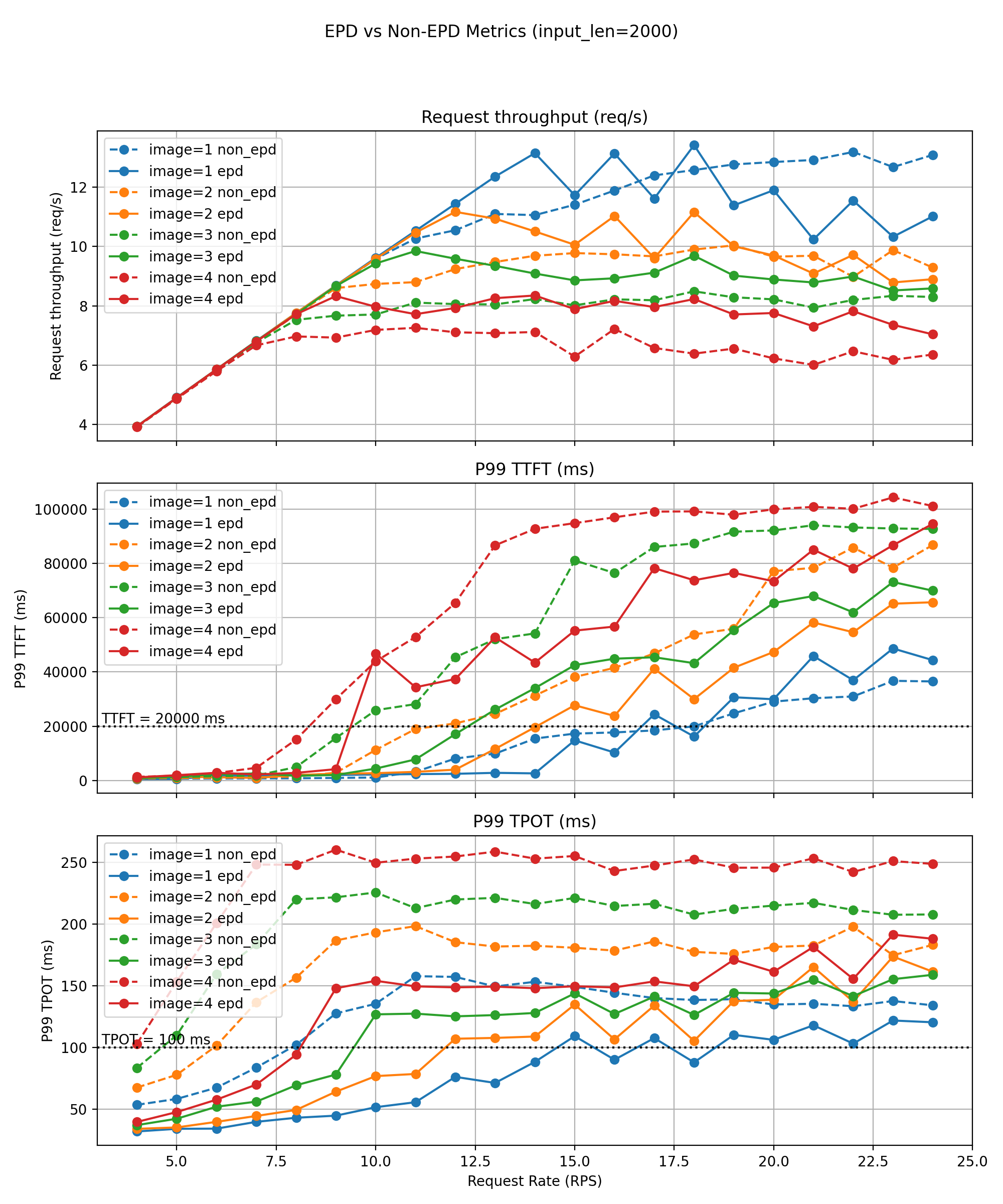
对于较长的输入,图像编码成本占总工作量的一小部分,使系统进入解码主导模式。即使在这种情况下,EPD 也能实现显著的收益。
P99 违规前的基线可持续 QPS
- 1 张图片:8 QPS
- 3-4 张图片:4 QPS
EPD 保持
- 分别为 18 / 11 / 9 / 8 QPS —— goodput 提升 2 倍到 2.5 倍。
额外改进
- 在所有多模态设置中,有效解码吞吐量提高 10-30%。
- P99 TTFT 减少 30-50%。
- 在稳定运行区域内,P99 TPOT 减少 20-40%。
解耦的编码/文本流水线消除了模态竞争,即使在繁重的多模态负载下,也能实现更高的并发性、改进的吞吐量和更严格的 SLO 符合性。
硬件便携性:昇腾 NPU
我们通过少量修改在昇腾 NPU 上重复了实验
- 环境:4×昇腾 910B 32G
- 模型:Qwen2.5‑VL‑7B‑Instruct
- QPS:1-10
在所有昇腾实验中,EPD 展现出相同的硬件无关优势
- 持续更高的吞吐量(在稳定区域内提高 5-20%)。
- P99 TTFT 和 P99 TPOT 显著降低。
- 延迟的拥塞点和更紧凑的尾部延迟曲线。
这证实了 EPD 的优势来源于架构解耦——而非硬件特性——使其可以在 GPU 和 NPU 平台之间移植。
结论
通过对 LMM 推理行为和生产工作负载需求的仔细分析,我们开发了一种解耦的、流水线并行的多模态服务架构,它
- 减少 TTFT 和 TPOT,
- 提高吞吐量和稳定性,
- 消除跨模态干扰,并且
- 实现高效、可扩展的多模态服务。
该架构为下一代高性能 LMM 服务系统提供了实用的蓝图。展望未来,我们将继续通过优化编码器实例的参数加载和扩展 EC 连接器支持来增强 vLLM。
相关工作
ViT DP + LLM TP
在探索编码器解耦之前,vLLM 首先为单节点上的多模态模型引入了一种混合并行策略:ViT 数据并行 + LLM 张量并行方法,其中视觉编码器在 GPU 之间以数据并行方式运行,而语言模型使用张量并行。这种混合策略显著减少了 TTFT 并提高了整体吞吐量。该方法已被证明有效,并被其他服务框架(如 SGLang)采用。
先行技术和行业采纳
NVIDIA Dynamo 团队首次支持了 EPD 式解耦与 vLLM,尽管文档有限。vLLM 原生 EPD 实现(PR #25233)于 2025 年 11 月初合并,并从 0.11.1 版本开始提供,为开源生态系统带来了首个编码器解耦支持。
参考文献
- Qiu, Haoran, et al. ModServe: Modality‑ and Stage‑Aware Resource Disaggregation for Scalable Multimodal Model Serving. 2025.
- Singh, G., et al. Efficiently Serving Large Multimodal Models Using Encoder-Decoder Disaggregation. 2025.
致谢
我们衷心感谢主要贡献者——ZHENG Chenguang, Nguyen Kha Nhat Long, Tai Ho Chiu Hero, Le Manh Khuong, Wu Hang 和 Wu Haiyan——他们在此项目开发过程中做出了重大贡献和提供了技术专长。同时,也特别感谢社区维护者 Roger Wang, Nicolò Lucchesi 和 Cyrus Leung,他们在代码集成过程中提供了宝贵的反馈、富有洞察力的审查和细致的指导,显著提高了代码库的质量和稳定性。