使用 vLLM 上的 NVIDIA Nemotron 3 Nano 运行高效准确的 AI 智能体
我们很高兴发布由 vLLM 支持的 NVIDIA Nemotron 3 Nano。
Nemotron 3 Nano 是新发布的 Nemotron 3 系列的一部分,该系列是最有效率的开放模型,具有领先的准确性,可用于构建智能体 AI 应用程序。Nemotron 3 系列模型采用混合 Mamba-Transformer MoE 架构和 1M 令牌上下文长度。这使开发人员能够在复杂、多文档和长时间操作中构建可靠、高吞吐量的智能体。
Nemotron 3 Nano 完全开源,提供开放权重、数据集和配方,因此开发人员可以轻松地在其基础设施上自定义、优化和部署模型,以实现最大的隐私和安全性。下图显示 Nemotron 3 Nano 在人工智能分析开放性与智能指数中最具吸引力的象限中处于领先地位
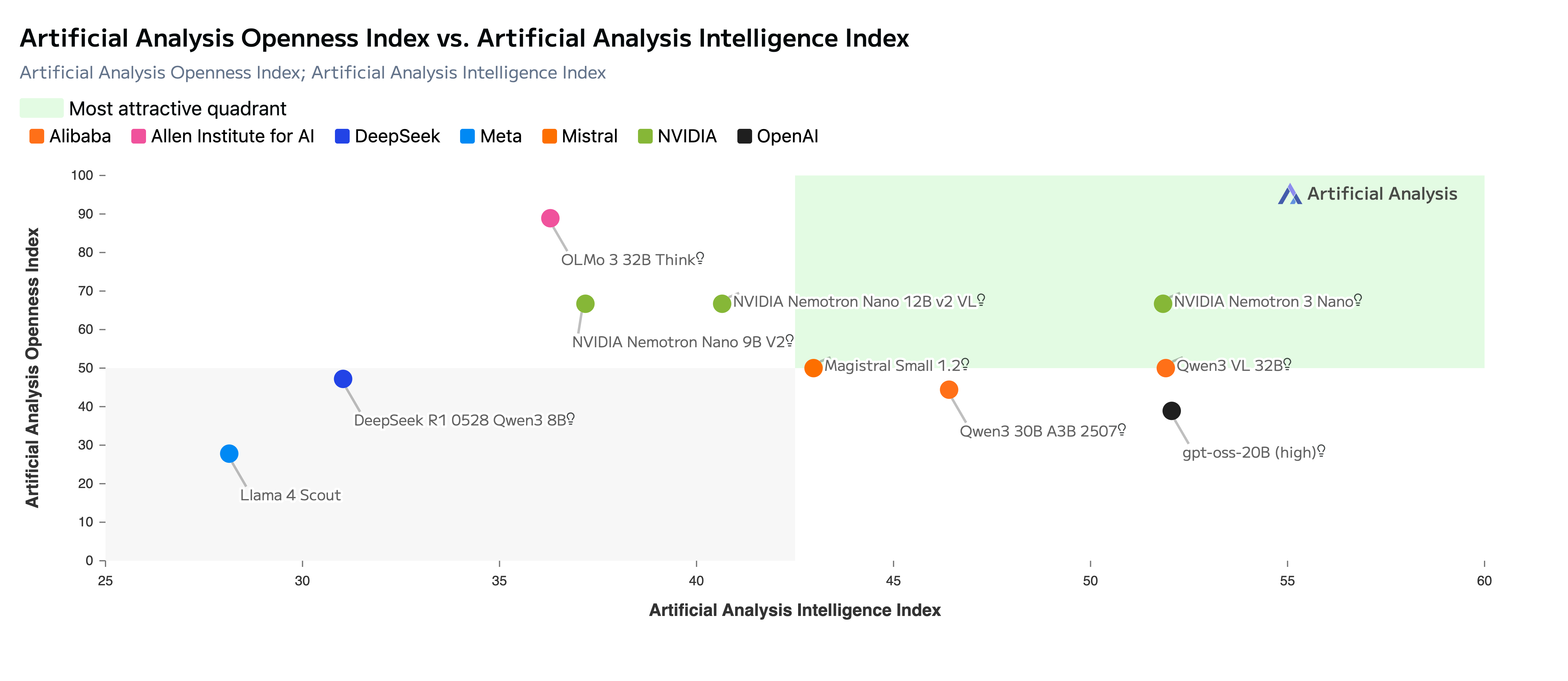
图 1:NVIDIA Nemotron 3 为开源 AI 设定了新标准
Nemotron 3 Nano 在编码、推理和智能体任务方面表现出色,并在 SWE Bench Verified、GPQA Diamond、AIME 2025、Arena Hard v2 和 IFBench 等基准测试中处于领先地位。
在这篇博客文章中,我们将分享如何开始使用 vLLM 进行 Nemotron 3 Nano 推理,以大规模解锁高效 AI 智能体。
关于 Nemotron 3 Nano
- 架构
- 具有混合 Transformer-Mamba 架构的专家混合 (MoE)
- 支持思维预算,以最小的推理令牌生成提供最佳准确性
- 准确性
- 在编码、科学推理、问题解决、数学、指令遵循、聊天方面具有领先的准确性
- 模型大小:30B,具有 3B 活跃参数
- 上下文长度:1M
- 模型输入:文本
- 模型输出:文本
- 支持的 GPU:NVIDIA RTX Pro 6000、DGX Spark、H100、B200。
- 开始
使用 vLLM 运行优化推理
Nemotron 3 Nano 通过 BF16、FP8 精度支持,在同一 GPU 上实现了加速推理并处理更多请求。请按照以下说明开始
运行以下命令安装 vLLM。
VLLM_USE_PRECOMPILED=1 pip install git+https://github.com/vllm-project/vllm.git@main
然后我们可以通过 OpenAI 兼容的 API 提供此模型
export VLLM_ATTENTION_BACKEND=FLASHINFER
# BF16
```bash
vllm serve --model "nvidia/NVIDIA-Nemotron-Nano-3-30B-A3B-BF16" \
--dtype auto \
--trust-remote-code \
--served-model-name nemotron \
--host 0.0.0.0 \
--port 5000 \
--enable-auto-tool-choice \
--tool-call-parser qwen3_coder \
--reasoning-parser deepseek_r1
```
OR
```bash
python -m vllm.entrypoints.openai.api_server \
--model "nvidia/NVIDIA-Nemotron-Nano-3-30B-A3B-BF16" \
--dtype auto \
--trust-remote-code \
--served-model-name nemotron \
--host 0.0.0.0 \
--port 5000 \
--enable-auto-tool-choice \
--tool-call-parser qwen3_coder \
--reasoning-parser deepseek_r1
```
# Swap out model name for FP8
```bash
vllm serve --model "nvidia/NVIDIA-Nemotron-Nano-3-30B-A3B-FP8" \
--dtype auto \
--trust-remote-code \
--served-model-name nemotron \
--host 0.0.0.0 \
--port 5000 \
--enable-auto-tool-choice \
--tool-call-parser qwen3_coder \
--reasoning_parser deepseek_r1
```
服务器启动并运行后,您可以使用以下代码片段提示模型
from openai import OpenAI
client = OpenAI(base_url="http://127.0.0.1:5000/v1", api_key="null")
# Simple chat completion
resp = client.chat.completions.create(
model="nemotron",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Write a haiku about GPUs."}
],
temperature=0.7,
max_tokens=256,
)
print(resp.choices[0].message.reasoning_content, resp.choices[0].message.content)
有关使用 vLLM 的更简单设置,请参阅我们的入门手册,可在此处获取。
高效且在智能体任务中具有领先的准确性
Nemotron 3 Nano 基于我们的 Nemotron Nano 2 模型的混合 Mamba-Transformer 架构,将标准前馈网络 (FFN) 层替换为稀疏 MoE 层,并将大部分注意力层替换为 Mamba-2。MoE 层帮助我们以一小部分活跃参数数量实现更好的准确性。通过 MoE 架构,Nemotron 3 Nano 降低了计算要求并满足了实际应用程序严格的延迟要求。
借助混合 Mamba-Transformer 架构,Nemotron 3 Nano 可提供高达 4 倍的令牌吞吐量,使模型能够更快地思考并同时提供更高的准确性。“思维预算”功能可防止模型过度思考并优化更低、可预测的推理成本。

图 2:Nemotron 3 Nano 在开放式推理模型中提供了更高的吞吐量和领先的准确性
Nemotron 3 Nano 经过 NVIDIA 精心策划的高质量数据训练,在 SWE Bench Verified、GPQA Diamond、AIME 2025、Arena Hard v2 和 IFBench 等基准测试中处于领先地位,在编码、推理、数学和指令遵循方面提供了顶级准确性。这使其成为构建用于各种企业用例(包括金融、网络安全、软件开发和零售)的 AI 智能体的理想选择。
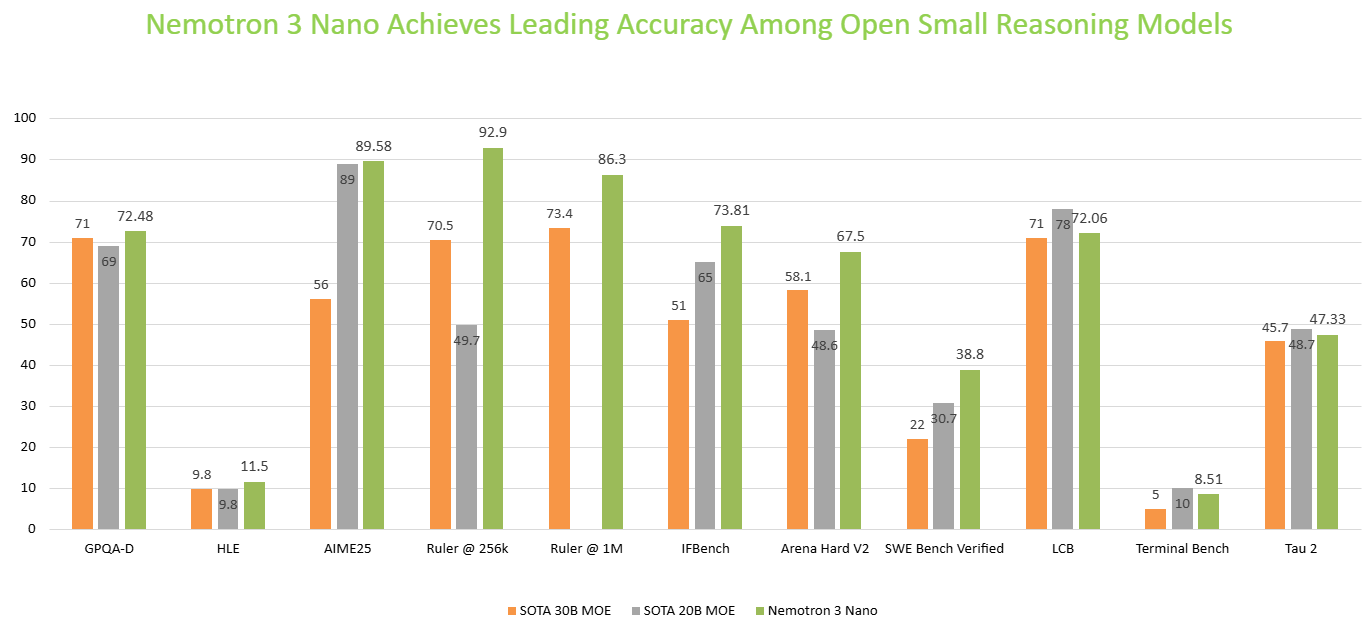
图 3:Nemotron 3 Nano 在开放式小型推理模型中的各种流行学术基准测试中提供了领先的准确性
开始
总而言之,Nemotron 3 Nano 有助于在各种行业中构建可扩展、经济高效的智能体 AI 系统。凭借开放的权重、训练数据集和配方,开发人员获得了充分的透明度和灵活性,可以在从本地到云的任何环境中微调和部署模型,以实现最大的安全和隐私。
准备好构建企业级智能体了吗?
分享您的想法 并投票选出重要事项,以帮助塑造 Nemotron 的未来。
通过订阅 NVIDIA 新闻并在 LinkedIn、X、YouTube 和 Discord 上的 Nemotron 频道关注 NVIDIA AI,以了解 NVIDIA Nemotron 的最新动态。