Token-Level Truth: Real-Time Hallucination Detection for Production LLMs
您的LLM刚刚调用了一个工具,收到了准确的数据,但仍然给出了错误的答案。欢迎来到外在幻觉的世界——模型自信地忽略了摆在它们面前的事实。
在我们信号-决策架构的基础上,我们引入了HaluGate——一个条件式的、令牌级幻觉检测管道,可以在不受支持的说法到达您的用户之前捕获它们。无需将LLM作为判断者。无需Python运行时。只是在交付点进行快速、可解释的验证。
问题:幻觉阻碍了生产部署
幻觉已成为LLM在生产环境中部署的最大障碍。在各行各业——法律(虚构的案例引用)、医疗保健(不正确的药物相互作用)、金融(捏造的财务数据)、客户服务(不存在的政策)——模式都是相同的:AI生成听起来合理且看似权威的内容,但经不起推敲。
挑战并非明显的胡说八道。它是嵌入在其他准确回答中的细微捏造——需要领域专业知识或外部验证才能发现的错误。对于企业来说,这种不确定性使得LLM部署成为一种负债而非资产。
场景:工具工作正常但模型却出错
让我们具体化。考虑一个典型的函数调用交互
用户:“埃菲尔铁塔是什么时候建造的?”
工具调用:
get_landmark_info("Eiffel Tower")工具响应:
{"name": "Eiffel Tower", "built": "1887-1889", "height": "330 meters", "location": "Paris, France"}LLM响应:“埃菲尔铁塔建于1950年,高500米,位于法国巴黎。”
工具返回了正确的数据。模型的响应包含事实。但其中两个“事实”是捏造的——直接与所提供的上下文相矛盾的外在幻觉。
这种失败模式特别具有欺骗性
- 用户信任它,因为他们看到工具被调用了
- 传统过滤器会遗漏它,因为它不包含有害内容
- 如果您依赖另一个LLM进行判断,评估成本高昂
如果我们能以毫秒级延迟实时自动检测这些错误,那该怎么办?
洞察:函数调用作为事实依据
关键的认识是:现代函数调用API已经提供了基础上下文。当用户提出事实性问题时,模型会调用工具——数据库查找、API调用、文档检索。这些工具结果在语义上等同于RAG中检索到的文档。

我们不需要构建单独的检索基础设施。我们不需要调用GPT-4作为判断者。我们从现有API流中提取三个组件
| 组件 | 来源 | 目的 |
|---|---|---|
| 上下文 | 工具消息内容 | 用于验证的事实依据 |
| 问题 | 用户消息 | 意图理解 |
| 答案 | 助手响应 | 待验证的声明 |
问题变为:答案是否忠实于上下文?
为什么不直接使用LLM作为判断者?
显而易见的解决方案——调用另一个LLM进行验证——在生产中存在根本性问题
| 方法 | 延迟 | 成本 | 可解释性 |
|---|---|---|---|
| GPT-4作为判断者 | 2-5秒 | 0.01-0.03美元/请求 | 低(黑箱) |
| 本地LLM判断者 | 500毫秒-2秒 | GPU计算 | 低 |
| HaluGate | 76-162毫秒 | 仅CPU | 高(令牌级+NLI) |
LLM判断者也存在以下问题
- 位置偏差:倾向于偏爱某些答案位置
- 冗长偏差:较长的答案得分较高,无论准确性如何
- 自我偏好:模型偏爱与自身风格相似的输出
- 不一致性:相同的输入可能产生不同的判断
我们需要更快、更便宜、更具可解释性的东西。
HaluGate:两阶段检测管道
HaluGate实现了一个条件两阶段管道,平衡了效率和精确度
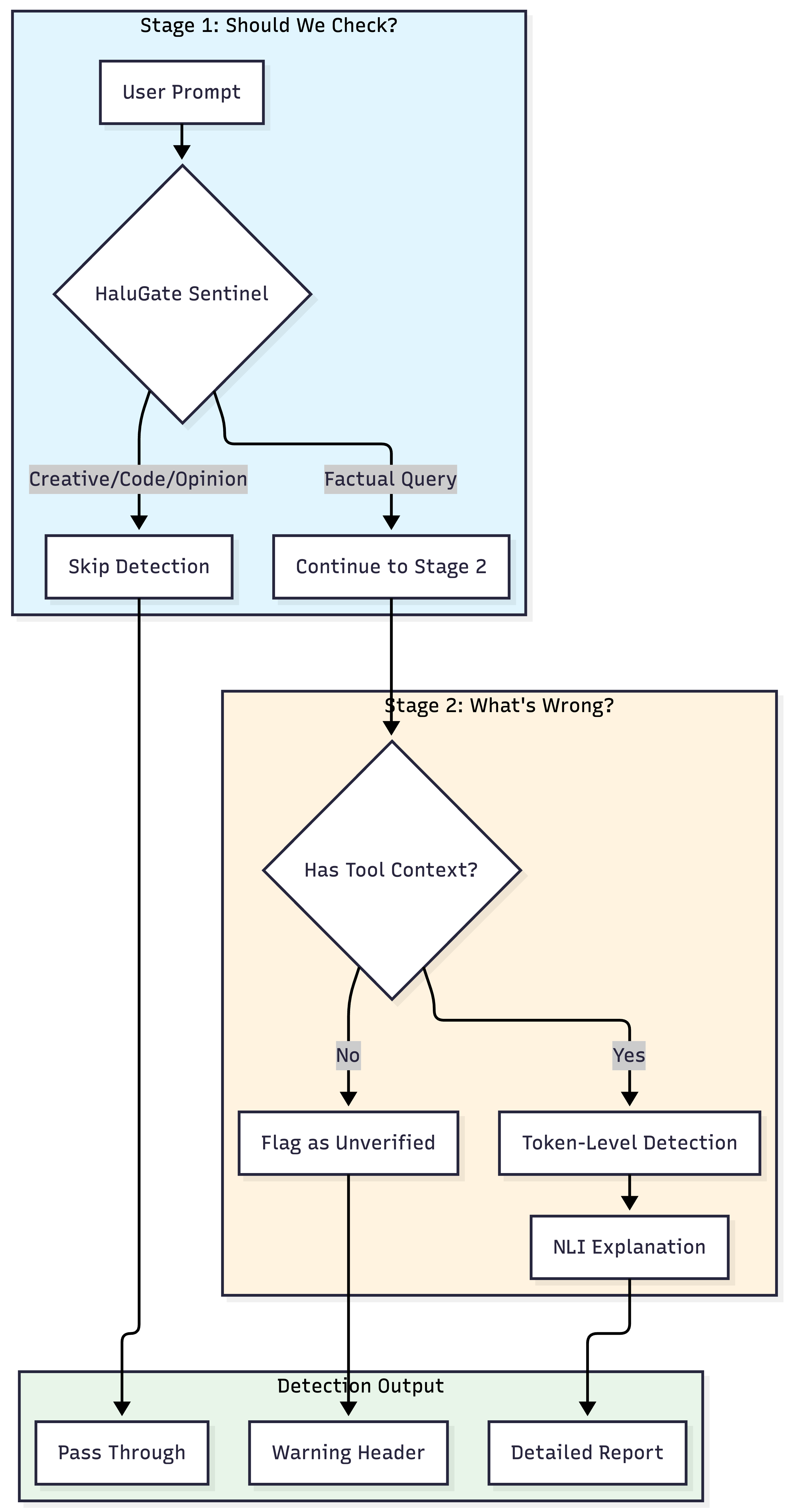
第一阶段:HaluGate Sentinel(提示分类)
并非每个查询都需要幻觉检测。考虑以下提示
| 提示 | 需要事实核查吗? | 原因 |
|---|---|---|
| “爱因斯坦何时出生?” | ✅ 是的 | 可验证的事实 |
| “写一首关于秋天的诗” | ❌ 否 | 创意任务 |
| “调试这段Python代码” | ❌ 否 | 技术援助 |
| “你对AI有什么看法?” | ❌ 否 | 征求意见 |
| “地球是圆的吗?” | ✅ 是的 | 事实主张 |
对创意写作或代码审查运行令牌级检测是浪费的——并且可能产生误报(“你的诗包含未经支持的说法!”)。
为什么预分类很重要:令牌级检测随上下文长度线性扩展。对于4K令牌的RAG上下文,检测大约需要125毫秒;对于16K令牌,大约需要365毫秒。在生产工作负载中,约35%的查询是非事实性的,预分类实现了72.2%的效率提升——完全跳过对创意、编码和意见查询的昂贵检测。
HaluGate Sentinel是一个基于ModernBERT的分类器,它回答一个问题:这个提示是否需要事实核查?

该模型经过精心策划的混合数据训练
需要事实核查(正类):
- 问答:SQuAD、TriviaQA、Natural Questions、HotpotQA
- 真实性:TruthfulQA(常见误解)
- 幻觉基准:HaluEval、FactCHD
- 信息查询对话:FaithDial、CoQA
- RAG数据集:neural-bridge/rag-dataset-12000
不需要事实核查(负类):
- 创意写作:WritingPrompts、故事生成
- 代码:CodeSearchNet文档字符串、编程任务
- 观点/指令:Dolly非事实性、Alpaca创意
通过原生Rust/Candle集成,这种二元分类实现了96.4%的验证准确率和约12毫秒的推理延迟。
第二阶段:令牌级检测+NLI解释
对于被归类为寻求事实的提示,我们运行一个双模型检测管道。
令牌级幻觉检测
与输出单一“幻觉/非幻觉”标签的句子级分类器不同,令牌级检测能识别出上下文中具体哪些令牌没有得到支持。

模型架构
Input: [CLS] context [SEP] question [SEP] answer [SEP]
↓
ModernBERT Encoder
↓
Token Classification Head (Binary per token)
↓
Label: 0 = Supported, 1 = Hallucinated (for answer tokens only)
关键设计决策
- 仅限答案分类:我们只对答案部分的令牌进行分类,而不对上下文或问题进行分类
- 跨度合并:连续的幻觉令牌合并为跨度,以提高可读性
- 置信度阈值:可配置的阈值(默认0.8),以平衡精确度和召回率
NLI解释层
知道某个东西是幻觉还不够——我们需要知道为什么。NLI(自然语言推理)模型根据上下文对每个检测到的跨度进行分类

| NLI标签 | 含义 | 严重性 | 行动 |
|---|---|---|---|
| 矛盾 | 主张与上下文冲突 | 4(高) | 标记为错误 |
| 中立 | 主张未被上下文支持 | 2(中) | 标记为不可验证 |
| 蕴含 | 上下文支持该主张 | 0 | 过滤掉误报 |
为什么集成有效:仅令牌级检测在幻觉类别上的F1分数仅为59%——将近一半的幻觉被遗漏,三分之一的标记是误报。我们尝试训练一个统一的5类模型(支持/矛盾/捏造/等等),但其F1分数仅为21.7%——令牌级分类无法区分为什么某个东西是错误的。两阶段方法将一个平庸的检测器变成了一个可操作的系统:LettuceDetect提供了召回率(捕获潜在问题),而NLI提供了精确度(过滤误报)和可解释性(分类每个跨度为何有问题)。
与信号-决策架构集成
HaluGate并非独立运作——它作为一种新的信号类型和插件,深度集成到我们的信号-决策架构中。
fact_check作为信号类型
就像我们有关键词、嵌入和领域信号一样,fact_check现在是一种一流的信号类型
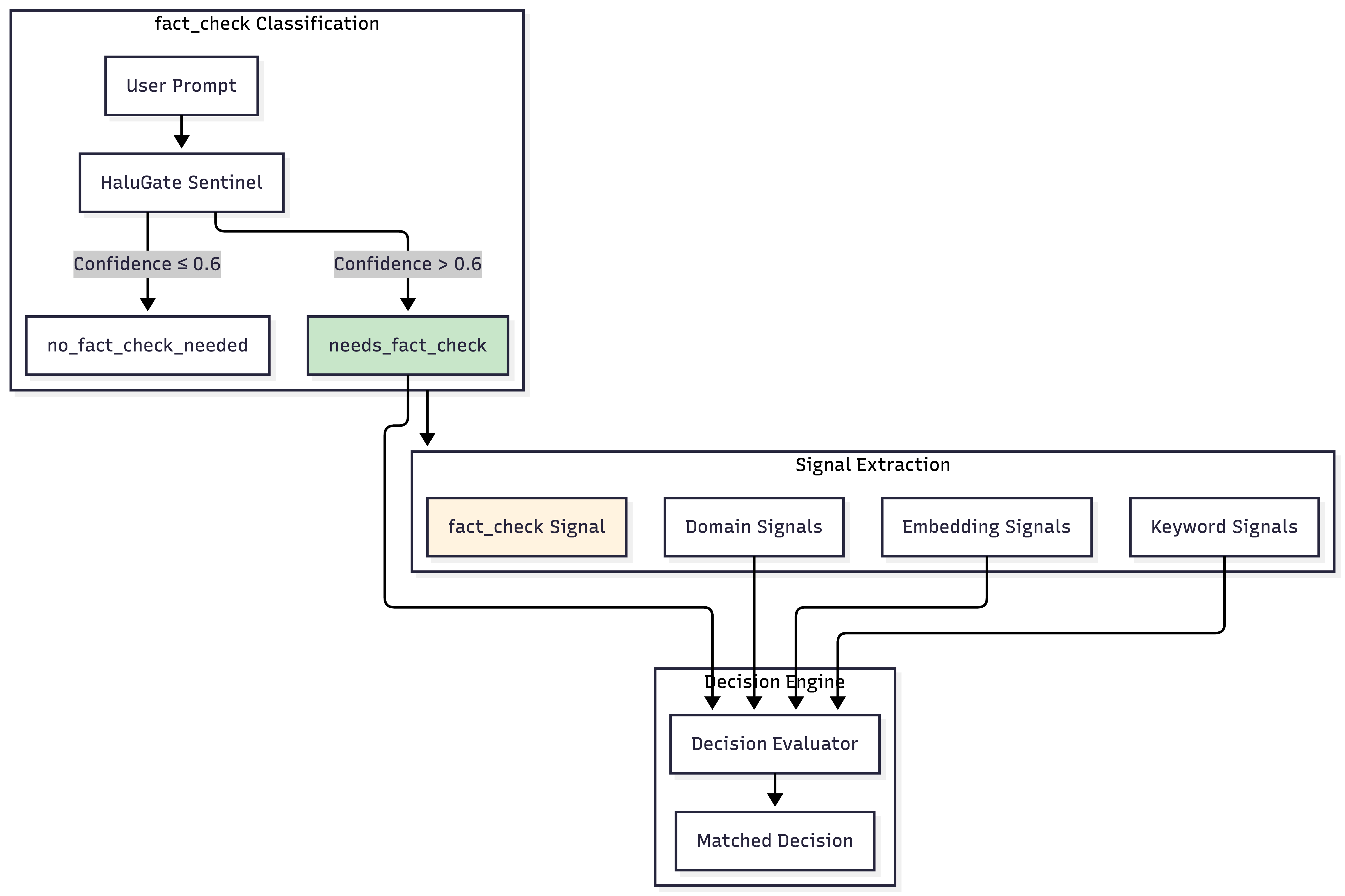
这使得决策可以根据查询是否寻求事实来调整
注意:即使是前沿模型在不同版本之间也表现出幻觉差异。例如,GPT-5.2的系统卡显示与以前版本相比,幻觉存在可测量的差异,这凸显了无论模型复杂程度如何,持续验证的重要性。
decisions:
- name: "factual-query-with-verification"
priority: 100
rules:
operator: "AND"
conditions:
- type: "fact_check"
name: "needs_fact_check"
- type: "domain"
name: "general"
plugins:
- type: "hallucination"
configuration:
enabled: true
use_nli: true
hallucination_action: "header"
请求-响应上下文传播
一个关键挑战:分类发生在请求时,但检测发生在响应时。我们需要在此边界上传播状态。

RequestContext结构包含所有必要的状态
RequestContext:
# Classification results (set at request time)
FactCheckNeeded: true
FactCheckConfidence: 0.87
# Tool context (extracted at request time)
HasToolsForFactCheck: true
ToolResultsContext: "Built 1887-1889, 330 meters..."
UserContent: "When was the Eiffel Tower built?"
# Detection results (set at response time)
HallucinationDetected: true
HallucinationSpans: ["1950", "500 meters"]
HallucinationConfidence: 0.92
hallucination插件
幻觉插件是按决策配置的,允许细粒度控制
plugins:
- type: "hallucination"
configuration:
enabled: true
use_nli: true # Enable NLI explanations
# Action when hallucination detected
hallucination_action: "header" # "header" | "body" | "block" | "none"
# Action when fact-check needed but no tool context
unverified_factual_action: "header"
# Include detailed info in response
include_hallucination_details: true
| 行动 | 行为 |
|---|---|
header |
添加警告头,传递响应 |
body |
将警告注入响应正文 |
block |
返回错误响应,不转发LLM输出 |
none |
仅记录,无用户可见操作 |
响应头:可操作的透明度
检测结果通过HTTP头传递,使下游系统能够实施自定义策略
HTTP/1.1 200 OK
Content-Type: application/json
x-vsr-fact-check-needed: true
x-vsr-hallucination-detected: true
x-vsr-hallucination-spans: 1950; 500 meters
x-vsr-nli-contradictions: 2
x-vsr-max-severity: 4
对于未经验证的事实响应(当工具不可用时)
HTTP/1.1 200 OK
x-vsr-fact-check-needed: true
x-vsr-unverified-factual-response: true
x-vsr-verification-context-missing: true
这些标题使得
- UI免责声明:在置信度低时向用户显示警告
- 人工审查队列:将标记的响应路由到人工审查
- 审计日志:跟踪未经核实的主张以符合法规
- 有条件阻止:阻止高严重性矛盾
完整管道:三条路径

| 路径 | 条件 | 增加的延迟 | 行动 |
|---|---|---|---|
| 路径1 | 非事实性提示 | 约12毫秒(仅分类器) | 通过 |
| 路径2 | 事实性+无工具 | 约12毫秒 | 添加警告头 |
| 路径3 | 事实性+工具可用 | 76-162毫秒 | 完整检测+头 |
模型架构深度解析
让我们看看支持HaluGate的三个模型

HaluGate Sentinel:二元提示分类
架构:ModernBERT-base + LoRA适配器 + 二元分类头
训练:
- 基础模型:
answerdotai/ModernBERT-base - 微调:LoRA (rank=16, alpha=32, dropout=0.1)
- 训练数据:来自14个数据集的50,000个样本
- 损失:带类权重的交叉熵(处理不平衡)
- 优化:AdamW, 学习率=2e-5, 3个epoch
推理:
- 输入:原始提示文本
- 输出:(类ID,置信度)
- 延迟:CPU上约12毫秒
LoRA方法允许高效微调,同时保留预训练知识。在训练过程中,只有2.2%的参数(1.49亿中的340万)被更新。
HaluGate Detector:令牌级二元分类
架构:ModernBERT-base + 令牌分类头
输入格式:
[CLS] The Eiffel Tower was built in 1887-1889 and is 330 meters tall.
[SEP] When was the Eiffel Tower built?
[SEP] The Eiffel Tower was built in 1950 and is 500 meters tall. [SEP]
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
Answer tokens (classification targets)
输出:每个答案令牌的二元标签(0=支持,1=幻觉)
后处理:
- 仅过滤答案部分的预测
- 应用置信度阈值(默认值:0.8)
- 将连续的幻觉令牌合并成跨度
- 返回带有置信度分数的跨度
HaluGate Explainer:三向NLI分类
架构:在NLI上微调的ModernBERT-base
输入格式:
[CLS] The Eiffel Tower was built in 1887-1889. [SEP] built in 1950 [SEP]
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ ^^^^^^^^^^^^^^^
Premise (context) Hypothesis (span)
输出:带有置信度的三向分类
- 蕴含 (0):上下文支持该主张
- 中立 (1):无法从上下文中确定
- 矛盾 (2):上下文与主张冲突
严重性映射:
| NLI标签 | 严重性分数 | 解释 |
|---|---|---|
| 蕴含 | 0 | 可能是误报——过滤掉 |
| 中立 | 2 | 主张不可验证 |
| 矛盾 | 4 | 直接事实错误 |
为什么原生Rust/Candle很重要
所有三个模型都通过Candle(Hugging Face的Rust ML框架)与Go的CGO绑定原生运行

这种方法的好处
| 方面 | Python (PyTorch) | 原生 (Candle) |
|---|---|---|
| 冷启动 | 5-10秒 | <500毫秒 |
| 内存 | 每个模型2-4GB | 每个模型500MB-1GB |
| 延迟 | +50-100毫秒开销 | 近乎零开销 |
| 部署 | 需要Python运行时 | 单一二进制文件 |
| 扩展 | GIL争用 | 真正的并行性 |
这消除了对单独的Python服务、sidecar或模型服务器的需求——所有功能都在进程内运行。
延迟分解
以下是生产管道中每个组件的测量延迟
| 组件 | P50 | P99 | 备注 |
|---|---|---|---|
| 事实核查分类器 | 12毫秒 | 28毫秒 | ModernBERT推理 |
| 工具上下文提取 | 1毫秒 | 3毫秒 | JSON解析 |
| 幻觉检测器 | 45毫秒 | 89毫秒 | 令牌分类 |
| NLI解释器 | 18毫秒 | 42毫秒 | 每跨度分类 |
| 总开销 | 76毫秒 | 162毫秒 | 检测运行时 |
与典型的LLM生成时间(5-30秒)相比,总开销(76-162毫秒)可以忽略不计,这使得HaluGate适用于同步请求处理。
配置参考
幻觉缓解的完整配置
# Model configuration
hallucination_mitigation:
# Stage 1: Prompt classification
fact_check_model:
model_id: "models/halugate-sentinel"
threshold: 0.6 # Confidence threshold for FACT_CHECK_NEEDED
use_cpu: true
# Stage 2a: Token-level detection
hallucination_model:
model_id: "models/halugate-detector"
threshold: 0.8 # Token confidence threshold
use_cpu: true
# Stage 2b: NLI explanation
nli_model:
model_id: "models/halugate-explainer"
threshold: 0.9 # NLI confidence threshold
use_cpu: true
# Signal rules for fact-check classification
fact_check_rules:
- name: needs_fact_check
description: "Query contains factual claims that should be verified"
- name: no_fact_check_needed
description: "Query is creative, code-related, or opinion-based"
# Decision with hallucination plugin
decisions:
- name: "verified-factual"
priority: 100
rules:
operator: "AND"
conditions:
- type: "fact_check"
name: "needs_fact_check"
plugins:
- type: "hallucination"
configuration:
enabled: true
use_nli: true
hallucination_action: "header"
unverified_factual_action: "header"
include_hallucination_details: true
超越生产:HaluGate作为评估框架
HaluGate虽然专为实时生产使用而设计,但相同的管道可以支持离线模型评估。我们不是拦截实时请求,而是通过检测管道输入基准数据集,以系统地测量不同模型的幻觉率。

评估工作流程
评估框架将HaluGate视为幻觉评分器
- 加载数据集:使用现有QA/RAG基准(TriviaQA、Natural Questions、HotpotQA)或带有上下文-问题对的自定义企业数据集
- 生成响应:针对每个带有提供上下文的查询运行待测模型
- 检测幻觉:将(上下文、查询、响应)三元组通过HaluGate Detector
- 分类严重性:使用HaluGate Explainer对每个标记的跨度进行分类
- 聚合指标:计算幻觉率、矛盾比率和按类别划分的细分
局限性和范围
HaluGate专门针对外在幻觉——工具/RAG上下文提供了验证的基础。它有一些已知的局限性
HaluGate无法检测到什么
| 局限性 | 示例 | 原因 |
|---|---|---|
| 内在幻觉 | 模型说“爱因斯坦出生于1900年”而没有调用任何工具 | 没有可供验证的上下文 |
| 无上下文场景 | 用户提出事实性问题,未定义工具 | 缺少事实依据 |
透明降级
对于被分类为寻求事实但缺少工具上下文的请求,我们会明确将响应标记为“未经证实的事实”,而不是悄悄地通过它们
x-vsr-fact-check-needed: true
x-vsr-unverified-factual-response: true
x-vsr-verification-context-missing: true
这种透明度允许下游系统适当地处理不确定性。
致谢
HaluGate建立在研究社区的卓越工作之上
- 令牌级检测架构:受KRLabs的LettuceDetect启发——基于ModernBERT的幻觉检测的开创性工作
- NLI模型:基于tasksource/ModernBERT-base-nli——高质量的NLI微调
- 训练数据集:TruthfulQA、HaluEval、FaithDial、RAGTruth和其他公开可用的基准
我们感谢这些团队在幻觉检测领域取得的进展。
结论
HaluGate将原则性的幻觉检测带入生产级LLM部署
- 条件验证:跳过非事实性查询,验证事实性查询
- 令牌级精度:准确知道哪些主张不受支持
- 可解释结果:NLI分类告诉您为什么某个东西是错误的
- 零延迟集成:原生Rust推理,无需Python sidecar
- 可操作的透明度:Header启用下游策略执行
下次您的LLM调用工具,收到准确数据,但仍然给出错误答案时——HaluGate会在您的用户发现之前捕获它。
资源:
加入讨论:在vLLM Slack的#semantic-router频道分享您的用例和反馈