vLLM Router:用于大规模服务的HPC和预填充/解码感知负载均衡器
在大型生产vLLM部署中,有效管理跨模型副本群的请求分发是至关重要的。标准负载均衡器往往力不从心,因为它们缺乏对LLM推理有状态特性(例如,KV缓存)的感知,并且无法管理预填充/解码分离等复杂的服务模式。
为了解决这个问题,我们推出了 vLLM Router(Github仓库),这是一款专为vLLM设计的高性能、轻量级负载均衡器。该路由器采用Rust构建,以实现最小开销,它作为一个智能的、状态感知的负载均衡器,位于客户端和vLLM工作器集群之间,无论是在K8s还是裸机GPU集群中。
vLLM Router 源自 SGLang 模型网关 的一个分支,经过修改和简化以与 vLLM 配合使用。随着我们探索将此路由器合并到 vLLM 主仓库中,预计会有进一步的分歧。另一方面,大规模部署的网关功能可能会与 SGLang 模型网关开发人员协作统一。
核心架构和功能
vllm-router 旨在解决大规模服务中的两个主要挑战:智能负载均衡和对预填充/解码分离的支持。
1. 智能负载均衡策略
与简单的轮询不同,vLLM Router 提供了多种复杂的负载均衡算法,以优化性能和有状态亲和性。对于对话工作负载,将来自同一用户的后续请求路由到持有其 KV 缓存的同一工作器对于最大程度地减少延迟至关重要。
为此,路由器支持多种策略
- 一致性哈希: 这是最大化性能的关键策略。它确保具有相同路由键(例如,会话ID或用户ID)的请求是“粘性”的,并始终路由到相同的Worker副本,从而最大限度地重用KV缓存。
- 二的幂次 (PoT): 一种低开销的随机选择策略,提供出色的负载分布。
- 轮询和随机: 用于无状态负载分布的标准策略。
2. 对预填充/解码分离的原生支持
该路由器被设计为vLLM最先进的服务架构:预填充/解码(P/D)分离的编排层。
在此架构中,计算密集型预填充步骤和内存密集型解码步骤由单独的、专业的Worker组处理。vLLM Router管理这个复杂的工作流
- 它智能地将新请求路由到预填充工作组。
- 完成后,它将请求状态导向相应的解码工作器以生成令牌。
- 它支持 NIXL 和 基于 NCCL (带 ZMQ 发现) 分离后端 的发现和路由。
企业级韧性和可观察性
vllm-router 内置了生产级功能,以在大规模环境中保持高可用性。
- Kubernetes 服务发现: 路由器可以在 Kubernetes 原生模式下运行,使用标签选择器自动发现、监控和路由到 vLLM 工作器 Pod。
- 容错: 它包括可配置的 重试逻辑(带指数退避和抖动)和 熔断器。如果工作器健康检查失败,路由器会立即将其从路由池中移除并重试请求,防止级联故障。
- 可观测性: 内置的 Prometheus 端点(
/metrics)导出请求量、延迟、错误率和单个工作器健康状况的详细指标,为服务集群提供完整的可见性。
基准分析:大规模下性能最佳的选择
我们将新的 vLLM 路由器与两个广泛使用的替代方案进行了基准测试
- llm-d: 一个 Kubernetes 原生路由框架,利用默认的队列感知负载均衡。
- vLLM-native: 标准的 K8s 原生负载均衡器,采用基本的轮询策略。关键是,此选项并 不 了解预填充/解码状态,将所有 Pod 视为相同的 vLLM 副本。
排除说明: 我们从基准测试中排除了 vLLM 内置的 DP/EP 协调器——推荐的 vLLM 集群 外部负载均衡 解决方案。由于一个已知的 性能问题,其吞吐量仅为其他方案的 1/8。
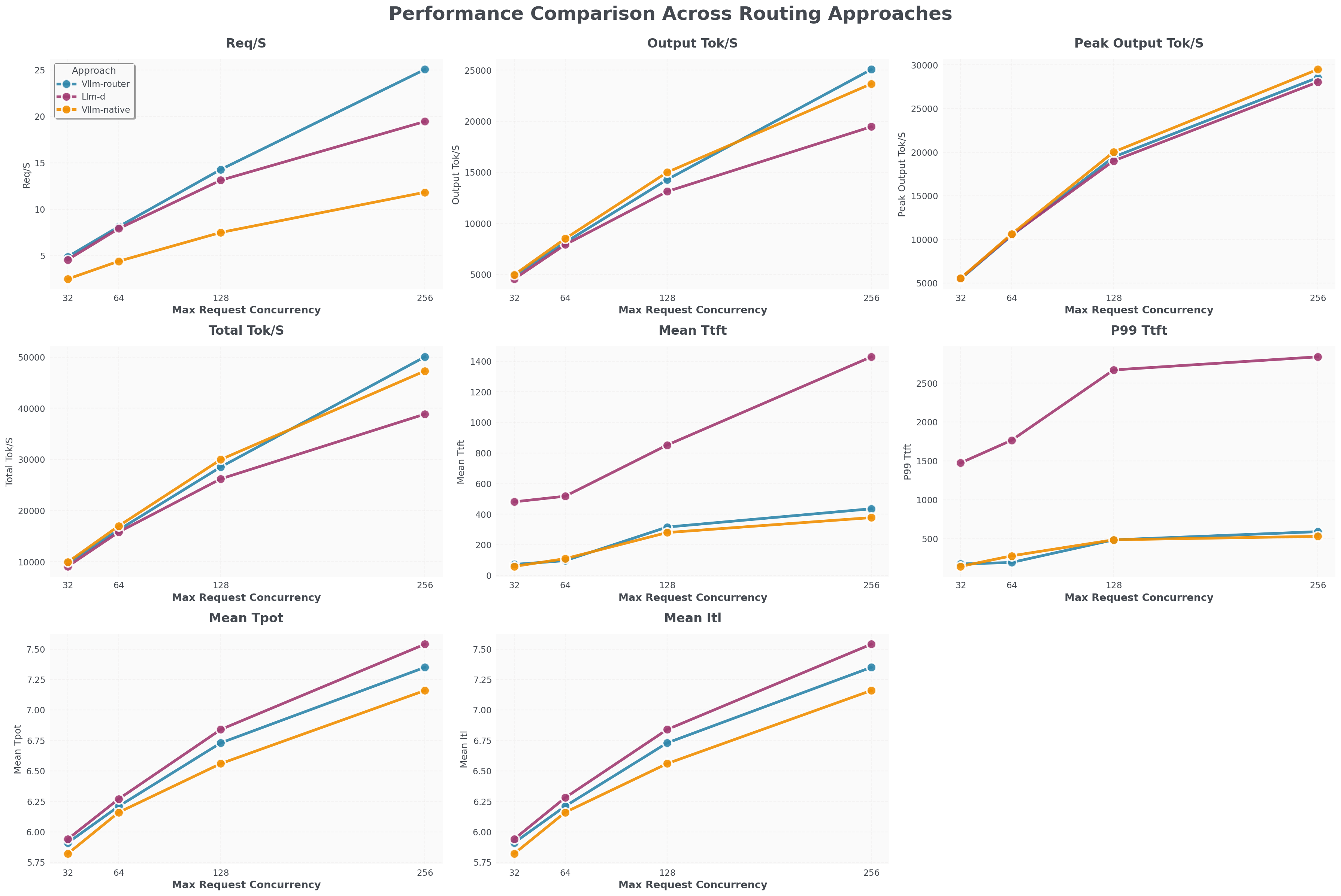
Llama 3.1 8B,包含 8 个预填充 Pod 和 8 个解码 Pod
- vLLM Router (蓝色线) 的请求/秒吞吐量比 llm-d (紫色线) 高 25%,比 K8s 原生负载均衡器 (橙色线) 高 100%。
- vLLM Router 的 TTFT 接近 K8s 原生负载均衡器,比 llm-d 快 1200 毫秒。
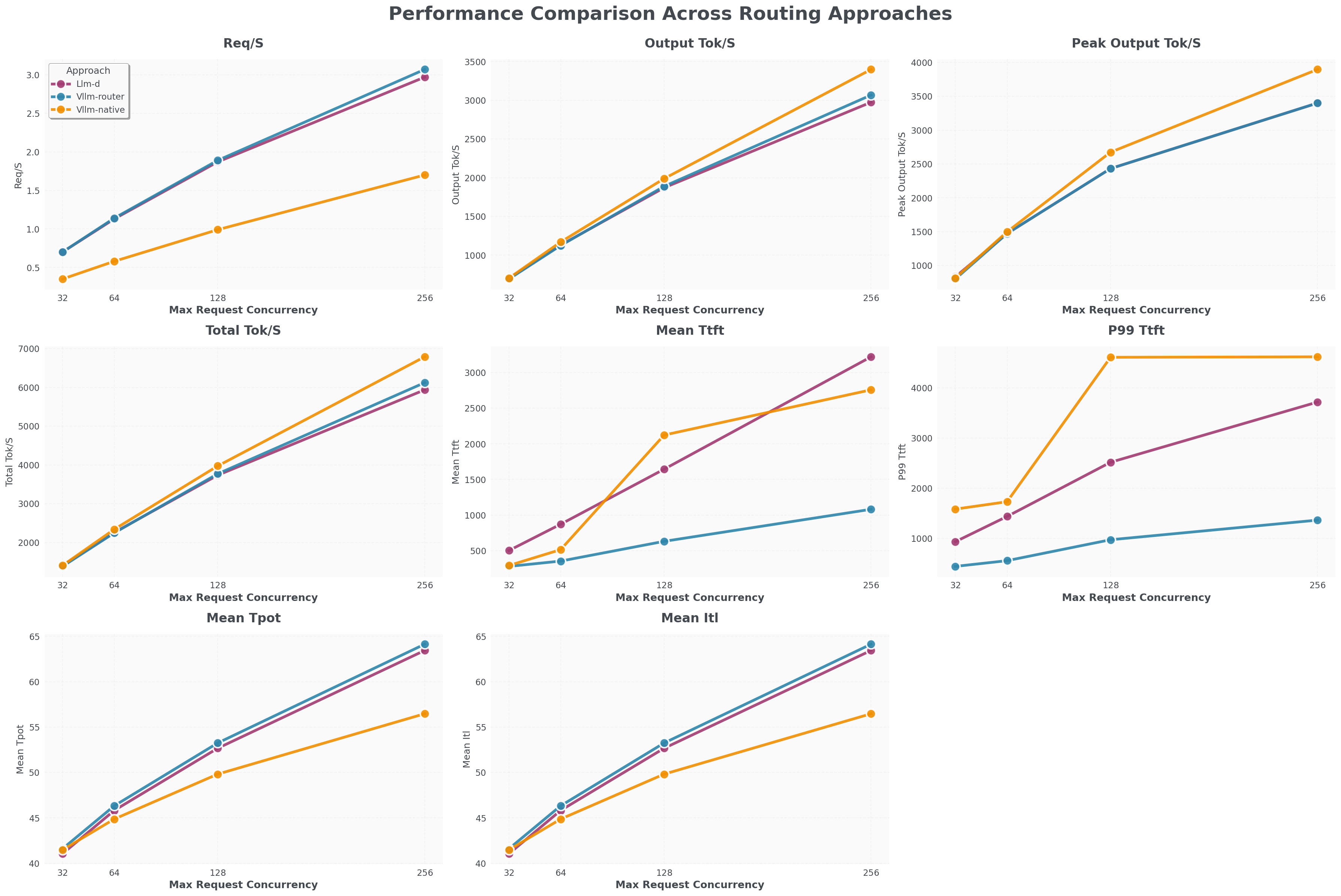
Deepseek V3,包含 1 个预填充 Pod (TP8) 和 1 个解码 Pod (TP8)
- vLLM Router (蓝色线) 的请求/秒吞吐量与 llm-d (紫色线) 接近,比 K8s 原生负载均衡器 (橙色线) 高 100%。
- vLLM Router 的 TTFT 比 llm-d 和 K8s 原生快 2000 毫秒。
总结
vLLM Router 是 vLLM 在生产规模下运行的关键组件。它将服务架构从单个实例的集合转变为一个统一、弹性的集群。通过提供智能负载均衡和对预填充/解码分离的原生支持,它解锁了性能和运营效率的新水平。
致谢
- 感谢 Phi 和 AWS 团队提供的技术支持和测试集群。
- 特别感谢 Naman Lalit 推动了全面的性能和正确性基准测试工作。
- 我们还感谢 SGLang 模型网关团队。通过 fork 他们成熟的 API 实现和服务框架,我们能够显著加速我们的设计和实现过程,同时保持与开放标准的对齐。
- 最后,我们感谢 Tyler Michael Smith 和 Robert Shaw 分享 llm-d 专长和经验,这些消除了性能优化和基准测试的障碍。