发布 vLLM-Omni:简单、快速、经济的全模态模型服务
我们激动地宣布正式发布 vLLM-Omni,这是 vLLM 生态系统的一次重大扩展,旨在支持下一代人工智能:全模态模型。
![]()
自诞生以来,vLLM 一直专注于为大语言模型 (LLM) 提供高吞吐量、高内存效率的服务。然而,生成式人工智能的格局正在迅速变化。模型不再仅仅是文本输入、文本输出。当今最先进的模型能够跨越文本、图像、音频和视频进行推理,并使用多样化的架构生成异构输出。
vLLM-Omni 是首批支持全模态模型服务的开源框架之一,它将 vLLM 的卓越性能扩展到了多模态和非自回归推理领域。
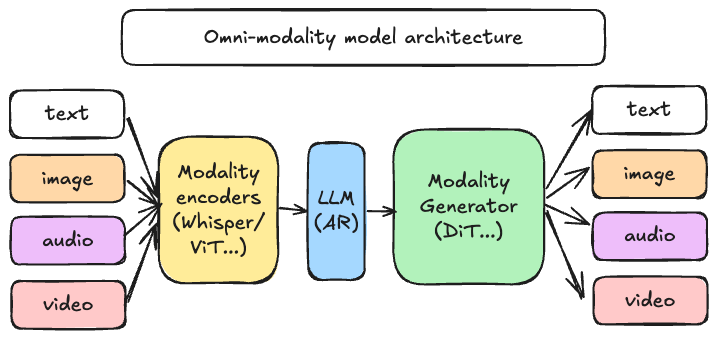
为什么选择 vLLM-Omni?
传统的服务引擎是为基于文本的自回归 (AR) 任务而优化的。随着模型演变为能够看、听、说的“全能”代理,服务基础设施也必须随之进化。
vLLM-Omni 应对了模型架构中的三个关键转变:
- 真正的全模态:无缝处理和生成文本、图像、视频和音频。
- 超越自回归:将 vLLM 高效的内存管理扩展到扩散变换器 (DiT) 和其他并行生成模型。
- 异构模型流水线:编排复杂的模型工作流,其中单个请求可以调用多个异构模型组件。(例如,多模态编码、自回归推理、基于扩散的多模态生成等)。
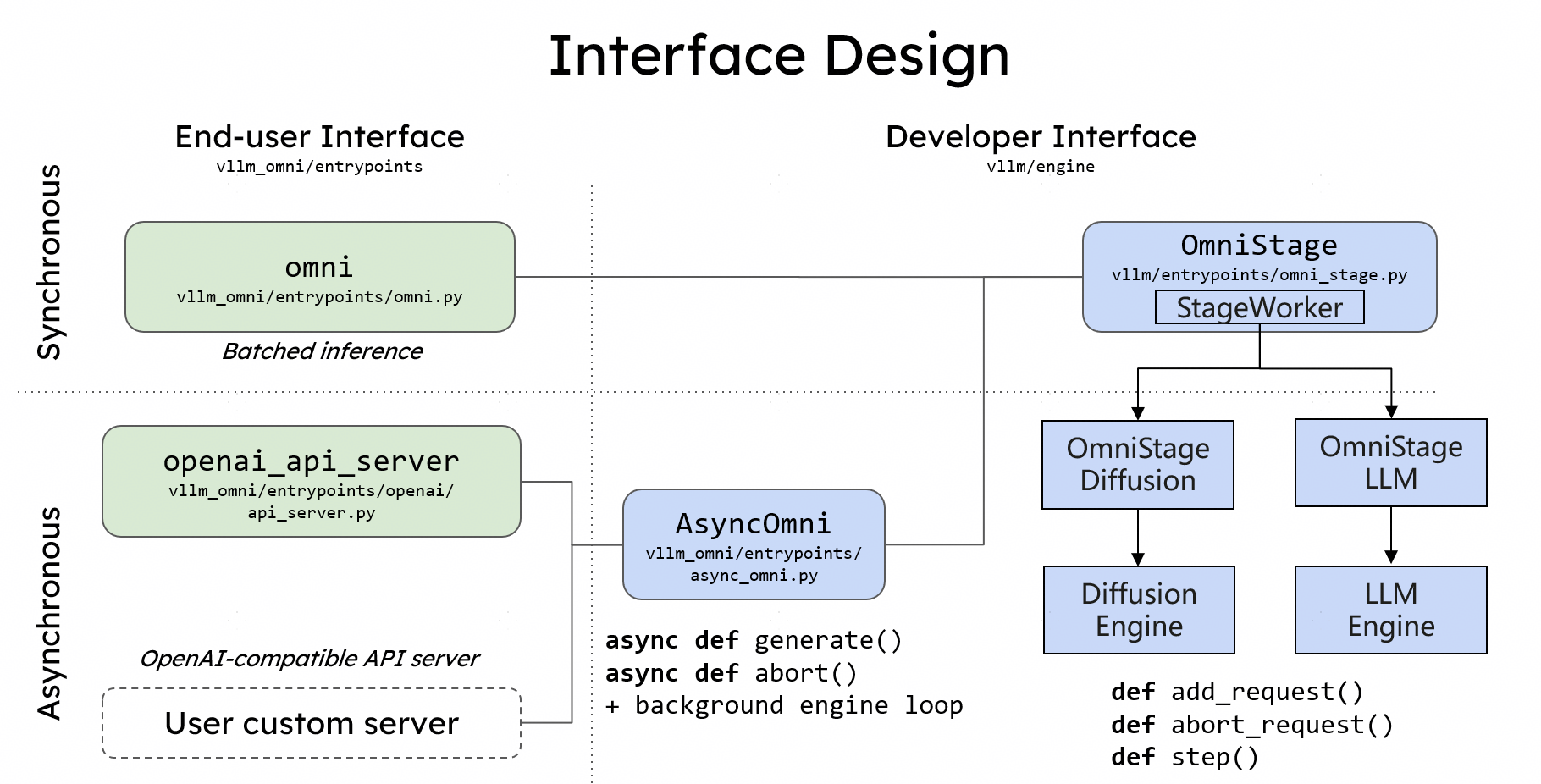
架构内幕
vLLM-Omni 不仅仅是一个封装层;它是对 vLLM 内部及外部数据流的重新构想。它引入了一个完全解耦的流水线,允许在不同的生成阶段进行动态资源分配。如上图所示,该架构统一了不同的阶段:
- 模态编码器:高效编码多模态输入(ViT、Whisper 等)。
- LLM 核心:利用 vLLM 和一个或多个语言模型进行自回归文本和隐藏状态的生成。
- 模态生成器:为 DiT 和其他解码头提供高性能服务,以产生富媒体输出。
主要特性
-
简单易用:如果你知道如何使用 vLLM,你就知道如何使用 vLLM-Omni。我们保持了与 Hugging Face 模型的无缝集成,并提供了一个与 OpenAI 兼容的 API 服务器。
-
灵活性:通过 OmniStage 抽象,我们提供了一种简单直接的方式来支持各种全模态模型,包括 Qwen-Omni、Qwen-Image 和其他最先进的模型。
-
高性能:我们利用流水线式的阶段执行来重叠计算,以实现高吞吐性能,确保在一个阶段处理时,其他阶段不会空闲。
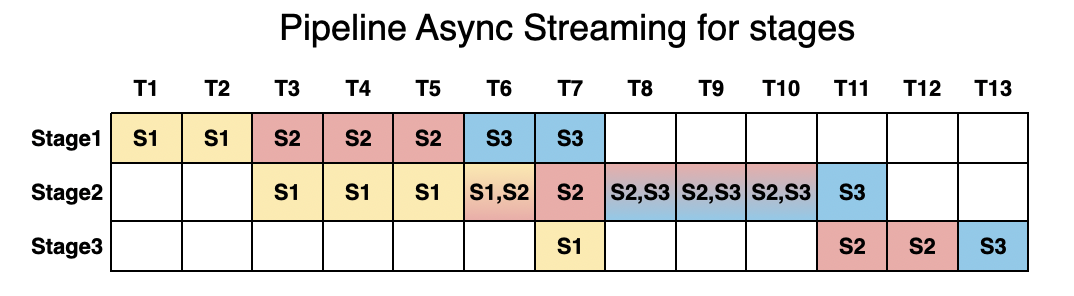
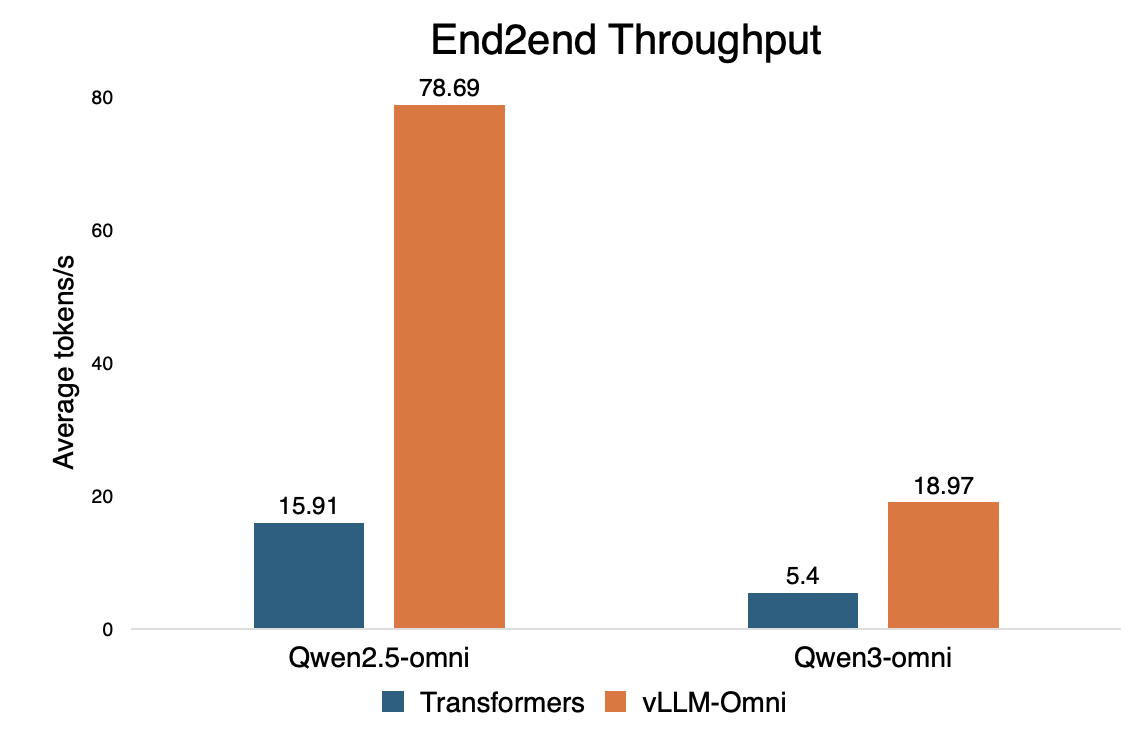
我们将 vLLM-Omni 与 Hugging Face Transformers 进行了基准测试,以展示在全模态服务中的效率提升。
未来路线图
vLLM-Omni 正在快速发展。我们的路线图专注于扩展模型支持,并进一步推动高效推理的边界,同时构建正确的框架以赋能未来关于全模态模型的研究。
- 扩展模型支持:我们计划支持更多新兴的开源全模态模型和扩散变换器。
- 自适应框架优化:我们将继续演进和改进框架,以支持新兴的全模态模型和执行模式,确保它始终是生产工作负载和前沿研究的可靠基础。
- 更深度的 vLLM 集成:将核心的全模态特性合并到上游,使多模态成为整个 vLLM 生态系统中的一等公民。
- 扩散加速:并行推理(DP/TP/SP/USP…)、缓存加速(TeaCache/DBCache…)和计算加速(量化/稀疏注意力…)。
- 完全解耦:基于 OmniStage 抽象,我们期望在不同的推理阶段(编码/预填充/解码/生成)支持完全解耦,以提高吞吐量并减少延迟。
- 硬件支持:遵循硬件插件系统,我们计划扩展对各种硬件后端的支持,以确保 vLLM-Omni 在任何地方都能高效运行。
开始使用
开始使用 vLLM-Omni 非常简单。首个 vllm-omni v0.11.0rc 版本是基于 vLLM v0.11.0 构建的。
安装
请查看我们的安装文档以获取详细信息。
服务全模态模型
请查看我们的示例目录,获取启动图像、音频和视频生成工作流的具体脚本。vLLM-Omni 还提供了 gradio 支持以改善用户体验,以下是服务 Qwen-Image 的一个演示示例。

加入社区
这仅仅是全模态服务的开始。我们正在积极开发对更多架构的支持,并邀请社区帮助塑造 vLLM-Omni 的未来。
- 代码与文档: GitHub 仓库 - 文档
- Slack:在 slack.vllm.ai 的
#sig-omnislack 频道中提问和提供反馈。 - 每周会议:欢迎在每周二太平洋夏令时 19:30 加入我们,讨论路线图和功能。在此加入。
让我们一起共建全模态服务的未来!