共享内存 IPC 缓存:加速 LLM 推理系统中的数据传输
说明
原文发布于 Cohere 博客。
隆重推出共享内存 IPC 缓存——这是 Cohere 为 vLLM 项目贡献的一种高性能缓存机制。通过绕过冗余的进程间通信(IPC)并将大型多模态输入保存在共享内存中,它显著降低了数据传输开销,从而实现了在规模化场景下更快、更高效的 LLM 推理。
现代 LLM 推理通常涉及多个进程协同工作,并通过进程间通信(IPC)进行沟通。随着并行规模的扩大和输入内容(例如多模态数据)的日益丰富,IPC 开销很快就会成为主要的性能瓶颈。
借助共享内存 IPC 缓存,我们可以显著减少单个节点上进程间的冗余数据传输。我们的基准测试表明:
- 首次请求:预填充吞吐量提升了 11.5%,首个令牌时间(TTFT)降低了 10.5%
- 缓存请求(KV 和图像输入均被复用):预填充吞吐量提升了 69.9%,TTFT 下降了 40.5%。这些性能提升主要源于消除了进程间的冗余 IPC 传输。
此外,这种优势会随着输入大小和张量并行(TP)规模的增加而扩大:更大的输入和更宽的 TP 配置会带来更繁重的 IPC 流量,使得共享内存缓存对于大型多模态工作负载的影响更加显著。
LLM 推理中的进程间通信
在一个典型的多进程 LLM 推理技术栈中,主要有三个组件:前端,负责处理和预处理用户请求;协调器,负责管理调度和编排;以及推理工作进程,负责运行模型计算。
下图展示了在一个使用四块 GPU 的 LLM 推理系统中,各个进程如何协调工作。前端将输入数据发送给协调器,协调器再将其路由到四个工作进程(每个 GPU 一个)以执行推理。
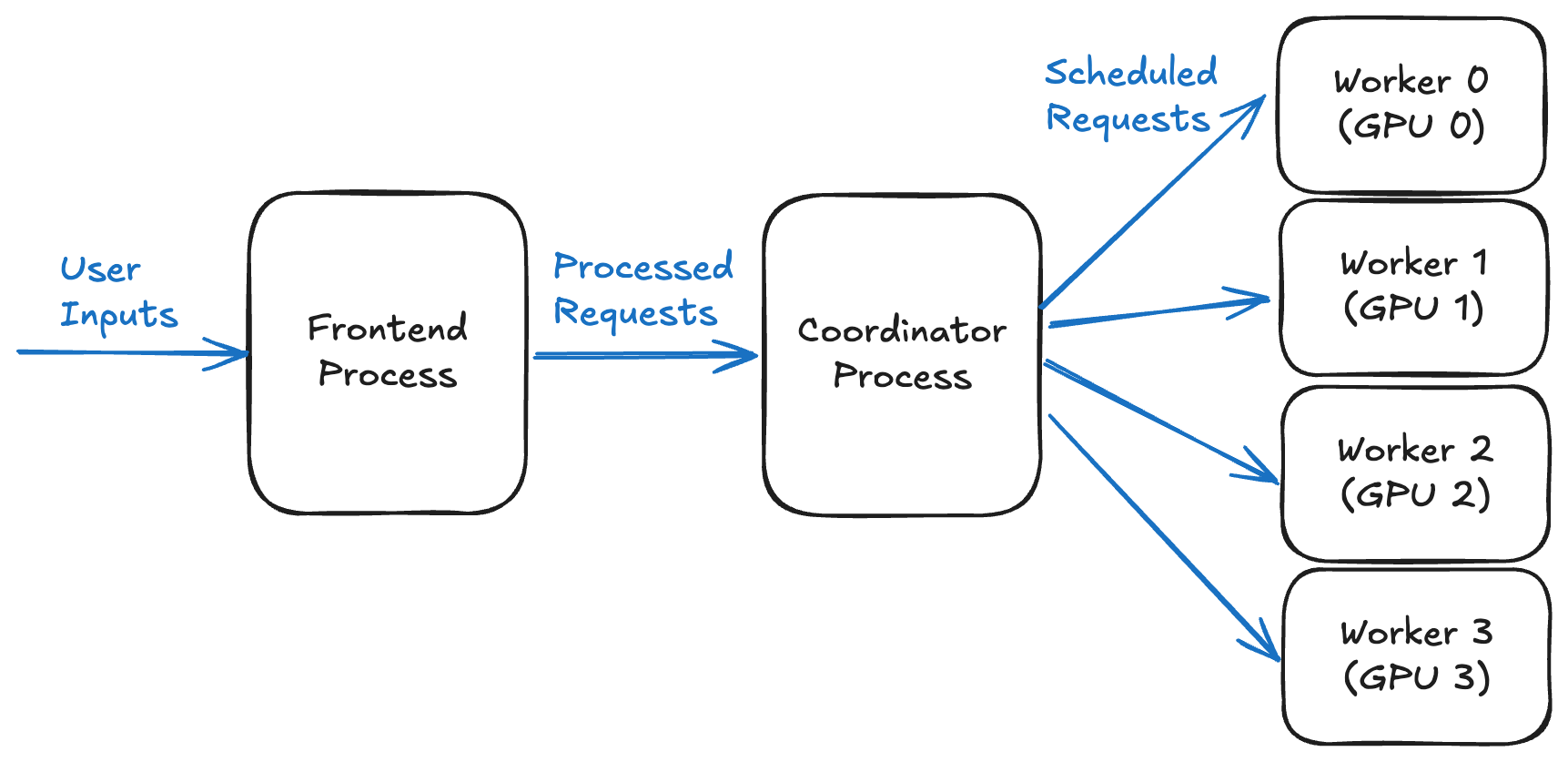
图 1. 使用四块 GPU 的 LLM 推理系统中的进程协调概览
每个阶段通常在独立的进程中运行,以实现可扩展性和异步执行。因此,数据必须通过 IPC 在这些进程之间流动。对于小输入,这种开销可以忽略不计,但随着输入变大,IPC 时间可能成为一个主要瓶颈。
问题:重复的大数据传输
多模态输入,如图像、音频或长上下文序列,可能非常巨大。例如,在 CohereLabs/command-a-vision-07-2025 模型中,一张最大尺寸的 1024×3072 像素输入图像,当表示为 int8 数组时,大约为 9 MB。该模型还可以接受多张图像作为输入,因此每个请求的总大小可以轻松达到几十兆字节。
通过 IPC 在进程间传输如此大的输入并非没有成本。在多轮对话或批处理中,相同的输入可能会被多次传输,进一步加剧了开销。
现有解决方案:镜像缓存
vLLM 已经使用镜像缓存来减少冗余的 IPC 传输。在这种方法中,发送方和接收方都维护一个遵循相同插入顺序和淘汰策略的复制缓存。当发送方检测到某个输入的缓存命中时,它会假设接收方的缓存处于相同状态,从而跳过 IPC 传输。
然而,这种方法有一个关键限制:它依赖于严格的输入顺序,即发送方和接收方必须以完全相同的序列处理输入。例如,在一个典型的前端-协调器-工作进程设置中,如果镜像缓存部署在工作进程上,协调器可能会根据其调度策略重新排序输入,导致缓存不同步,并可能引发不正确的行为。
因此,在 vLLM 中,镜像缓存仅应用于前端与协调器之间的通信。对于协调器与工作进程之间的路径,当只有一个工作进程时,vLLM 会将其与协调器置于同一进程中,从而消除了额外的 IPC 需求。但当涉及多个工作进程时,vLLM 会退回到基于套接字的 IPC,这会因序列化、传输和反序列化而产生额外开销。
一种新方法:共享内存 IPC 缓存
为了克服传统 IPC 缓存的局限性,我们引入了共享内存 IPC 缓存。现在,发送方和接收方可以直接访问一个单一的共享缓存,从而消除了对顺序的假设和冗余的数据拷贝。
共享内存对象存储
我们实现了一个共享内存对象存储(Shared Memory Object Store)数据结构来实现这种缓存,允许一个写入实例和多个读取实例高效地共享同一内存缓冲区。
设计
- 写入方:将输入对象插入共享的环形缓冲区,更新地址索引,并将该地址广播给所有感兴趣的读取方
- 读取方:使用提供的地址直接从共享内存中访问对象
下图展示了使用共享内存对象存储的 IPC 缓存机制。发送进程维护一个写入实例,而每个接收进程都有一个对应的读取实例。
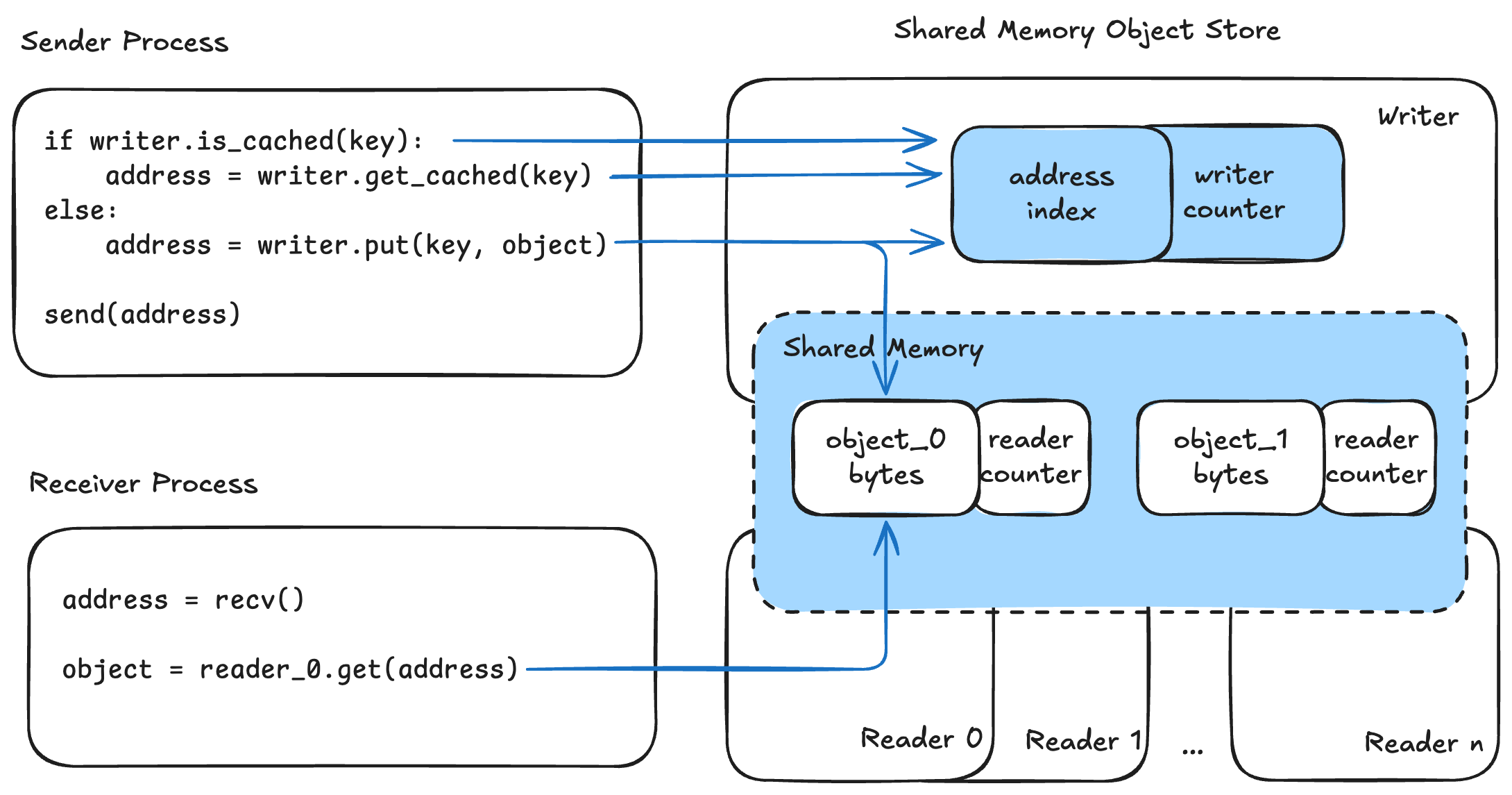
图 2. 使用共享内存对象存储的 IPC 缓存示意图
在发送一个键-对象对时,发送方首先通过 is_cached(key) 检查该键是否已缓存。如果已缓存,写入方使用 get_cached(key) 获取缓冲区地址;否则,它将对象用 put(key, object) 存储到共享内存中并获得缓冲区地址。然后,发送方通过默认的 IPC 将此地址广播给所有接收方。
在接收方,地址被接收后,对象通过 get(address) 从共享内存中获取。为简化说明,此处省略了序列化和反序列化步骤。
淘汰与安全
当空间不足时,写入方会从环形缓冲区的头部开始淘汰数据。读取方计数器(共享)和写入方计数器(本地)协同工作,以防止在数据仍在使用时被过早淘汰。只有当条件 writer_counter × n_readers == reader_counter 满足时,一个条目才会被淘汰。
优势
- 无顺序假设:进程可以按任意顺序消费输入
- 单一共享缓存:无论有多少个读取方,共享内存的使用量保持不变。
- 高效的并发访问:多个读取方可以同时读取相同的输入,同步开销极小,且无需额外的数据拷贝。
将共享内存对象存储应用于我们之前的前端-协调器-工作进程设置中,我们将写入方放置在前端进程,并在每个工作进程中放置一个专用的读取方。这使我们能够绕过中间的 IPC,特别是对于大型输入数据。

图 3. 由共享内存对象存储支持的 LLM 推理系统中的进程协调概览
vLLM 基准测试结果
我们通过一个 PR 在 vLLM 中为多模态输入实现了共享内存 IPC 缓存。为了评估其影响,我们使用了以下配置进行了基准测试:
- 模型:
CohereLabs/command-a-vision-07-2025 - 硬件:4× A100 (80GB, TP=4)
- 数据集:VisionArena-Chat
以下是测试结果:
首次请求
| 指标 | 基线 | 共享内存 IPC 缓存 | 差异 |
|---|---|---|---|
| 预填充吞吐量 | 581.34 tok/s | 648.22 tok/s | +11.5% |
| 平均 TTFT | 3898.98 ms | 3491.15 ms | −10.5% |
速度提升来自于前端只需写入一次,而工作进程可以并发读取,从而消除了冗余传输和 IPC 排队延迟。
缓存请求
| 指标 | 基线 | 共享内存 IPC 缓存 | 差异 |
|---|---|---|---|
| 预填充吞吐量 | 2894.03 tok/s | 4917.57 tok/s | +69.9% |
| 平均 TTFT | 790.18 ms | 470.60 ms | −40.5% |
在这种情况下,KV 和图像输入都被缓存,使得减少 IPC 开销带来的优势尤为明显。
立即开始使用
共享内存 IPC 缓存加速了 LLM 系统中的数据流动,使其更精简、更具可扩展性——尤其适用于包含大型多模态输入或多个并发 GPU 工作进程的工作负载。除了 LLM 推理,它还能在任何 IPC 缓存有助于减少冗余数据传输的场景中提升性能,使其成为适用于广泛应用的通用工具。
该功能现已在 vLLM 的 main 分支上可用。要为多模态缓存启用它,请设置 mm_processor_cache_type = "shm"。更多信息请参阅 vLLM 用户指南。
致谢
特别感谢 Cohere 的 Bharat Venkitesh 以及 vLLM 社区的成员:Cyrus Leung,为代码审查和集成提供了宝贵的反馈;Nick Hill 和 Roger Wang,在早期概念验证阶段给予了帮助;以及 Kero Liang,报告并帮助修复了一个错误。