告别训练与推理不匹配:使用 vLLM 和 TorchTitan 实现比特级一致的同策略强化学习
我们展示了一个开源的、比特级一致的同策略(on-policy)强化学习运行流程,其中使用 TorchTitan 作为训练引擎,vLLM 作为推理引擎。基于 vLLM 近期在批处理不变性推理方面的工作,我们在我们开源的指南中展示了如何对 Qwen3 1.7B 进行强化学习微调,并实现训练和推理数值上的比特级匹配。
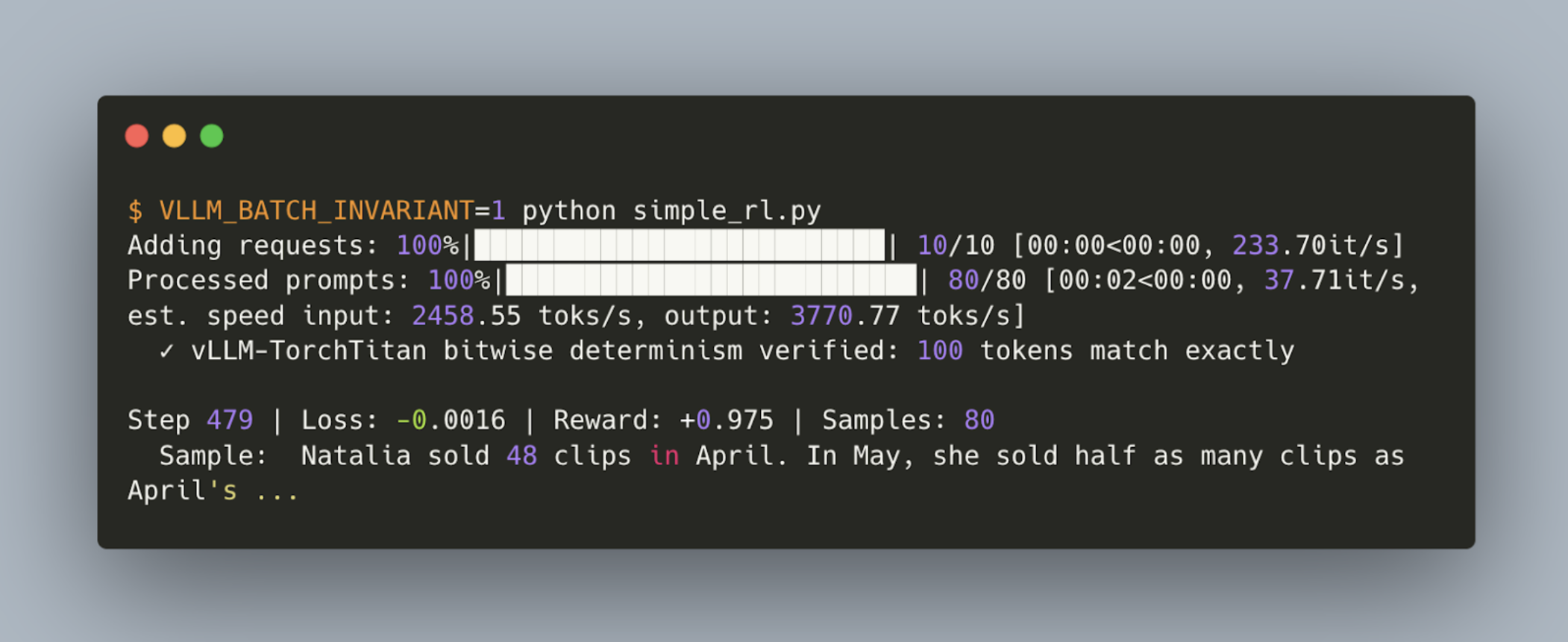
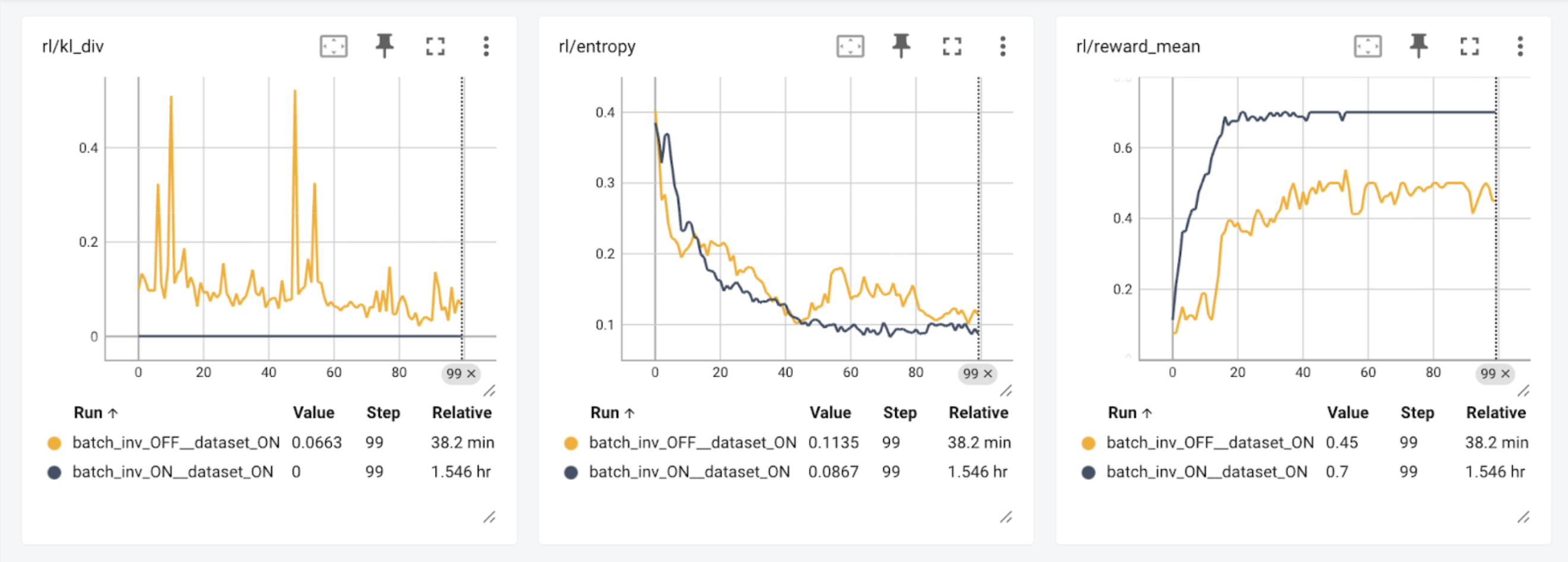
研究表明,强化学习会放大训练器和采样器之间微小的数值差异,导致不确定和不稳定的训练行为(He et al., Yao, Liu et al. & Liu, Li et al.)。我们的实验结果验证了数值计算对强化学习结果的影响:当采样器使用与训练器不同的核函数时(batch_inv_OFF),在 100 个步骤后奖励值降低。启用比特级精确训练后(batch_inv_ON,此时 kl_div 始终为 0.0),我们观察到模型不仅训练步数减少,而且达到了更高的总奖励。
方法
由于工作负载特性的不同,训练和推理框架通常使用截然不同的核函数。即使在同一个推理框架内,也会针对不同场景选择不同的核函数:高批量大小的核函数在批量维度上进行大量并行化,而低批量大小的核函数则在单个实例内进行更多并行化,以更好地利用 GPU 上的并行核心。所有这些差异都会导致训练和推理框架之间的数值差异,从而降低强化学习的效果。
在这项工作中,我们解决了两个不同框架之间的不变性问题:TorchTitan 作为训练框架,vLLM 作为推理框架。我们审查了前向传播过程中每个核函数的每一次调用,以确保它们在两个框架之间是比特级等价的。我们利用了 vLLM 近期在批处理不变性方面的工作中的前向传播核函数,并为这些操作编写了简单的反向传播过程。
vLLM 拥有许多高度优化的融合操作,例如 SiLU MLP 和 RMSNorm(带有残差连接)。为了保持比特级等价,我们为前向传播引入了完全相同的操作。这些操作需要注册自定义的反向传播过程,而这可以在编写 TorchTitan 的原生 PyTorch 中完成。
对于强化学习演示,我们使用 GSM8K 和一个正确性奖励编写了一个通用的强化学习脚本。我们使用了 TorchTitan 的实用工具来构建训练器,并编写了一个自定义的生成器。我们的生成器 VLLMRolloutEngine 封装了诸如调用生成和更新权重等简单功能。我们在单个主机上同步运行所有过程,交替执行训练器和生成器。这展示了精确的同策略执行过程,但在大规模运行中并不常见。
下一步计划
我们将继续推进比特级一致的训练和推理。要跟进这项工作,请查看相关的 RFC:#28326 和 #27433。具体来说,我们将专注于以下几个方向:
统一的模型定义。尽管我们已经展示了比特级等价的训练和推理结果,但模型代码仍然存在两份副本,一份用于训练,一份用于推理。这对于我们初次集成来说很简单,但对于长期维护而言却很脆弱:对任何一份模型代码的微小改动都会破坏训练和推理之间的等价性,并导致数值不匹配。为训练和推理框架提供共享的模型代码将消除引入人为错误的可能性,并使比特级匹配特性更容易维护。
编译支持。目前,我们没有对 TorchTitan 模型使用 torch.compile,因此强制 vLLM 使用 Eager 模式。移除这个限制并不复杂,但需要构建一个 torch.compile 版本的 TorchTitan 模型。vLLM 大量使用了 torch.compile 并能借此保持批处理不变性——但要保持跨框架的兼容性,则需要对训练版本的模型进行修改。这将在后续工作中进行。
强化学习性能。我们目前的结果显示,比特级强化学习的运行速度比非比特级的情况慢 2.4 倍。我们将通过更好地调整批处理不变性核函数,以及利用编译等技术,继续提高 vLLM 的性能。
更广泛的模型支持。我们计划将这个比特级一致的强化学习框架从 Qwen3 1.7B 扩展到支持其他开源模型。我们还将泛化审计工具和反向传播的实现,以覆盖更广泛的操作符类型,使比特级训练-推理一致性成为一个可扩展且可复用的特性。
如果您感兴趣或希望做出贡献,请加入以下 Slack 频道:
作者:Bram Wasti, Wentao Ye, Teja Rao, Michael Goin, Paul Zhang, Tianyu Liu, Natalia Gimelshein, Woosuk Kwon, Kaichao You, Zhuohan Li