在 vLLM 上运行采用 NVIDIA Nemotron 的多模态推理智能体
我们很高兴发布由 vLLM 支持的 NVIDIA Nemotron Nano 2 VL。这款开放的视觉语言模型 (VLM) 专为视频理解和文档智能而构建。
Nemotron Nano 2 VL 采用 Transformer–Mamba 混合设计,在保持最先进的多模态推理精度的同时,提供了更高的吞吐量。该模型还采用了高效视频采样 (EVS) 技术,这是一种新技术,可以减少视频工作负载中冗余令牌的生成,从而以更高的效率处理更多视频。
在本博文中,我们将探讨 Nemotron Nano 2 VL 如何推动视频理解和文档智能的发展,展示真实世界的用例和基准测试结果,并指导您开始使用 vLLM 进行推理,以大规模解锁高效的多模态人工智能。
领先的多模态模型,实现高效的视频理解和文档智能
NVIDIA Nemotron Nano 2 VL 在一个高效的模型中同时集成了视频理解和文档智能两种能力。它基于 Transformer–Mamba 混合架构,结合了 Transformer 模型的推理能力和 Mamba 的计算效率,实现了高吞吐量和低延迟,使其能够更快地处理多图像输入。
Nemotron Nano 2 VL 使用 NVIDIA 精心筛选的高质量多模态数据进行训练,在 MMMU、MathVista、AI2D、OCRBench、OCRBench-v2、OCR-Reasoning、ChartQA、DocVQA 和 Video-MME 等视频理解和文档智能基准测试中表现领先,在多模态推理、字符识别、图表推理和视觉问答方面提供顶级的准确性。这使其成为构建多模态应用的理想选择,这些应用能够以企业级的精度自动从视频、文档、表单和图表中提取和理解数据。
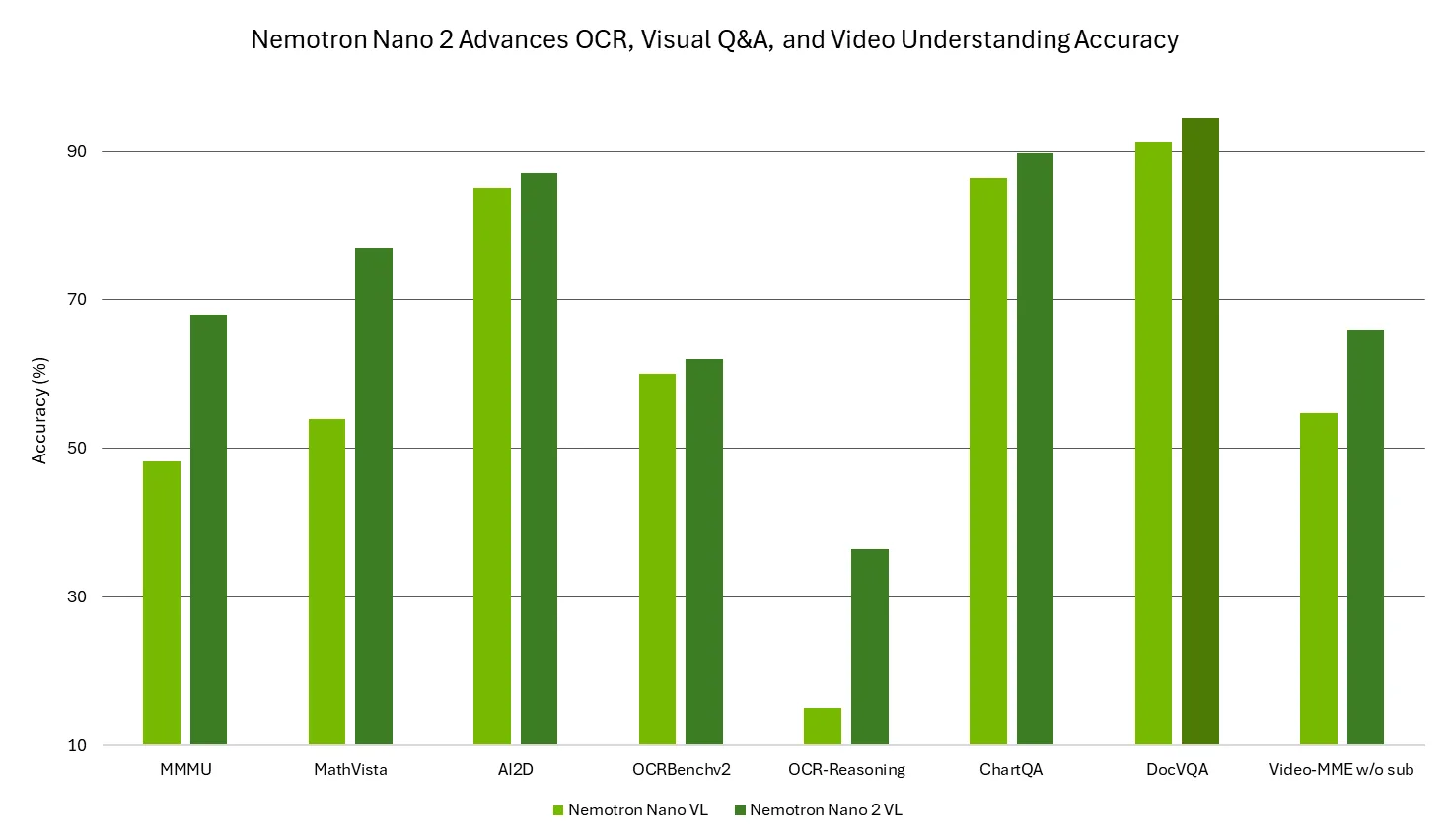
图 1:Nemotron Nano 2 VL 在各种视频理解和文档智能基准测试中提供领先的准确性
通过 EVS 提高效率
借助 EVS,该模型在不牺牲准确性的前提下实现了更高的吞吐量和更快的响应时间。EVS 技术可以裁剪冗余帧,在保留语义丰富性的同时,高效地处理更长的视频。因此,企业可以在几分钟内分析数小时的影像资料,包括会议、培训课程和客户通话,从而以更低的成本更快地获得可行的见解。
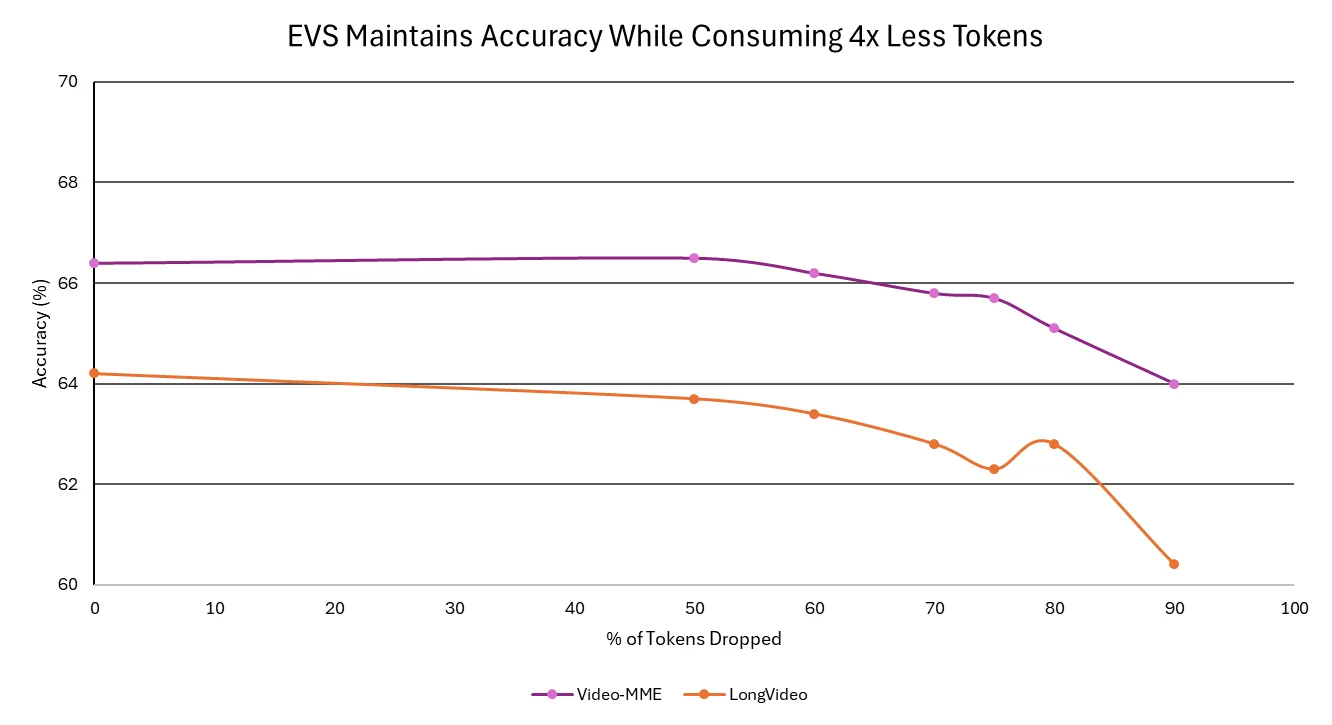
图 2:在 Video-MME 和 LongVideo 基准测试中,使用高效视频采样技术,Nemotron Nano 2 VL 模型在不同令牌丢弃阈值下的准确性趋势
关于 Nemotron Nano 2 VL
- 架构
- 基于 CRADIOH-V2 的视觉编码器
- 高效视频采样作为令牌压缩模块
- Transformer-Mamba 混合架构 - 具备推理能力的 Nemotron Nano 2 LLM 主干。
- 准确性
- 在 OCRBench v2 上具有领先的准确性
- 在以下基准测试中平均得分为 74 分(当前顶级的 VL 模型为 64.2 分):MMMU、MathVista、AI2D、OCRBench、OCRBench-v2、OCR-Reasoning、ChartQA、DocVQA 和 Video-MME
- 模型大小:12B
- 上下文长度:128k
- 模型输入:多图像文档、视频、文本
- 模型输出:文本
- 快速入门
使用 vLLM 运行优化推理
本指南演示了如何在 vLLM 上运行 Nemotron Nano 2 VL,通过支持 BF16、FP8 和 FP4 精度,实现加速推理并高效处理并发请求。
安装 vLLM
vLLM 的 nightly 版本已支持 Nemotron Nano 2 VL。运行以下命令安装 vLLM
uv venv
source .venv/bin/activate
uv pip install vllm --extra-index-url https://wheels.vllm.ai/nightly --prerelease=allow
部署和查询推理服务器
通过运行以下适用于 BF16、FP8 和 FP4 精度的命令,使用 vLLM 部署一个与 OpenAI 兼容的推理服务器
vllm serve nvidia/Nemotron-Nano-12B-v2-VL-BF16 --trust-remote-code --dtype bfloat16 --video-pruning-rate 0
# FP8
vllm serve nvidia/Nemotron-Nano-VL-12B-V2-FP8 --trust-remote-code --quantization modelopt --video-pruning-rate 0
# FP4
vllm serve nvidia/Nemotron-Nano-VL-12B-V2-FP4-QAD --trust-remote-code --quantization modelopt_fp4 --video-pruning-rate 0
服务器启动并运行后,您可以使用下面的代码片段向模型提问
from openai import OpenAI
client = OpenAI(base_url="https://:8000/v1", api_key="null")
# Simple chat completion
resp = client.chat.completions.create(
model="nvidia/Nemotron-Nano-12B-v2-VL-BF16",
messages=[
{"role": "system", "content": "/no_think"},
{"role": "user", "content": [
{"type": "text", "text": "Give me 3 interesting facts about this image."},
{"type": "image_url", "image_url": {"url": "https://blogs.nvidia.com/wp-content/uploads/2025/08/gamescom-g-assist-nv-blog-1280x680-1.jpg"}
}
]},
],
temperature=0.0,
max_tokens=1024,
)
print(resp.choices[0].message.content)
更多示例,请查看我们的 vLLM 使用手册和 vLLM 上的 Nemotron Nano 2 VL 指南。
分享您的想法并为您认为重要的内容投票,以帮助塑造 Nemotron 的未来。
订阅 NVIDIA 新闻并关注 NVIDIA AI 在 LinkedIn、X、YouTube 以及 Discord 上的 Nemotron 频道,以获取有关 NVIDIA Nemotron 的最新信息。