vLLM 现已支持 NVIDIA Nemotron
能够推理、规划和自主行动的智能体 AI 系统正在推动开发者应用的下一次飞跃。要构建这些系统,开发者需要开放、高效且可随时扩展的工具。并且,随着对智能体需求的增长,开放、高性能的模型是关键,因为它们提供了透明度、适应性和成本控制。
NVIDIA Nemotron 是一个包含开放模型、数据集和技术的系列,旨在帮助开发者为专业的智能体 AI 构建高效、准确的模型。
vLLM 现已支持 NVIDIA Nemotron
vLLM 为部署 NVIDIA Nemotron 开放模型系列提供了一条无缝路径,让开发者能够在数据中心和边缘硬件上启动高准确度的智能体推理,并针对吞吐量和准确性进行了优化。Nemotron 模型使用开放权重和开放数据,可直接通过 vLLM 进行部署,用于可复现的生产级智能体。
NVIDIA Nemotron Nano 2
该系列的最新成员是 NVIDIA Nemotron Nano 2,这是一款高效的小型语言推理模型,采用了 混合 Transformer–Mamba 架构和可配置的“思考预算”(thinking budget)。这使得开发者可以调整准确性、吞吐量和成本,以满足其现实世界应用的需求。
-
开放:该模型可在 Hugging Face 上获取,为推理、编码以及包括指令遵循、工具调用和长上下文聊天在内的各种智能体任务提供了领先的准确性。超过 9 万亿 token 的预训练和后训练数据也已在 Hugging Face 上发布,这些数据由 NVIDIA 生成和整理,并采用非常宽松的许可证。
-
高效:得益于其混合架构,Nemotron Nano 2 使用 vLLM 生成关键思考 token 的速度比同等规模的次优开放密集模型快 6 倍。更高的吞吐量使模型能够更快地思考,探索更大的搜索空间,进行更好的自我反思,并提供更高的准确性。
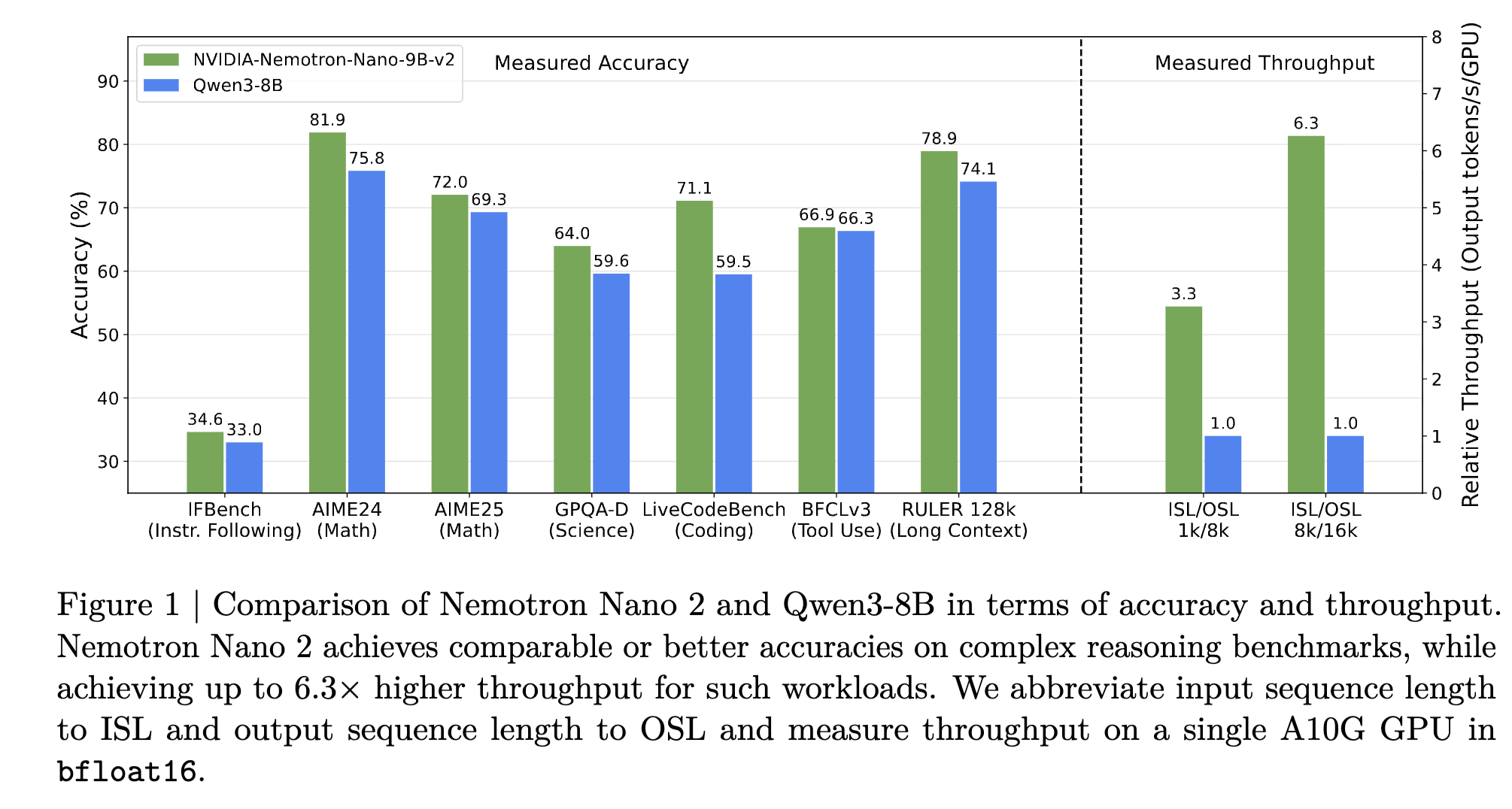
图 1:图表显示 Nemotron Nano 2 9B 在各种流行基准测试中的准确性
- 优化思考:该模型具有一项名为“思考预算”的新功能,可避免智能体过度思考,并优化可预测的推理成本。下图显示,如果不加干预,模型可能会过度思考,增加推理成本,在某些情况下甚至会降低准确性。思考预算通过让开发者调整模型,为其应用实现准确性与 token 生成的最佳平衡点,从而解决了这一挑战。
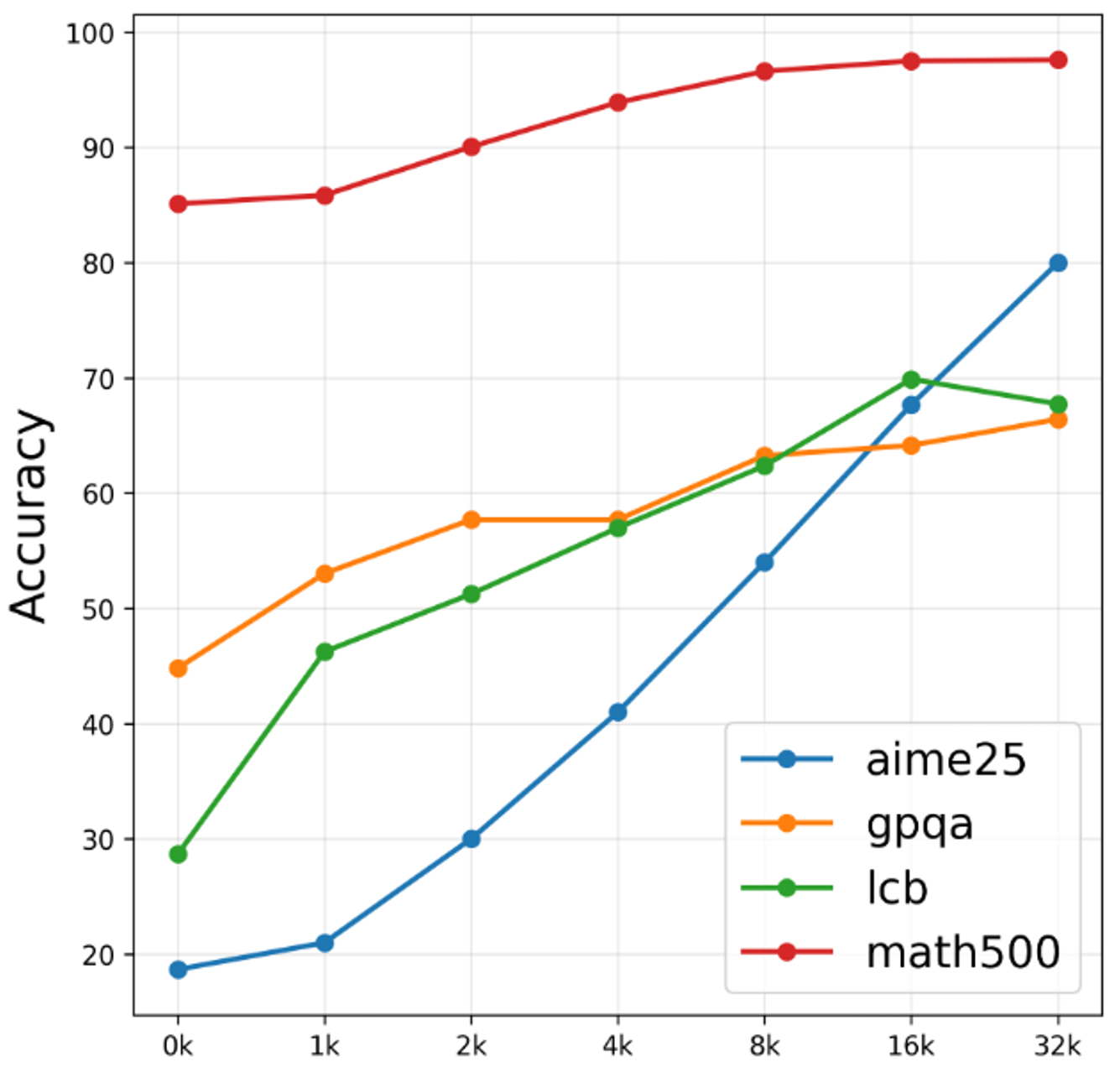
图 2:图表显示 Nemotron Nano 2 9B 模型在不同“Token 预算”阈值下于流行基准测试中的准确性
使用 vLLM 开始体验 Nemotron
让我们使用 vLLM 来部署 Nemotron Nano 2 模型进行智能体推理。
vllm serve nvidia/NVIDIA-Nemotron-Nano-9B-v2 \
--trust-remote-code \
--mamba_ssm_cache_dtype float32
现在我们可以创建一个 ThinkingBudgetClient 来使用我们新创建的端点。这将有助于强制执行和解析上述的“思考预算”功能。使用 vLLM,这个过程非常简单——让我们开始吧!
from typing import Any, Dict, List
import openai
from transformers import AutoTokenizer
class ThinkingBudgetClient:
def __init__(self, base_url: str, api_key: str, tokenizer_name_or_path: str):
self.base_url = base_url
self.api_key = api_key
self.tokenizer = AutoTokenizer.from_pretrained(tokenizer_name_or_path)
self.client = openai.OpenAI(base_url=self.base_url, api_key=self.api_key)
def chat_completion(
self,
model: str,
messages: List[Dict[str, Any]],
max_thinking_budget: int = 512,
max_tokens: int = 1024,
**kwargs,
) -> Dict[str, Any]:
assert (
max_tokens > max_thinking_budget
), f"thinking budget must be smaller than maximum new tokens. Given {max_tokens=} and {max_thinking_budget=}"
# 1. first call chat completion to get reasoning content
response = self.client.chat.completions.create(
model=model, messages=messages, max_tokens=max_thinking_budget, **kwargs
)
content = response.choices[0].message.content
reasoning_content = content
if not "</think>" in reasoning_content:
# reasoning content is too long, closed with a period (.)
reasoning_content = f"{reasoning_content}.n</think>nn"
reasoning_tokens_len = len(
self.tokenizer.encode(reasoning_content, add_special_tokens=False)
)
remaining_tokens = max_tokens - reasoning_tokens_len
assert (
remaining_tokens > 0
), f"remaining tokens must be positive. Given {remaining_tokens=}. Increase the max_tokens or lower the max_thinking_budget."
# 2. append reasoning content to messages and call completion
messages.append({"role": "assistant", "content": reasoning_content})
prompt = self.tokenizer.apply_chat_template(
messages,
tokenize=False,
continue_final_message=True,
)
response = self.client.completions.create(
model=model, prompt=prompt, max_tokens=remaining_tokens, **kwargs
)
response_data = {
"reasoning_content": reasoning_content.strip().strip("</think>").strip(),
"content": response.choices[0].text,
"finish_reason": response.choices[0].finish_reason,
}
return response_data
现在我们已经设置好了 ThinkingBudgetClient,可以发送一个请求并查看响应了!
tokenizer_name_or_path = "nvidia/NVIDIA-Nemotron-Nano-9B-v2"
client = ThinkingBudgetClient(
base_url="https://:8000/v1", # Nano 9B v2 deployed in thinking mode
api_key="EMPTY",
tokenizer_name_or_path=tokenizer_name_or_path,
)
result = client.chat_completion(
model="nvidia/NVIDIA-Nemotron-Nano-9B-v2",
messages=[
{"role": "system", "content": "You are a helpful assistant. /think"},
{"role": "user", "content": "What is 2+2?"},
],
max_thinking_budget=32,
max_tokens=512,
temperature=0.6,
top_p=0.95,
)
print(result)
我们看到的响应如下:
{'reasoning_content': 'Okay, the user asked "What is 2+2?" Let me think. This is a basic arithmetic question. The answer should be straightforward. I need.', 'content': '2 + 2 equals **4**. nnLet me know if you need help with anything else! 😊n', 'finish_reason': 'stop'}
vLLM 作为一个工具,通过使 Nemotron Nano 2 的部署更快、内存效率更高、并且更容易为实时智能体用例进行扩展,从而改进了其部署。此外,vLLM 对高效 KV 缓存管理和长上下文用例的关注,与 Nemotron Nano 2 的混合 Transformer-Mamba 架构相得益彰。
如果您想了解更多关于如何利用 Nemotron Nano 2 的信息,可以查看其模型卡片。如果您想开始使用 vLLM,请查阅快速入门文档。
随处运行
Nemotron 模型被配置为可在所有 GPU 加速系统上运行,因此您可以从开发无缝过渡到生产。
您可以在 NVIDIA 托管的端点 build.nvidia.com 上试用该模型,或从 Hugging Face 下载。
分享您的想法并为您认为重要的内容投票,以帮助塑造 Nemotron 的未来。
通过订阅 NVIDIA 新闻并关注 NVIDIA AI 的 LinkedIn、X、YouTube,以及 Discord 上的 Nemotron 频道,随时了解 NVIDIA Nemotron 的最新动态。