vLLM TPU:支持 PyTorch 和 JAX on TPU 的全新统一后端

vLLM TPU 现在由 tpu-inference 提供支持,这是一个富有表现力且功能强大的新型硬件插件,它在单一的底层转换路径下统一了 JAX 和 PyTorch。它不仅比上一代 vLLM TPU 更快,还提供了更广泛的模型覆盖和功能支持。vLLM TPU 是一个供开发者使用的框架,旨在
- 在开源领域挑战 TPU 硬件的性能极限。
- 为 JAX 和 PyTorch 用户提供更大的灵活性,使其能够在 TPU 上高性能地运行 PyTorch 模型定义,无需任何额外的代码更改,同时还将原生支持扩展到 JAX。
- 保持 vLLM 的标准化:维持相同的用户体验、遥测数据和接口。
vLLM TPU
2025 年 2 月,就在 vLLM 的 V1 集成刚刚成形之际,一个由谷歌员工和 vLLM 核心贡献者组成的“小而精”的团队为自己设定了一个目标:在 Cloud Next 2025 大会前,为少数几个模型推出一个高性能的 TPU 后端。在接下来的两个月里,他们遇到了几个挑战,主要是
- vLLM V1 集成:团队必须集成到新的 V1 代码路径中,这需要一个新的非定长分页注意力(ragged paged attention)内核(RPA v2)。这主要是为了支持像分块预填充(chunked prefill)和前缀缓存(prefix caching)等功能。虽然这些 KV 缓存管理技术在 TPU 上很常见,但以一种“TPU 友好”的方式将它们与 vLLM 的分页注意力结合设计是具有挑战性的。
- 多程序多数据(MPMD):当时,vLLM 专门使用 MPMD 来协调跨进程的通信。这与 TPU 以编译器为中心的编程模型形成鲜明对比,后者严重依赖单程序多数据(SPMD)来实现多设备和多主机通信的重叠。
- PyTorch/XLA(PTXLA):虽然使用 PyTorch/XLA 框架使得集成到 vLLM 变得更容易,因为它能够在 TPU 上原生运行 PyTorch 代码,但团队在优化技术栈的较低层次时遇到了一些挑战。
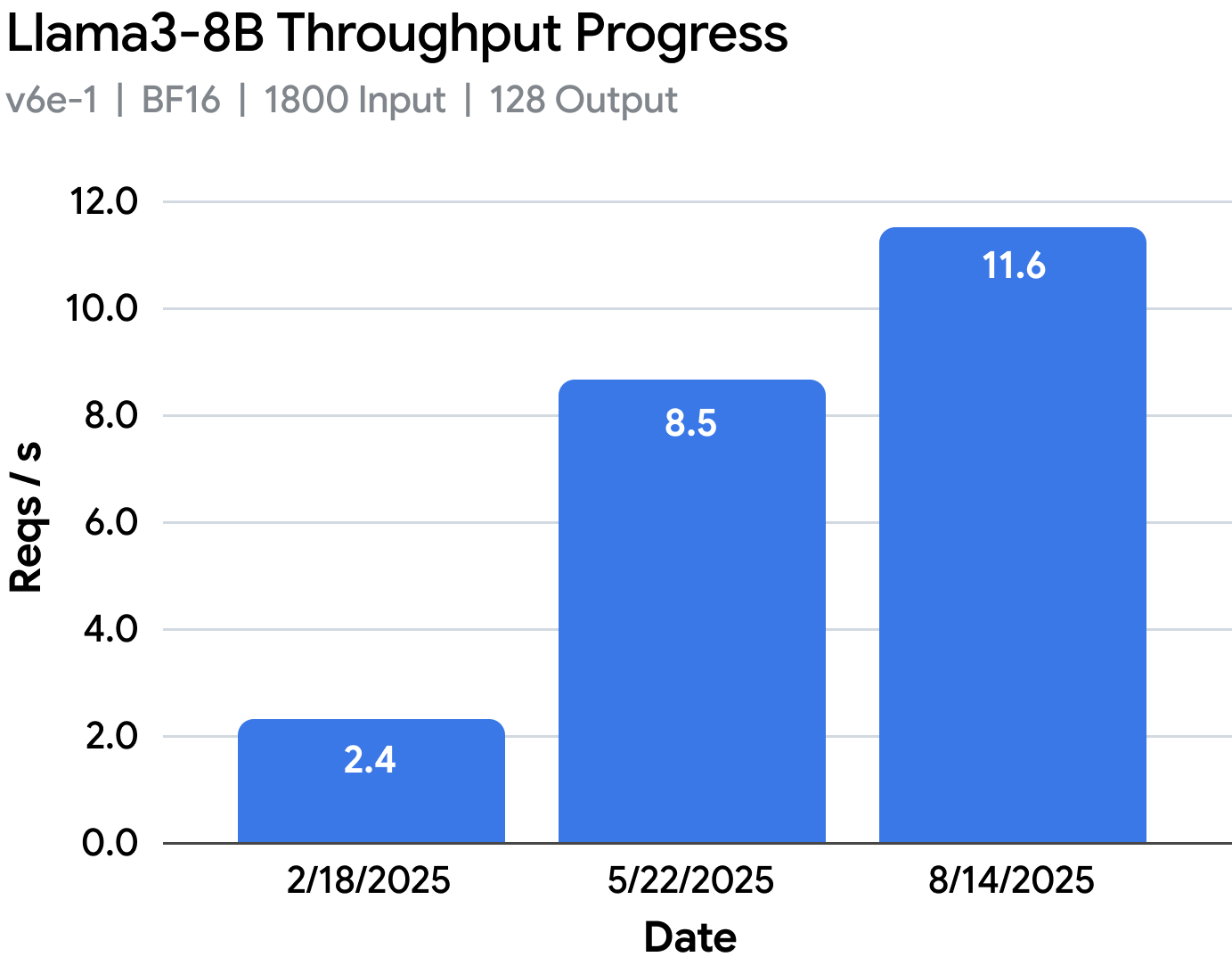
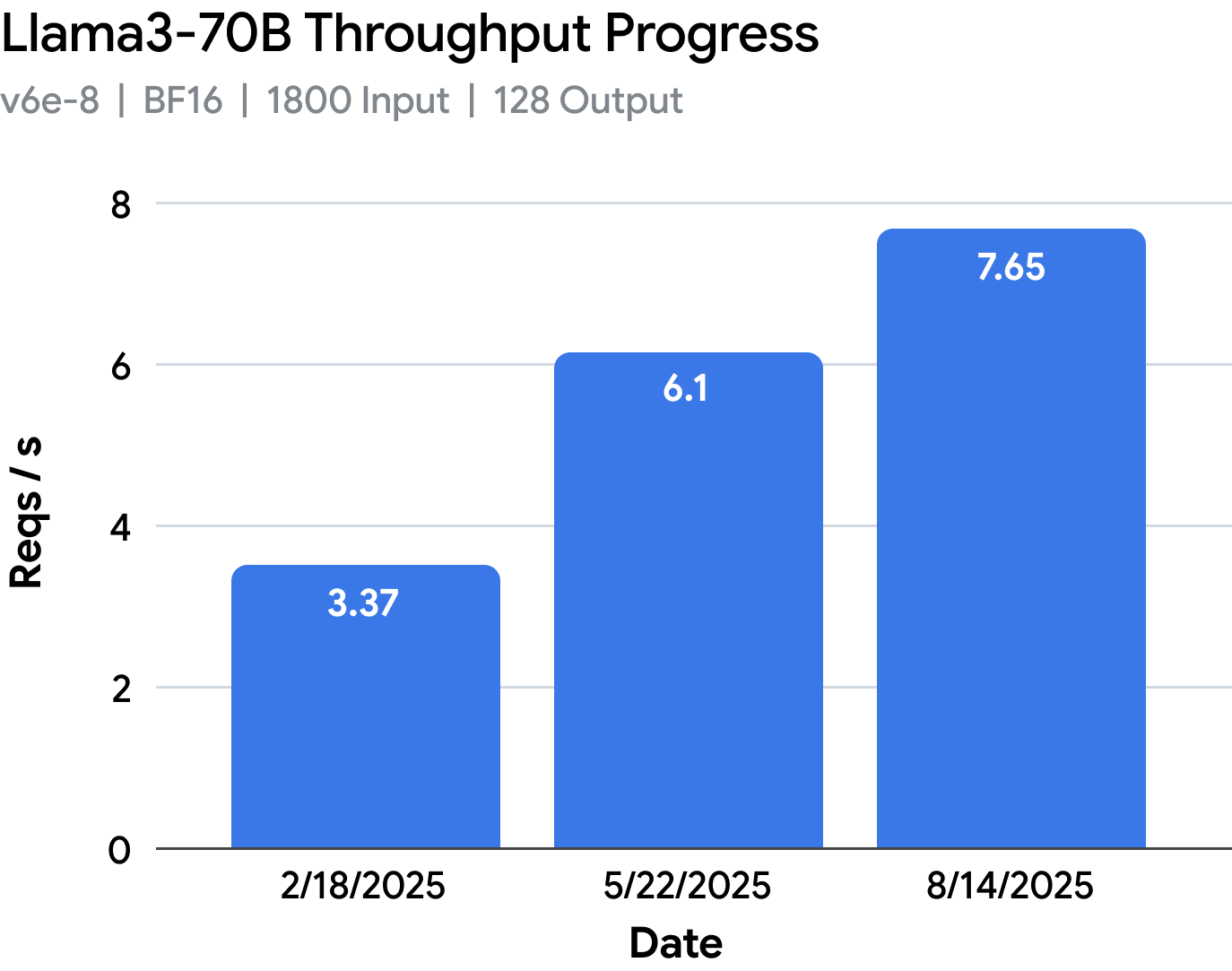
尽管存在这些障碍,团队还是将在 v6e-1 上的 Llama 3.1-8B 吞吐量性能提升了 3.6 倍,在 v6e-8 上的 Llama 3.1-70B 性能提升了 2.1 倍。vLLM TPU 也登上了 Cloud Next 的大舞台。您可以在此处查看这些工作负载的性能演进。
由 TPU-inference 驱动的 vLLM TPU
尽管带有 PTXLA 的 vLLM TPU 是一项重大成就,但我们需要继续在开源领域挑战 TPU 性能的极限。我们还希望通过以最高性能的方式在 TPU 上原生支持 PyTorch 和 JAX 模型,将 TPU 和 vLLM 生态系统结合在一起。
一个统一的 PyTorch 和 JAX 后端
这次 vLLM TPU 的重新设计采用了 tpu-inference,旨在通过在单一统一的 JAX→XLA 底层转换路径中支持 PyTorch(通过 Torchax)和 JAX 来优化性能和可扩展性。
与 PyTorch/XLA 相比,JAX 是一个更成熟的技术栈,通常为其原语提供更优的覆盖范围和性能,尤其是在实现复杂的并行策略时。
因此,vLLM TPU 现在使用 JAX 作为所有 vLLM 模型的底层转换路径,从中获得了显著的性能提升,即使模型定义是用 PyTorch 编写的。这一决定使我们能够更快、更智能地行动,将上层框架抽象出来,专注于内核开发和编译器优化。请记住,对于 XLA 来说,Torchax 和 JAX 在编译前使用相同的高性能原语。您可以在此处阅读更多相关信息。
虽然这是我们目前的设计,但我们将始终努力在 TPU 上实现最佳性能,并计划未来评估在 TPU 上为 vLLM TPU 进行原生 PyTorch 移植。
重要
要点 #1:vLLM TPU 现在使用 JAX 来处理所有模型的底层转换。无需对模型代码(例如 llama.py)进行任何更改,vLLM TPU 现在实现了约 20% 的吞吐量性能提升,这仅仅是因为它现在利用了 JAX 成熟的高性能原语来生成 HLO 图,然后由 XLA 编译。
深入了解
-
安装
pip install vllm-tpu # a single install path因为 Torchax 和 JAX 本质上都是 JAX,所以无论模型代码是用 PyTorch 还是 JAX 编写的,我们都可以利用相同的安装路径。这确保了依赖项保持一致,用户不必担心为不同模型管理不同的需求。
-
模型服务
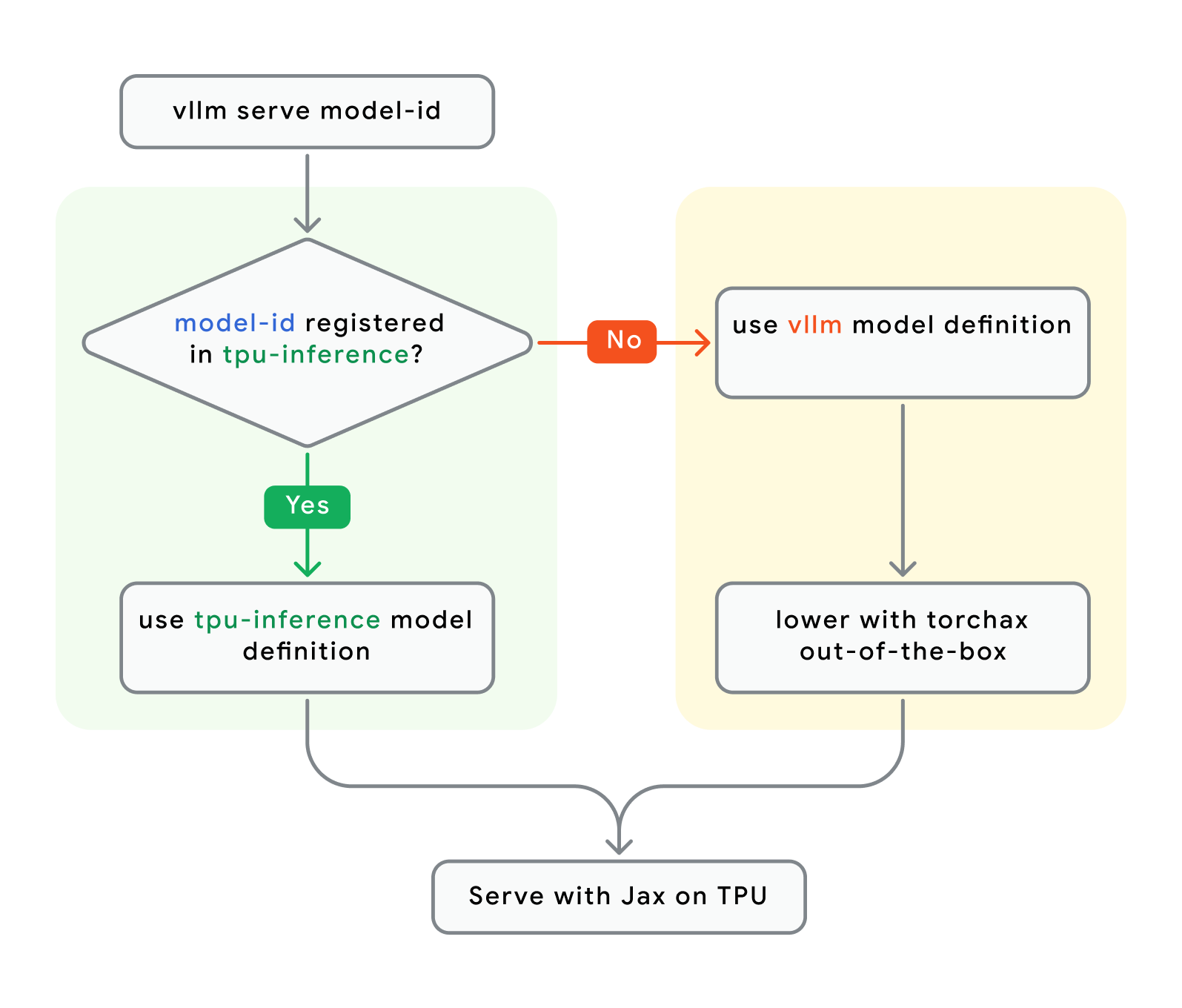
MODEL_ID="google/gemma3-27b-it" # model registered in tpu-inference or vllm vllm serve $MODEL_ID在 TPU 上提供模型服务时,可以从两个模型注册表中获取模型代码
让我们更深入地了解一下底层发生了什么
这项统一工作通过利用 vLLM 社区的现有工作减少了重复,为优化 TPU 内核和 XLA 编译器留出了更多时间。对于 PyTorch(通过 Torchax)和 JAX 模型,所有内核和编译器都是共享的。
重要
要点 #2:vLLM TPU 现在将默认运行 tpu-inference 中经过 TPU 优化的模型代码(如果存在),否则,它将回退到 vLLM 上游的 PyTorch 模型代码(使用 JAX 通过 Torchax 进行底层转换)。对于大多数用户来说,这是一个实现细节。
如果 Torchax 可以在 TPU 上开箱即用地运行 PyTorch 模型代码,但仍然使用 JAX JIT 进行编译,那么我们为什么要在 tpu-inference 中重写一些模型呢?这难道不是重复工作吗?
我们提供了一些参考模型(参见此处),以帮助开发者减少学习曲线,使他们能够尽快开始为 TPU 优化自己的模型。有趣的是,我们观察到,通过 torchax 底层转换的模型和简单地用 JAX 重新实现模型的性能大致相同,这表明 torchax 在转换高级模型方面的效率有多高。
真正的性能提升以及我们支持重写模型的原因,来自于为 TPU 优化 JAX 代码并直接利用 TPU 架构的优势。
我们需要这种灵活性的原因是,vLLM 开发者在实现模型时的逻辑设计选择并不总是有利于 TPU。这使得它们有所不同,不是因为 JAX 与 Torchax 的区别,而是因为 GPU 与 TPU 不同,需要不同的优化策略。
重要
要点 #3:对于任何模型,底层都是 JAX!除非实现中的逻辑差异导致 TPU 性能下降,否则模型可能不会从用 JAX 原生重写中受益。尽管如此,如果这意味着我们可以充分利用 TPU 的性能,那么保留重写模型的灵活性是很重要的。
非定长分页注意力 V3:开源软件(OSS)中用于 TPU 推理的最灵活、最高性能的注意力内核
尽管非定长分页注意力 v2(Ragged Paged Attention v2)内核带来了显著的性能提升,但为了开箱即用地支持更多模型和用例,它需要变得更加灵活。
- RPA v2 只能支持头维度(head dim)为 128 的模型规格。
- 更多模型:RPA v3 更加灵活,支持任意模型规格、量化数据类型和任意张量并行(TP),从而开箱即用地解锁了更多模型。
- RPA v2 由于顺序执行 KV 缓存更新和注意力操作,导致流水线效率低下。
- 更好的性能:RPA v3 通过将 KV 缓存更新(scatter)融合到 RPA 内核中,提高了流水线效率。这种设计现在可以在内核执行期间完全隐藏 scatter 延迟。
- RPA v2 在解码密集型或不同长度的预填充任务中可能会造成严重的浪费。
- 改进的部署灵活性:RPA v3 将编译成 3 个子内核,从而支持纯预填充、纯解码和混合批处理。这种设计通过在运行时将正确的子内核与适当的请求配对,显著节省了直接内存访问(DMA)和计算资源。
- 这还带来了额外的好处,即解锁了更复杂的部署模式,如分解式服务。
- 尽管 RPA v2 相对于第一个 TPU 原型实现了显著的吞吐量提升,但它缺乏灵活性。
- 毫不妥协: RPA v3 并没有为了灵活性而牺牲性能,实际上,它在 Trillium(v6e)上的吞吐量比 RPA v2 提高了约 10%。现在模型也可以在 v5p 上运行(尽管需要额外调整)。
我们很快将撰写一篇关于 RPA v3 的技术深度剖析文章,敬请关注我们的文档。
重要
要点 #4:RPA v3 既灵活又高效,是开源软件(OSS)中生产级 Pallas 内核开发的绝佳参考。我们期待 TPU 友好的 MoE 和 MLA 内核很快能以类似的方式登陆开源社区。
单程序多数据(SPMD)
此版本引入了单程序多数据(SPMD)作为 vLLM TPU 的默认编程模型。与之前的多工作进程模型(改编自 GPU 范式)不同,SPMD 是 XLA 编译器的原生模型。开发者为单个巨型设备编写代码,XLA 编译器会自动对模型和张量进行分区,并插入通信操作以实现最优执行。
重要
要点 #5:SPMD 实现了诸如将通信与计算重叠等高级优化。SPMD 代表了向更深层次、更原生的 TPU 集成迈出的战略性转变,有望通过一个以 TPU 为中心、编译器优先的操作模型来提供更高的性能。
总结
|
|
vLLM TPU 自 2025 年 2 月的原型性能以来已经取得了长足的进步,在相同的工作负载上实现了近 2-5 倍的性能提升,同时还改进了模型覆盖范围和可用性。
重要
要点 #6:如今,vLLM TPU 的性能比 2025 年 2 月的第一个 TPU 原型高出近 5 倍。有了这个新的基础,开发者和研究人员现在将能够在开源领域将 TPU 推理性能推向新的高度。
模型、功能及未来展望
我们可以将此版本视为一个基础,因为 vLLM TPU 现在将定期在开源社区发布新版本。随着每个新版本的发布,CI/CD 将会发布经过审查的 vLLM 原生模型的文档化表格。我们还将维护一个经过压力测试的 tpu-inference 模型列表,主要作为 JAX 用户的参考。所有功能也将在发布前经过严格测试。
支持的模型系列
- 稠密模型
- 多模态模型(仅限 tpu-inference 模型)
说明
关于模型支持的说明:在我们提供更多功能之前,我们建议从此处的压力测试模型列表开始。我们仍在 tpu-inference 中添加组件,以提高更大规模、更复杂模型(XL MoE、+视觉编码器、MLA 等)的性能。如果您希望我们优先处理特定事项,请在此处提交 GitHub 功能请求。
已支持/验证的 TPU 代
- Trillium (v6e), v5e
功能
- 前缀缓存
- 分块预填充
- 多模态输入
- 单程序多数据 (SPMD)
- 结构化解码
- 推测解码:Ngram
- 外部模型支持
- 优化的运行时采样(top k, top p, temperature, logit 输出)
- 量化(权重、激活和 KV 缓存)
TPU 友好型内核
- 非定长分页注意力 V3
- 集体通信矩阵乘法
- 量化矩阵乘法、注意力和 KV 缓存
实验性功能
- v5p
- 多模态(通过 Torchax)
- 多 LoRA
- 推测解码:基于树的 Eagle 3
- 单主机 P/D 分解式服务
未来计划
- Sparsecore 卸载
- 推测解码:Eagle 3, MTP
- TPU 友好型内核
- XL MoE
- MLA
- 集成
- 欢迎贡献!
立即体验!
您可以在 Google Cloud 上进行尝试,包括 Google Kubernetes Engine (GKE)、Compute Engine 和 Vertex AI。有关安装说明和开发者指南,请查看以下资源
Google Cloud 教程:GKE:此处,Vertex AI:此处
致谢
我们衷心感谢 vLLM 社区在此项工作中持续给予的支持。特别感谢 Woosuk Kwon 率先实现了 TPU 的 V0 版本,并持续支持我们不断壮大的团队。我们还要特别感谢 Simon Mo、Robert Shaw、Michael Goin、Yanping Huang 在整个工作中提供的宝贵指导。同时,也特别感谢 Nicolo Lucchesi、Alexander Matveev、Akshat Tripathi 和 Saheli Bhattacharjee,他们是 V1 集成和为 Cloud Next 努力的重要组成部分。