SemiAnalysis InferenceMAX:vLLM 与 NVIDIA 共同加速 Blackwell 推理
引言
在过去的几个月里,我们一直与 NVIDIA 紧密合作,利用 vLLM 解锁其最新 NVIDIA Blackwell GPU 架构(B200/GB200)在大型语言模型推理方面的全部潜力。Blackwell GPU 引入了全新级别的性能和效率提升,例如更高的内存带宽和原生的 FP4 张量核心,为加速推理工作负载带来了激动人心的机遇。
Blackwell 开箱即用便能提供卓越的性能,但为了从硬件中榨取更多潜力,我们联合进行的优化重构了现有内核,并开发了专为更底层硬件利用率而设计的新内核,从而释放了额外的性能并提高了效率。新的 SemiAnalysis InferenceMAX 基准测试反映了这些增强功能,展示了 vLLM 在 Blackwell 上的出色性能,在 gpt-oss 120B 和 Llama 3.3 70B 等流行模型上,与上一代 Hopper GPU 相比,在相似延迟下实现了高达 4 倍的吞吐量。
这项工作是一次长达数月的工程合作,涉及 vLLM 代码库中的上百个拉取请求。我们与 NVIDIA 携手,优化了推理流程的几乎每个部分——从自定义内核(注意力、GEMM、MoE)到高级调度和开销移除。本博客将详细介绍这些优化,以及它们如何将 Blackwell 的架构特性转化为生产环境中的性能增益。
InferenceMax 概览
SemiAnalysis InferenceMax 是一个基准测试框架,专为自动化、周期性的 LLM 服务性能测试而设计,其结果每日更新以反映软件性能的变化。这种方法通过使用一致的测试方法论,确保了公平、可复现的比较,从而缩小了软件更新与已发布基准数据之间的时间差。
InferenceMAX 目前使用两个具有代表性的开源模型来评估 vLLM:
- 混合专家模型(MoE):gpt-oss 120B
- 密集模型(Dense):Llama 3.3 70B
为了模拟真实世界的使用情况,该基准测试在多种提示/响应长度场景下运行每个模型(ISL = 输入序列长度,OSL = 输出序列长度)。具体来说,测试涵盖了三种场景:
- 1K ISL / 1K OSL(聊天,中等输入/输出)
- 1K ISL / 8K OSL(推理,长输出)
- 8K ISL / 1K OSL(摘要,长输入)
在帕累托前沿上实现卓越性能
Blackwell 的全新计算架构在推理效率上实现了阶跃式提升,它集成了最新的 HBM3e 内存(每个 B200 拥有 192 GB HBM3e,速率为 8 TB/s)、高速 NVLink 数据传输速度(每个 GPU 为 1.8 TB/s),并通过第五代张量核心内置了对 FP4 精度格式的支持。
通过调整我们的内核以充分利用这些进步,我们看到与在上一代 Hopper 架构上运行 vLLM 相比,吞吐量(单 GPU 性能)和响应速度(单请求延迟)都取得了显著的增长。
现代推理工作负载在序列长度、批量大小和并发性方面差异很大。能够产生最高吞吐量的配置通常不是能为用户提供最低延迟的配置。因此,单一指标可能会产生误导。SemiAnalysis InferenceMAX 采用 帕累托前沿方法 来评估响应速度和吞吐量之间的权衡,描绘出 Blackwell 在真实世界操作条件下的性能包络。
我们与 NVIDIA 合作的主要目标是确保 vLLM 能够利用 Blackwell 的特性,在整个帕累托前沿上提供卓越的性能。
我们很高兴地看到,SemiAnalysis 的基准测试结果显示,对于 gpt-oss 120B 和 Llama 3.3 70B 模型,在所有交互级别上,vLLM 在 Blackwell 上的性能相比上一代 Hopper 架构都有一致的提升。
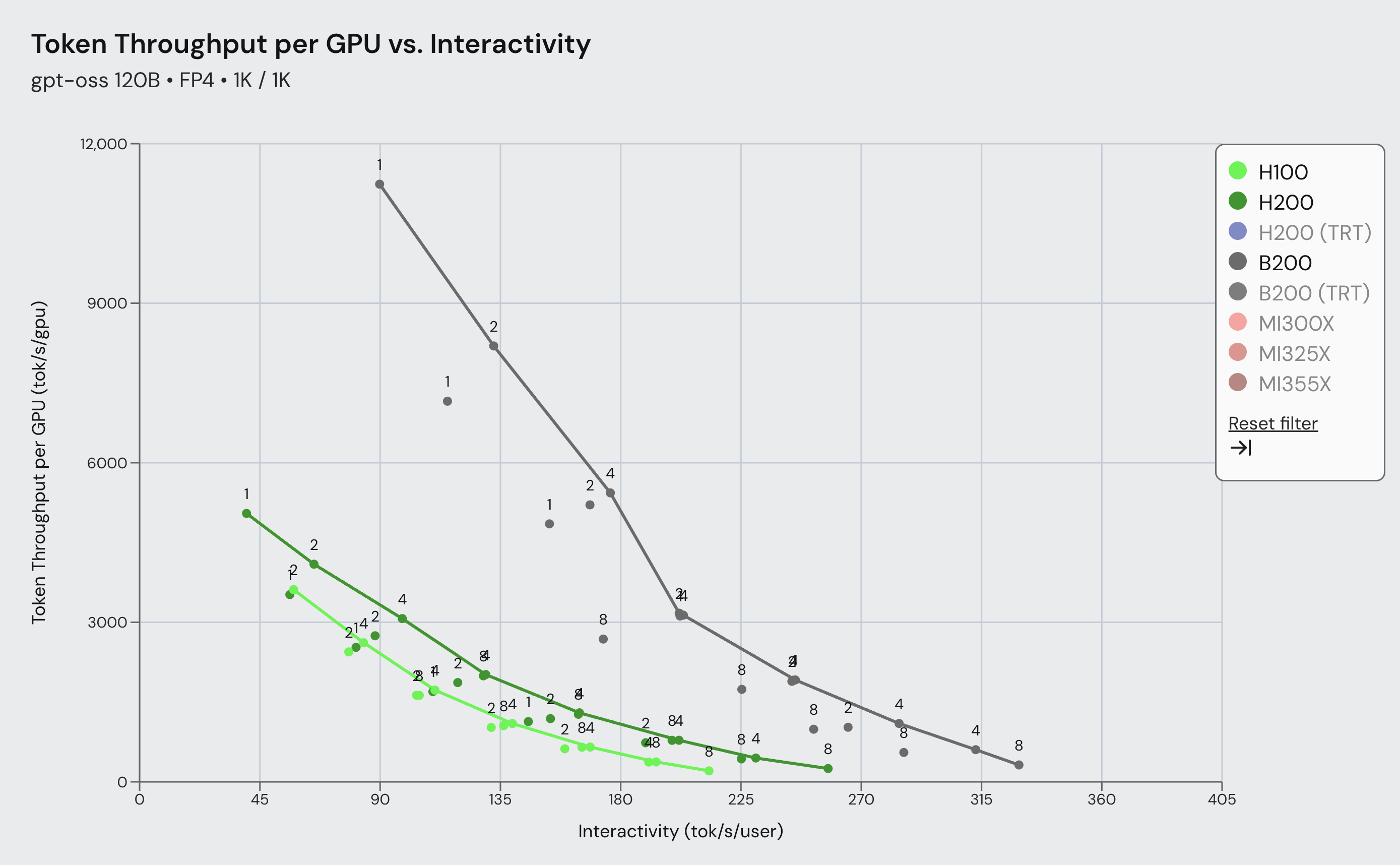
图 1:SemiAnalysis InferenceMax gpt-oss-120b 帕累托前沿,比较了 vLLM 在 Blackwell 和 Hopper 上于 1k/1k ISL/OSL 场景下,在广泛交互性范围内的性能。结果显示,在 Blackwell 上使用 vLLM 的吞吐量比 Hopper 高出 4.3 倍。
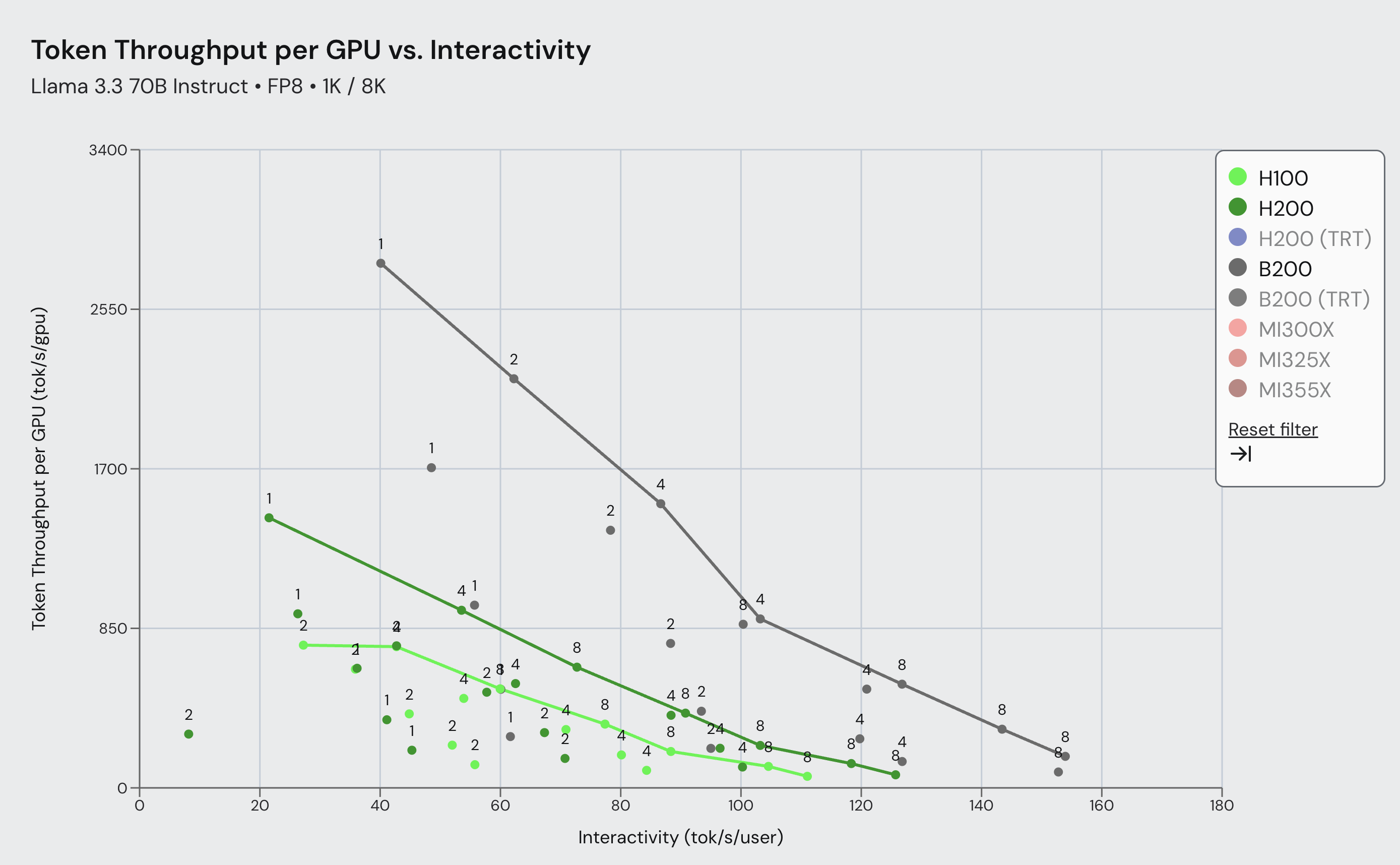
图 2:SemiAnalysis InferenceMax Llama 3.3 70B 帕累托前沿,比较了 vLLM 在 Blackwell 和 Hopper 上于 1k/8k ISL/OSL 场景下,在广泛交互性范围内的性能。结果显示,在 Blackwell 上使用 vLLM 的吞吐量比 Hopper 高出 3.7 倍。
这些性能增益如今即可复现,只需使用 SemiAnalysis 提供的 InferenceMAX 配置。这证明了当优化的软件专注于从硬件中榨取最大性能时所能达到的成就。达到这些数字需要在 vLLM 中进行一系列广泛的优化,这些优化是与 NVIDIA 的工程师深度合作开发的。接下来,我们将概述其中最重要的优化。
vLLM Blackwell 优化
在 Blackwell 上实现上述性能涉及软件栈各个层面的工作。一些优化提高了 GPU 上原始内核的执行速度,而另一些则减少了 CPU 开销或更好地利用了硬件特性。我们在下面列出了 vLLM 迄今为支持 Blackwell 而引入的关键增强功能:
性能改进
- 通过 FlashInfer 加速内核: 我们集成了 NVIDIA 的 FlashInfer 库,以引入许多高性能内核,包括用于 GQA 和 MLA 的 FP8 注意力、快速的 FP8 和 FP4 GEMM、MoE 内核以及融合操作。例如,我们能够将 AllReduce、RMSNorm 和量化合并到一次内核启动中,从而显著改善延迟。这些内核利用了 NVIDIA 软件栈中包括 CUTLASS、CuTeDSL、cuBLAS、cuDNN 和 TRTLLM 在内的广泛技术。
- 更智能的图融合: 扩展了 vLLM 的 torch.compile 图融合功能,现已包括像 Attention + Output Quant 和 AllReduce + RMSNorm + Quant 这样的算子模式,从而在无需手动修改模型的情况下实现了融合内核的性能,最重要的是,这在不同模型架构之间具有普适性。
- 通过异步调度减少主机开销:
--async-scheduling现在可以实现模型执行与主机开销的完全重叠,消除了先前由同步引起的 GPU 空闲时间。这使得工作负载完全流水线化,因此当一个批次的推理在 GPU 上运行时,下一个批次的数据正在并行准备中。
易用性改进
- 自动量化和后端选择: vLLM 会自动检测模型是否使用量化来选择正确的后端,并为您的 GPU 选择最优的注意力后端。例如,在 Blackwell 上,当可用时,vLLM 会选择基于 FlashInfer 的注意力(集成了 NVIDIA 的 TensorRT-LLM 内核),或根据需要回退到 FlashAttention——无需手动设置标志或调整环境。
- FlashInfer GEMM 和 MoE 的自动调优: 由于理想的内核实现很大程度上取决于批量大小和序列长度,我们在 vLLM 的 GPU 运行器中增加了一个自动调优机制。在启动期间,FlashInfer 将通过基准测试和选择内核来进行自动策略选择,确保即使在推理过程中 ISL/OSL 发生变化也能达到峰值性能。
- 用于轻松优化部署的快速入门指南: 除了代码更改,我们还与社区合作,为常见场景编写了快速入门配置指南。针对给定硬件上的每个模型,提供了清晰的说明,指导用户使用推荐设置启动服务器、调整参数、验证准确性并进行性能基准测试——简化了设置过程,并加快了获得结果的时间。
正在进行的工作
以上每一项优化本身都是一个重大的项目,需要紧密的技术合作——而且我们甚至还没有涵盖所有内容!我们与 NVIDIA 的合作仍在继续,未来还有大量改进正在进行中。
展望未来,我们正致力于通过推测解码和数据+专家并行(DEP)配置,为 DeepSeek、Qwen、gpt-oss 等模型在集群规模的推理上实现显著的吞吐量提升。借助 NVIDIA 的 gpt-oss-120b-Eagle3-v2(它集成了 Eagle 推测解码),我们预计吞吐量将提高约 2-3 倍。利用 DEP,它利用了 Blackwell 中 1800 GB/s 低延迟的 NVLINK GPU 间互连技术,我们期望能够解锁比 InferenceMax 基准测试中展示的更高的性能和并发度,为更快、更高效的推理铺平道路。
在 vLLM 和 NVIDIA 之间持续的优化与合作驱动下,Blackwell 的性能每天都在提升。我们正在不断发现新的机会,以推动 Blackwell 平台在效率和规模方面的极限。
致谢
我们要感谢 vLLM 社区中许多才华横溢的人,他们作为这项工作的一部分共同努力:
- Red Hat: Michael Goin, Alexander Matveev, Lucas Wilkinson, Luka Govedič, Wentao Ye, Ilia Markov, Matt Bonanni, Varun Sundar Rabindranath, Bill Nell, Tyler Michael Smith, Robert Shaw
- NVIDIA: Po-Han Huang, Pavani Majety, Shu Wang, Elvis Chen, Zihao Ye, Duncan Moss, Kaixi Hou, Siyuan Fu, Benjamin Chislett, Xin Li, Vadim Gimpelson, Minseok Lee, Amir Samani, Elfie Guo, Lee Nau, Kushan Ahmadian, Grace Ho, Pen Chun Li
- vLLM: Chen Zhang, Yongye Zhu, Bowen Wang, Kaichao You, Simon Mo, Woosuk Kwon, Zhuohan Li
- Meta: Yang Chen, Xiaozhu Meng, Boyuan Feng, Lu Fang
您可以在 http://inferencemax.ai 找到所有 InferenceMax 的结果。运行它的代码已在 https://github.com/InferenceMAX/InferenceMAX 开源。他们对结果的解释可以在 https://newsletter.semianalysis.com/p/inferencemax-open-source-inference 找到。
我们衷心感谢 SemiAnalysis 团队,他们旨在为社区提供公平的测量和比较,从而将硬件和开源软件的协同设计推向了新的高度。感谢 Kimbo Chen、Dylan Patel 及其他成员。
我们很高兴能在未来几周和几个月内继续完善和扩展我们的优化,以解锁更强大的功能!