vLLM 中的 DeepSeek-V3.2-Exp:细粒度稀疏注意力实战
引言
我们激动地宣布,vLLM 已在第一时间支持 DeepSeek-V3.2-Exp,该模型采用了为长上下文任务设计的 DeepSeek 稀疏注意力(DSA)(论文)。在这篇文章中,我们将展示如何在 vLLM 中使用该模型,并深入探讨在 vLLM 中支持 DSA 时遇到的挑战。
特别是,DSA 的闪电索引器(lightning indexer)及其稀疏注意力机制给连续批处理(continuous batching)和分页注意力(paged attention)带来了挑战。例如,我们需要为索引器模块分别处理预填充(prefill)和解码(decode)阶段,并仔细管理不同的缓存布局。
在性能方面,vLLM 集成了 DeepGEMM 中的闪电索引器 CUDA 核函数,以及 FlashMLA 中的新型稀疏注意力核函数。我们对 Blackwell 架构的支持也感到非常兴奋。通过与 NVIDIA 的合作,您现在可以直接在 B200 和 GB200 上运行此模型!

图 1: DeepSeek 稀疏注意力(DSA)机制图解。
使用指南
要开始使用 DeepSeek 3.2,请遵循使用秘籍中的安装说明。我们仍在通过这个 PR 改进初步支持。有关已知问题,请参阅跟踪问题。
安装后,在 16×H100、8×H200 或 8×B200 上,您可以使用张量并行(tensor parallelism)来运行模型(专家并行(expert parallelism)有一个我们正在修复的小 bug)
vllm serve deepseek-ai/DeepSeek-V3.2-Exp --tensor-parallel-size 8
为了大规模部署,我们期待在本周晚些时候分享使用 llm-d 实现的一键式 Kubernetes 部署方案。该方法使用 NIXL 启动 vLLM 并实现处理(P)和数据(D)解耦,然后为每个 P 和 D 实例高效地将请求路由到不同的数据并行等级(data parallel ranks)。相关文档即将发布。
启动引擎后,我们建议您使用*长输入或期望长输出的提示*进行测试。我们建议将其与 V3.1-Terminus 进行比较,因为它是基于相同的数据混合进行持续预训练的。
我们仍在验证 vLLM 实现与官方准确度结果的一致性。在一个早期版本的模型权重上,我们已经匹配了预期的 GSM8K 和 GPQA-Diamond 分数,并表明其性能与 V3.1-Terminus 相当。
在 vLLM 中实现 Top-K 稀疏注意力
新的缓存条目和量化方案
闪电索引器模块有专门用于索引的 K 值缓存。这意味着对于每个 token,现在还有一个供索引器使用的 K 缓存。vLLM 分配了单独的缓冲区来保存索引器 K 缓存,与 MLA K 缓存分开。
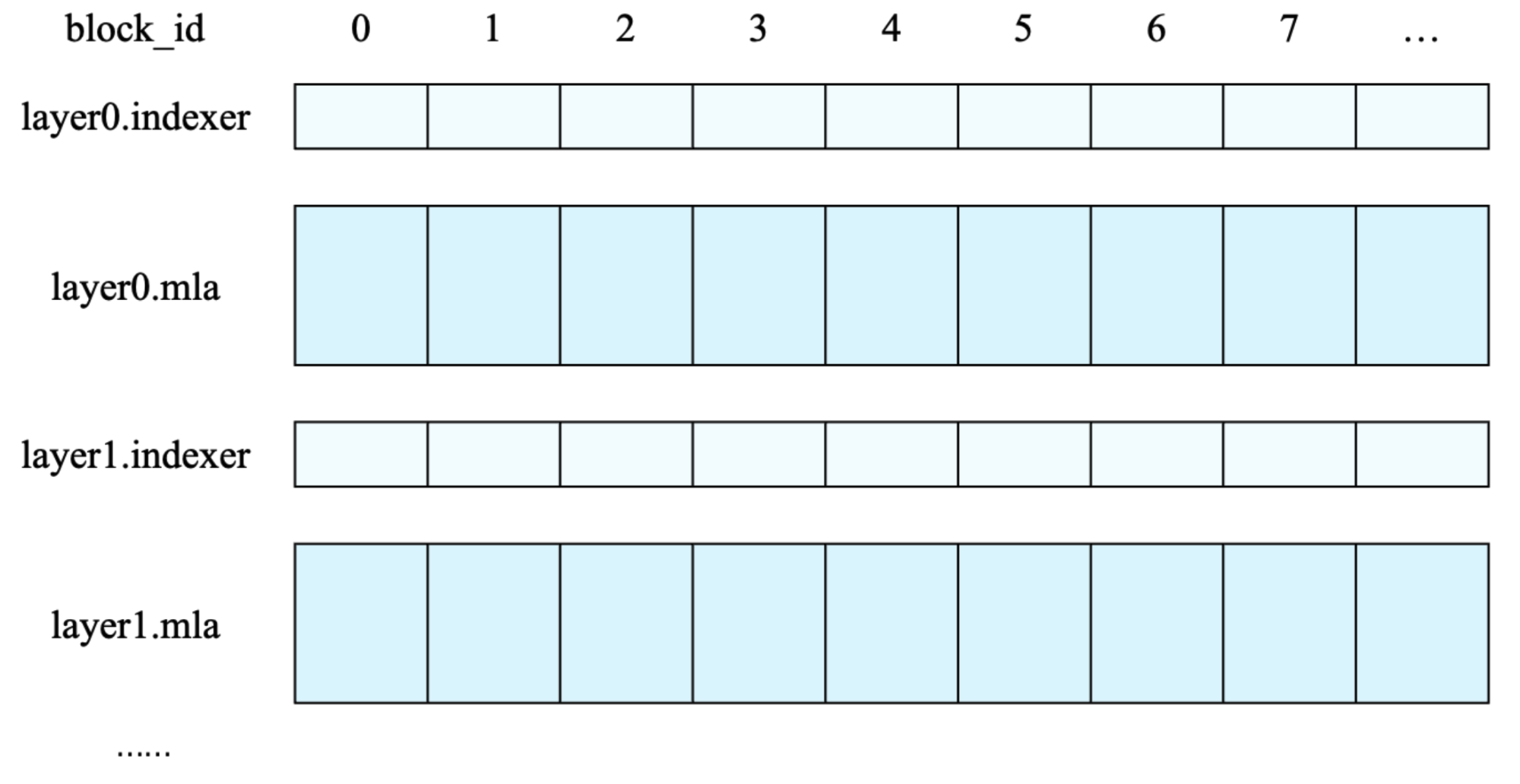
另一个有趣的方面是该模型支持的 FP8 KV 缓存处理。对于 MLA,每个 token 的 KV 缓存为 656 字节,结构如下:
- 前 512 字节: "量化 NoPE" 部分,包含 512 个
float8_e4m3值。 - 接下来的 16 字节: 缩放因子,包含 4 个
float32值。第一个float32是前 128 个float8_e4m3值的缩放因子,第二个是接下来 128 个的缩放因子,以此类推。 - 最后 128 字节: "RoPE" 部分,包含 64 个
bfloat16值。为保证准确性,这部分未进行量化。
然而,对于索引器键缓存,它是按块(block)存储的。这是我们仅支持此模型使用 64 块大小(block size)的原因之一;另一个原因是 FlashMLA 也为此进行了优化。前 block_size * head_dim 个条目包含值,其余包含缩放因子。
x_fp8[ :, : block_size * head_dim] = x_scaled.view(num_blocks, block_size * head_dim).view(dtype=torch.uint8)
x_fp8[ :, block_size * head_dim :] = scales.view(num_blocks, block_size).view(dtype=torch.uint8)
在索引器中,单个 token 的缓存不是连续存储的。
新的带掩码计算
对于每个新的查询 token,它现在会通过索引器来计算要关注的 top 2048 个 token。一个 token 的查询是一个形状为 (h, d) 的张量,其中 h 是查询头的数量,d 是头维度。大小为 n 的上下文是一个形状为 (n, d) 的二维张量。计算出的 logits(查询与上下文之间的相关性得分)是一个形状为 (n, h) 的张量。将 logits 与形状为 (h,) 的头权重相乘,我们得到一个形状为 (n,) 的张量。我们需要生成一个形状为 (2048,) 的整数张量,其中包含 top-2048 token 的索引,如果 token 数少于 2048,则用 -1 填充其余部分。
虽然单个查询 token 如何选择要关注的索引是显而易见的,但批处理的情况更为复杂。让我们来分解一下。
新的 DeepGemm 函数调用如下:
logits = deep_gemm.fp8_mqa_logits(q_fp8, kv_fp8, weights, ks, ke)
对于来自同一请求的多个查询 token(长度为 q),即预填充(prefill)情况,它们存储在一个形状为 (q, h, d) 的张量中。上下文仍然有 n 个 token,因此上下文仍然是一个形状为 (n, d) 的二维张量。logits 是一个形状为 (q, n, h) 的张量。用头权重对 logits 进行加权,我们得到一个形状为 (q, n) 的张量。我们需要生成一个形状为 (q, 2048) 的整数张量,包含 top-2048 token 的索引。由于因果关系,每个查询 token 只关注它之前的 token。我们需要为每个查询 token 标记上下文的开始和结束位置。我们使用 ks 标记上下文开始位置,用 ke 标记上下文结束位置。ks 和 ke 都是形状为 (q,) 的整数张量。在这种情况下,ks 将全为零,而 ke 将是 list(range(n - q, n, 1))。
最后,让我们考虑如何批处理多个请求。我们有 b 个请求,每个请求有 q1, q2, ..., qb 个查询 token,和 n1, n2, ..., nb 个上下文 token。查询 token 将被批处理成一个形状为 (q1 + q2 + ... + qb, h, d) 的张量。上下文将被批处理成一个形状为 (n1 + n2 + ... + nb, d) 的张量。logits 将被批处理成一个形状为 (q1 + q2 + ... + qb, n1 + n2 + ... + nb, h) 的张量。我们需要生成一个形状为 (q1 + q2 + ... + qb, 2048) 的整数张量,包含 top-2048 token 的索引。
我们需要为每个查询 token 标记上下文的开始和结束位置。我们使用 ks 标记上下文开始位置,用 ke 标记上下文结束位置。ks 和 ke 都是形状为 (q1 + q2 + ... + qb,) 的整数张量。
在这种情况下,ks 将是 [0] * q1 + [q1] * q2 + ... + [q1 + q2 + ... + qb] * qb。这里的 * 表示重复列表。ke 将是 list(range(n1 - q1, n1, 1)) + list(range(n2 - q2, n2, 1)) + ... + list(range(nb - qb, nb, 1)) 再加上 ks 的偏移量。
计算完 logits 后,我们需要执行 topk 操作。然而,一个明显的挑战是,在高批处理量和长上下文的情况下,logits 张量在运行行式 topk 之前会被实体化。
融合传递、更多核函数与 Blackwell 支持
在开始优化性能时,我们从一些容易实现的目标着手:
- Top-K 可以用一个融合的核函数来表达,以获得更好的性能。DeepSeek 团队的 TileLang 核函数是一个很好的参考!
- 我们在 MLA 隐向量和索引器键向量写入 vLLM 的页表时对其进行了量化。这 оказалось 并非易事,因为我们之前解释过,这种量化方案是全新的且与众不同。
我们也很高兴地宣布该模型对 Blackwell 提供了开箱即用的支持。我们致力于使 Blackwell 平台在未来的模型发布中成为一等公民,因为其高效率有助于发挥最佳性能!
正在进行的工作
我们对 vLLM 中 DSA 及相关稀疏注意力的优化才刚刚开始。在接下来的几周内:
- 我们计划将支持的架构扩展到 Hopper 和 Blackwell 之外。
- 我们将把支持扩展到其他硬件,如 AMD 和 TPU。借助 vLLM 的可扩展系统,开发者可以直接为模型添加支持。例如,vllm-ascend 和 vllm-mlu 已经支持 DeepSeek V3.2!
- 我们将持续测试大规模、宽专家并行(EP)的服务和解耦。
- 您很快就能用这个模型运行端到端的强化学习(RL)循环。
- 我们将探索 DeepSeek 提出的“用于短序列预填充的掩码 MHA 模式”。
- 在此版本中,我们移除了哈达玛变换,因为我们观察到它对准确性没有影响。我们将进一步研究!
致谢
vLLM 社区中参与支持该模型的团队如下:
- vLLM:陈章(Chen Zhang)、朱永晔(Yongye Zhu)、游凯超(Kaichao You)、Simon Mo、李沐翰(Zhuohan Li)
- 红帽(Red Hat):Lucas Wilkinson、Matt Bonanni、叶文涛(Wentao Ye)、Nicolo Lucchesi、Michael Goin、Robert Shaw、Tyler Michael Smith
- Meta:房露西(Lucia Fang)、孟小主(Xiaozhu Meng)、方路(Lu Fang)
- 英伟达(NVIDIA):王睿(Ray Wang)、Barry Kang、Daniel Campora、Julien Demouth、傅思元(Siyuan Fu)、王泽宇(Zeyu Wang)、李品君(Pen Chun Li)
作为 vLLM 团队,我们衷心感谢 DeepSeek 团队开源该模型、技术和核函数,并感谢 DeepSeek 领导层对 vLLM 的信任与支持!