服务于地理空间、视觉及更多领域:在 vLLM 中启用多模态输出处理
引言
直到最近,生成式人工智能基础设施一直与自回归文本生成模型紧密耦合,这些模型逐个令牌(token-by-token)地生成输出,通常是自然语言形式。vLLM 最初也遵循这一趋势,支持处理文本输入和输出的传统大语言模型(LLM)。随着多模态大语言模型(MLLM)的引入,这一趋势开始转向多模态数据,这些模型能够对文本以及各种模态(如图像、视频、音频等)的数据进行推理。vLLM 再次跟上潮流,支持了 LLaVA 风格的 MLLM,能够对多模态输入数据进行推理并生成文本。
我们现在正目睹一个新的趋势转变,越来越多非自回归模型出现,它们在单次推理过程中生成多模态输出,从而在多种模态上实现更快、更高效的生成。从推理的角度看,这些模型可以被视为池化(pooling)模型,但需要额外的输入和输出处理支持。这类模型的应用领域超越了文本:从图像分类和分割,到音频合成和结构化数据生成。我们在 vLLM 中迈出了新的一步,增加了对这类模型的支持。
我们最初的集成重点是地理空间基础模型,这是一类卷积或视觉 Transformer 模型,它们需要 RGB 通道以外的数据(如多光谱或雷达)和元数据(如地理位置、图像采集日期)。这些模型用于(但不限于)灾害响应或基于卫星图像的土地利用分类等任务。然而,这些改动是通用的,为服务于各种非文本生成模型铺平了道路。
举个具体的例子,我们通过一个通用的后端,将 TerraTorch 框架中的所有地理空间模型(其中一些是与 NASA 和 ESA 合作开发的)集成到 vLLM 中,使它们成为 vLLM 生态系统中的一等公民。
在接下来的部分中,我们将描述对 vLLM 进行的技术性改动,首先从服务地理空间基础模型的需求和挑战说起。
在 vLLM 中集成地理空间基础模型
与文本模型不同,地理空间基础模型(通常实现为视觉 Transformer)不需要令牌解码,也就是说,它们不需要将输出令牌转换为文本。相反,给定一张输入图像,单次推理会生成原始模型输出,然后经过后处理形成输出图像。此外,有时输入图像需要被分割并批处理成若干个子图像,即图块(patches)。这些图块随后被送入模型进行推理,每个图块产生的输出图像再被拼接在一起,形成最终的输出图像。
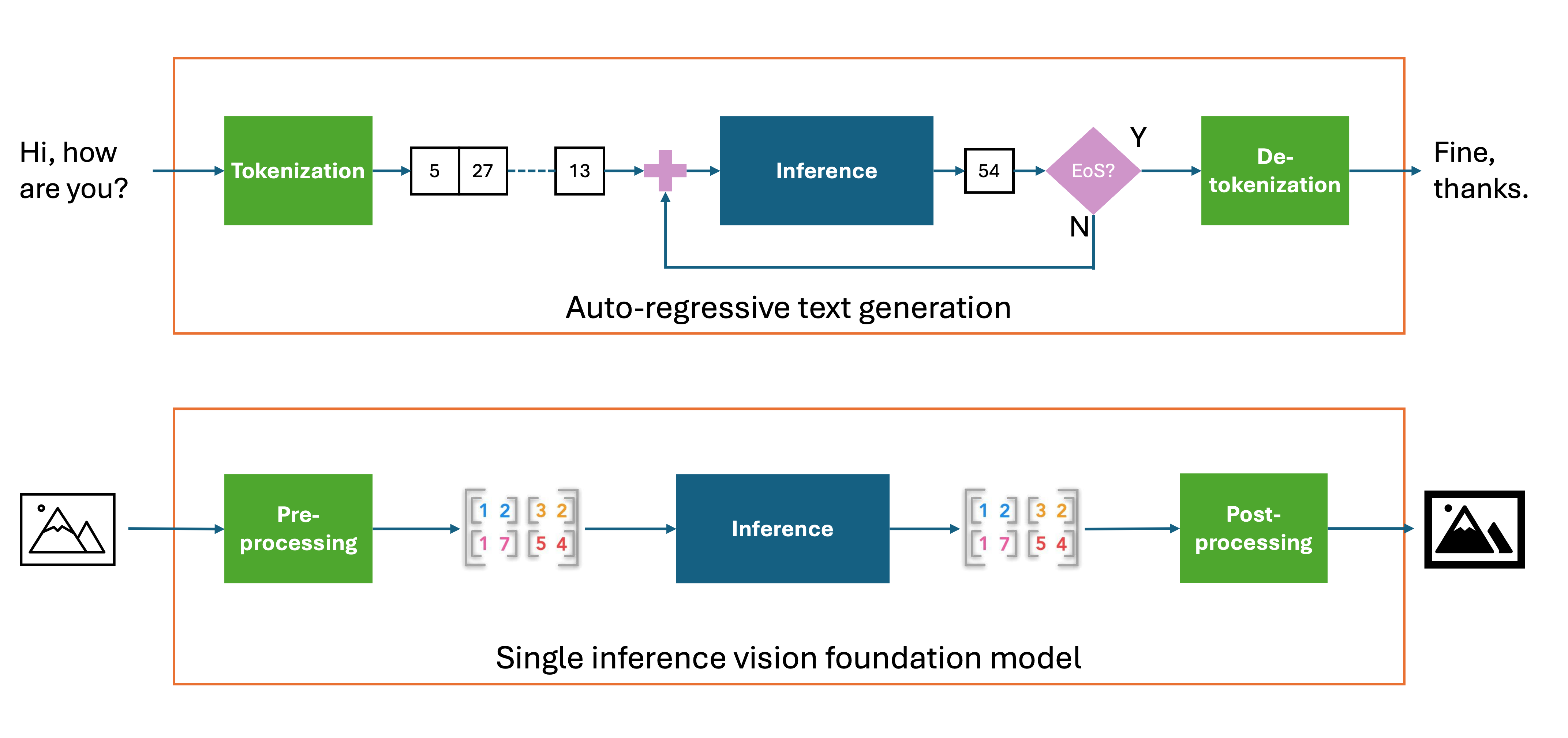
鉴于这些需求,最直接的选择是将地理空间基础模型作为池化模型集成到 vLLM 中。池化是深度学习模型中常用的一种技术,用于减少特征图的空间维度。常见的类型包括最大池化、平均池化和全局池化,每种都使用不同的策略来聚合信息。在 vLLM 中,池化可以应用于诸如嵌入向量计算和分类等任务。此外,vLLM 还支持恒等池化器(identity poolers),它会返回模型的隐藏状态而不应用任何转换——这正是我们所需要的。对于输入,我们利用 vLLM 现有的多模态输入能力,将图像预处理成张量,然后送入模型进行推理。
由于我们希望在 vLLM 中开箱即用地支持多种地理空间基础模型,我们还为 TerraTorch 模型添加了一个模型实现后端,其模式与 HuggingFace Transformers 库的后端相同。
不过,要实现这一点并非易事。启用这些模型类别需要对 vLLM 的多个部分进行修改,例如:
- 增加对无注意力(attention free)模型的支持
- 改进对不需要分词器(tokenizer)的模型的支持
- 允许处理原始输入数据,而非默认的多模态输入嵌入
- 扩展 vLLM 服务 API
认识 IO Processor:为任何模型提供灵活的输入/输出处理
到目前为止一切顺利!不过,这只让我们完成了目标的一半。
通过上述集成,我们确实可以服务地理空间基础模型了——尽管只能以张量到张量(tensor-to-tensor)的格式。用户仍然需要将他们的图像预处理成张量格式,然后才能将张量发送到 vLLM 实例。同样,对原始张量输出的后处理也必须在 vLLM 之外进行。其影响是:没有一个端点可以让用户发送一张图像并取回一张图像。
这个问题之所以存在,是因为在我们进行改动之前,vLLM 中只部分支持对输入数据的预处理和对模型输出的后处理。具体来说,多模态输入数据的预处理只能通过 Transformers 库中可用的处理器(processors)来实现。然而,Transformers 的处理器通常只支持标准数据类型,无法处理更复杂的数据格式,如 GeoTIFF——这是一种带有丰富地理空间元数据的图像文件。此外,在输出处理方面,vLLM 只支持将令牌解码为文本或对模型隐藏状态应用池化器——无法进行其他任何输出处理。
这就是我们引入的新 IO Processor 插件框架发挥作用的地方。IO Processor 框架允许开发者在同一个 vLLM 服务实例中自定义模型的输入和输出如何进行预处理和后处理。无论你的模型返回的是字符串、JSON 对象、图像张量还是自定义数据结构,IO Processor 都能在返回给客户端之前将其转换为所需的格式。
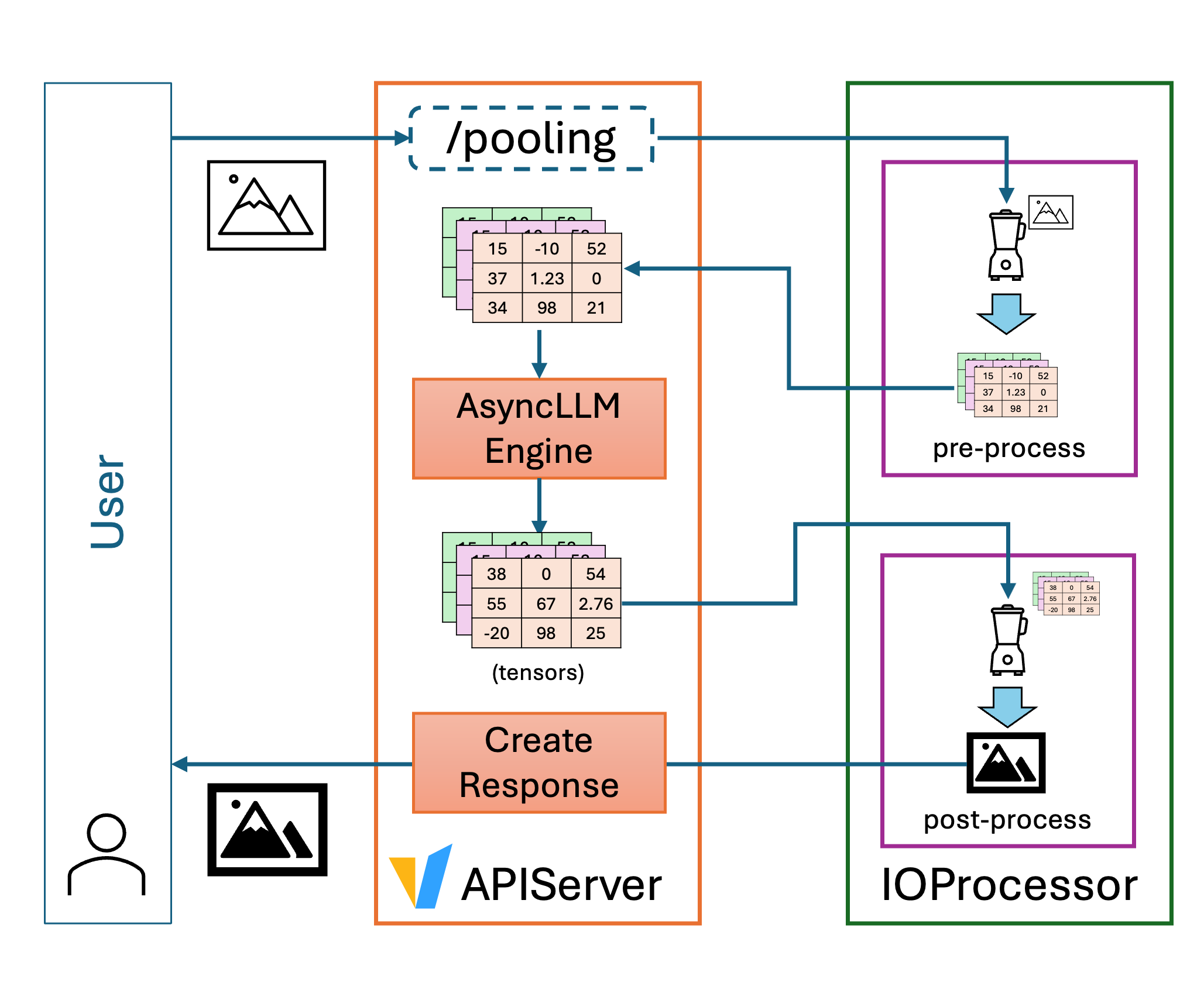
IO Processor 框架为 vLLM 用户开启了新的灵活性。这意味着非文本模型(例如,图像生成器、图像到分割掩码、表格到分类等)可以使用标准的 vLLM 基础设施进行服务。通过 IO Processor,用户可以插入自定义逻辑来转换或丰富输出,例如将模型输出解码为图像,或为下游系统格式化响应。这保持了一个统一的服务栈,降低了运营复杂性并提高了可维护性。
使用 vLLM IO Processor 插件
每个 IO Processor 插件实现一个预定义的 IO Processor 接口,并位于 vLLM 源代码树之外。在安装时,每个插件会在 vllm.io_processor_plugins 组中注册一个或多个入口点(entrypoints)。这使得 vLLM 可以在引擎初始化时自动发现并加载插件。
使用 IO Processor 插件非常简单,只需将其安装在与 vLLM 相同的 Python 环境中,并在启动服务实例时添加 --io-processor-plugin <plugin_name> 参数。目前,每个 vLLM 实例可以加载一个 IO Processor 插件。
服务实例启动后,在服务 /pooling 端点时,预处理和后处理会自动应用于模型的输入和输出。现阶段,IO Processor 仅适用于池化模型,但我们预计未来其他端点也会集成进来。
分步指南:在 vLLM 中服务 Prithvi 模型
可以使用 TerraTorch 后端在 vLLM 中服务的一个模型类别示例是用于洪水检测的 Prithvi 模型。Prithvi 地理空间基础模型的完整插件示例可以在这里找到。
Prithvi IO Processor 插件
为了说明 IO Processor 插件方法的灵活性,下面的伪代码展示了 Prithvi IO Processor 预处理和后处理的主要步骤。我们想要强调的是数据特定转换与模型推理数据之间的解耦。这为几乎任何模型和任何输入/输出数据类型提供了空间,甚至可以根据消费数据的下游任务,将多个插件应用于同一个模型输出。
def pre_process(request_data: dict):
# Downloads geotiff
# In this example the input image has 7 bands
image_url = request_data["url"]
image_obj = download_image(image_url)
# Extract image data:
# - pixel_values([n, 6, 512, 512])
# - 6 input bands R, G, B, +3 multispectral wavelengths
# - n > 1 if the size of the input image is > [512, 512]
# - metadata
# - GPS coordinates
# - date
pixel_values, metadata = process_image(image_obj)
# Process the image data into n vLLM prompts
model_prompts = pixels_to_prompts(pixel_values)
return model_prompts
def post_process(model_outputs: list[PoolingRequestOutput]):
# Uses the previously extracted metadata to guarantee the output
# contains the same georeferences and date.
return image_object(model_outputs, metadata)
安装 Python 依赖
在您的 Python 环境中安装 terratorch (>=1.1rc3) 和 vllm 包。在撰写本文时,复现此示例所需的更改尚未包含在 vLLM 的发布版本中(当前最新版本为 v0.10.1.1),我们建议用户安装最新的代码。
下载并安装用于 Prithvi 洪水检测的 IO Processor 插件。
git clone git@github.com:christian-pinto/prithvi_io_processor_plugin.git
cd prithvi_io_processor_plugin
pip install .
这将安装 prithvi_to_tiff 插件。
启动一个 vLLM 服务实例
启动一个 vLLM 服务实例,加载 prithvi_to_tiff 插件和用于洪水检测的 Prithvi 模型。
vllm serve \
--model=ibm-nasa-geospatial/Prithvi-EO-2.0-300M-TL-Sen1Floods11 \
--model-impl terratorch \
--task embed --trust-remote-code \
--skip-tokenizer-init --enforce-eager \
--io-processor-plugin prithvi_to_tiff
实例运行后,它就可以使用所选插件来服务请求了。下面的日志条目确认您的 vLLM 实例已启动并正在运行,并且正在监听 8000 端口。
INFO: Starting vLLM API server 0 on http://0.0.0.0:8000
...
...
INFO: Started server process [409128]
INFO: Waiting for application startup.
INFO: Application startup complete.
向模型发送请求
下面的 Python 脚本向 vLLM 的 /pooling 端点发送一个带有特定 JSON 载荷的请求,其中 model 和 softmax 参数是预定义的,而 data 字段由用户定义,并取决于所使用的插件。
说明
将 softmax 字段设置为 False 是必需的,以确保插件接收到原始的模型输出。
在这个例子中,我们以 URL 的形式将输入图像发送给 vLLM,并请求响应是一个 base64 编码的 GeoTIFF 图像。该脚本解码图像并将其作为 tiff (GeoTIFF) 文件写入磁盘。
import base64
import os
import requests
def main():
image_url = "https://hugging-face.cn/christian-pinto/Prithvi-EO-2.0-300M-TL-VLLM/resolve/main/valencia_example_2024-10-26.tiff"
server_endpoint = "https://:8000/pooling"
request_payload = {
"data": {
"data": image_url,
"data_format": "url",
"image_format": "tiff",
"out_data_format": "b64_json",
},
"model": "ibm-nasa-geospatial/Prithvi-EO-2.0-300M-TL-Sen1Floods11",
"softmax": False,
}
ret = requests.post(server_endpoint, json=request_payload)
if ret.status_code == 200:
response = ret.json()
decoded_image = base64.b64decode(response["data"]["data"])
out_path = os.path.join(os.getcwd(), "online_prediction.tiff")
with open(out_path, "wb") as f:
f.write(decoded_image)
else:
print(f"Response status_code: {ret.status_code}")
print(f"Response reason:{ret.reason}")
if __name__ == "__main__":
main()
下面是输入和预期输出的一个示例。输入图像(左)是西班牙瓦伦西亚在 2024 年洪水期间的卫星照片。输出图像(右)显示了 Prithvi 模型预测为被洪水淹没的区域(白色部分)。

下一步计划
这仅仅是个开始。我们计划将 IO Processor 插件扩展到更多的 TerraTorch 模型和模态,甚至更多领域,并使安装过程无缝化。从长远来看,我们设想由 IO Processor 驱动的视觉语言系统、结构化推理代理和多模态流水线,所有这些都由同一个 vLLM 栈提供服务。我们也期待看到社区如何使用 IO Processor 来推动 vLLM 的可能性边界。我们还计划继续与 vLLM 社区合作并做出贡献,以支持更多的多模态模型和端到端用例。
我们随时欢迎贡献、反馈和想法!
要开始使用 IO Processor 插件,请查阅文档并浏览示例。有关 IBM TerraTorch 的更多信息,请访问此处。
致谢
我们要感谢 vLLM 社区成员帮助我们改进我们的贡献。特别感谢 Cyrus Leung 在帮助塑造将 vLLM 扩展到文本生成之外的整体概念方面给予的支持。最后,我们要感谢 IBM 的 TerraTorch 团队,特别是 Paolo Fraccaro 和 Joao Lucas de Sousa Almeida,感谢他们在将通用的 TerraTorch 后端集成到 vLLM 中所提供的帮助。