使用 vLLM 加速 RLHF,OpenRLHF 的最佳实践
随着对训练具有推理能力的大型语言模型 (LLM) 的需求增长,从人类反馈中强化学习 (RLHF) 已成为一项基石技术。然而,传统的 RLHF 流水线——特别是那些使用近端策略优化 (PPO) 的流水线——常常受到巨大计算开销的阻碍。对于那些擅长复杂推理任务的模型(例如 OpenAI-o1 和 DeepSeek-R1),这一挑战尤为突出,其中生成长篇思维链 (CoT) 输出可能占总训练时间的 90%。这些模型必须产生详细的、逐步的推理,这可能跨越数千个 token,使得推理阶段比训练阶段本身更加耗时。作为一款开创性的推理框架,vLLM 提供了一个用户友好的界面,用于生成 RLHF 样本和更新模型权重。
OpenRLHF 的设计
为了在 RLHF 框架中平衡性能和可用性,OpenRLHF 被设计成一个高性能且用户友好的解决方案,集成了 Ray, vLLM, 零冗余优化器 (ZeRO-3) 和 自动张量并行 (AutoTP) 等关键技术。
Ray 是 OpenRLHF 分布式架构的骨干。凭借强大的调度和编排功能,Ray 高效管理复杂的数据流和计算,包括将基于规则的奖励模型分布到多个节点上。
vLLM with Ray Executor and AutoTP 在加速推理方面发挥着核心作用。凭借对 Ray Executors 的内置支持以及与 HuggingFace Transformers 的集成,它通过 AutoTP 实现高效的权重更新,从而实现高吞吐量和内存高效的 LLM 生成。
ZeRO-3 with HuggingFace Transformers,来自 DeepSpeed 的一种内存优化方法,使 OpenRLHF 能够训练大型模型,而无需像 Megatron 那样重量级的框架。与 HuggingFace 的无缝集成使得预训练模型的加载和微调变得简单。
Ray, vLLM, ZeRO-3 和 HuggingFace Transformers 共同打造了一个前沿且精简的 RLHF 训练加速解决方案。该架构也影响了其他框架,例如 veRL,它们采用了类似的范例来实现可扩展且高效的 RLHF 训练。OpenRLHF 也是首个基于 Ray, vLLM 和 ZeRO-3 开发的开源 RLHF 框架,已被 Google, 字节跳动, 阿里巴巴, 美团, 伯克利 Starling 团队等使用。
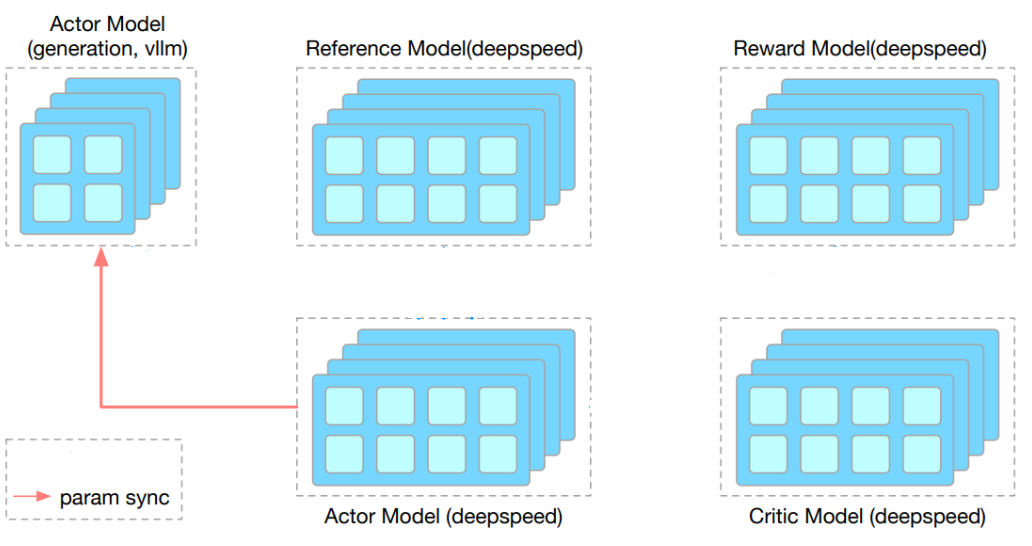
如上图所示,OpenRLHF 使用 Ray 的 Placement Group API 来灵活调度 RLHF 流水线的组件,包括 vLLM 引擎, Actor, Critic, Reference 和 Reward 模型。尽管单独表示,这些组件可以共同安置在共享的 Ray placement groups 中,以最大限度地提高资源效率。例如,所有模块可以在混合引擎配置中在同一 GPU 组内运行,或者特定组件——如 Actor 和 Critic——可以组合在一起。所有模块都由一个中央 Ray Actor 编排,该 Actor 管理整个训练生命周期。Actor 和 vLLM 引擎之间的权重同步通过高性能通信方法处理,例如 NVIDIA Collective Communications Library (NCCL) 或混合引擎设置中的 CUDA Inter-Process Communication (IPC) 内存传输。
使用 vLLM Ray Executor 实现 RLHF 加速
OpenRLHF 和 vLLM 提供了一套清晰高效的 API,以简化 RLHF 流水线中的交互。通过实现一个自定义的 WorkerExtension 类,用户可以处理训练和推理组件之间的权重同步。环境变量 VLLM_RAY_PER_WORKER_GPUS 和 VLLM_RAY_BUNDLE_INDICES 允许对每个 worker 进行细粒度的 GPU 资源分配,从而实现多个组件共享一个 GPU 组的混合引擎配置。
# rlhf_utils.py
class ColocateWorkerExtension:
"""
Extension class for vLLM workers to handle weight synchronization.
This class ensures compatibility with both vLLM V0 and V1.
"""
def report_device_id(self) -> str:
"""Report the unique device ID for this worker"""
from vllm.platforms import current_platform
self.device_uuid = current_platform.get_device_uuid(self.device.index)
return self.device_uuid
def update_weights_from_ipc_handles(self, ipc_handles):
"""Update model weights using IPC handles"""
handles = ipc_handles[self.device_uuid]
device_id = self.device.index
weights = []
for name, handle in handles.items():
func, args = handle
list_args = list(args)
list_args[6] = device_id # Update device ID for current process
tensor = func(*list_args)
weights.append((name, tensor))
self.model_runner.model.load_weights(weights=weights)
torch.cuda.synchronize()
# main.py
class MyLLM(LLM):
"""
Custom LLM class to handle GPU resource allocation and bundle indices.
This ensures proper GPU utilization and placement group management.
"""
def __init__(self, *args, bundle_indices: list, **kwargs):
# Prevent Ray from manipulating CUDA_VISIBLE_DEVICES at the top level
os.environ.pop("CUDA_VISIBLE_DEVICES", None)
# Configure GPU utilization per worker
os.environ["VLLM_RAY_PER_WORKER_GPUS"] = "0.4"
os.environ["VLLM_RAY_BUNDLE_INDICES"] = ",".join(map(str, bundle_indices))
super().__init__(*args, **kwargs)
# Create Ray's placement group for GPU allocation
pg = placement_group([{"GPU": 1, "CPU": 0}] * 4)
ray.get(pg.ready())
# Create inference engines
inference_engines = []
for bundle_indices in [[0, 1], [2, 3]]:
llm = ray.remote(
num_gpus=0,
scheduling_strategy=PlacementGroupSchedulingStrategy(
placement_group=pg
)
)(MyLLM).remote(
model="facebook/opt-125m",
tensor_parallel_size=2,
distributed_executor_backend="ray",
gpu_memory_utilization=0.4,
worker_extension_cls="rlhf_utils.ColocateWorkerExtension",
bundle_indices=bundle_indices
)
inference_engines.append(llm)
完整的 RLHF 示例 详细介绍了如何使用指定的 GPU 数量初始化 Ray, 创建 placement group 来管理资源, 以及定义训练 actors 和推理引擎。训练 actors 管理模型的初始化和权重更新,而推理引擎通过 vLLM 提供模型服务。权重同步使用 CUDA IPC 或 NCCL 进行,确保整个 RLHF 流水线的一致性和效率。
致谢
我们要对 vLLM 的贡献者致以诚挚的谢意,包括 Kaichao You, Cody Yu, Rui Qiao 等许多人,没有他们,OpenRLHF 与 vLLM 的集成将不可能实现。来自 vLLM 团队的 Kaichao You 负责 RLHF 集成工作。
OpenRLHF 项目是首个基于 Ray 和 vLLM 的开源 RLHF 框架。我们要感谢 Jian Hu, Songlin Jiang, Zilin Zhu, Xibin Wu 等许多人对 OpenRLHF 项目中的 Ray, vLLM Wrapper 和 Hybrid Engine 组件做出的重大贡献。由 Jian Hu 负责开发工作。