PTPC-FP8:在 AMD ROCm 上提升 vLLM 性能
TL;DR:AMD ROCm 上的 vLLM 现在具有更佳的 FP8 性能!
- 最新动态? vLLM (v0.7.3+) 在 AMD ROCm 上现已支持 PTPC-FP8 量化。
- 为何如此出色? 您将获得与其他 FP8 方法相似的速度,但准确性却更接近原始 (BF16) 模型质量。这是 ROCm 的最佳 FP8 选项。
- 如何使用
- 安装 ROCm。
- 获取最新的 vLLM (v0.7.3 或更高版本)。
- 运行 Hugging Face 模型时,添加
--quantization ptpc_fp8标志。无需预量化!
什么是 PTPC-FP8? 它是一种用于 FP8 权重和激活量化的方法。它对激活使用逐令牌缩放,对权重使用逐通道缩放,从而为您提供比传统逐张量 FP8 更好的准确性。
简介
大型语言模型 (LLM) 正在彻底改变我们与技术的互动方式,但它们巨大的计算需求可能成为障碍。如果您能在 AMD GPU 上更快速、更高效地运行这些强大的模型,而又不牺牲准确性,那会怎么样?现在您可以做到了!这篇文章介绍了一项突破:vLLM 中的 PTPC-FP8 量化,针对 AMD 的 ROCm 平台进行了优化。准备好以 FP8 的速度获得接近 BF16 的准确性,直接使用 Hugging Face 模型——无需预量化!我们将向您展示它的工作原理、基准测试其性能,并帮助您入门。
LLM 量化的挑战与 PTPC-FP8 解决方案
运行大型语言模型计算成本很高。FP8(8 位浮点)通过减少内存占用和加速矩阵乘法提供了一个引人注目的解决方案,但传统的量化方法在 LLM 方面面临着一个关键挑战。
异常值问题
随着 LLM 扩展到一定规模以上,它们会产生激活异常值。这些异常大的值会带来重大的量化挑战
- 当使用逐张量量化时,大多数值获得的有效精度位很少
- 异常值持续出现在不同令牌的特定通道中
- 虽然权重相对均匀且易于量化,但激活并非如此
PTPC:一种以精度为目标的方案
PTPC-FP8(逐令牌激活,逐通道权重 FP8)通过使用基于三个关键观察结果的定制缩放因子来解决这一挑战
- 异常值始终出现在相同的通道中
- 令牌内的通道幅度变化很大
- 同一通道在不同令牌之间的幅度保持相对稳定
这种洞察力催生了一种双粒度方法
- 逐令牌激活量化:每个输入令牌都获得其自身的缩放因子
- 逐通道权重量化:每个权重列都获得唯一的缩放因子
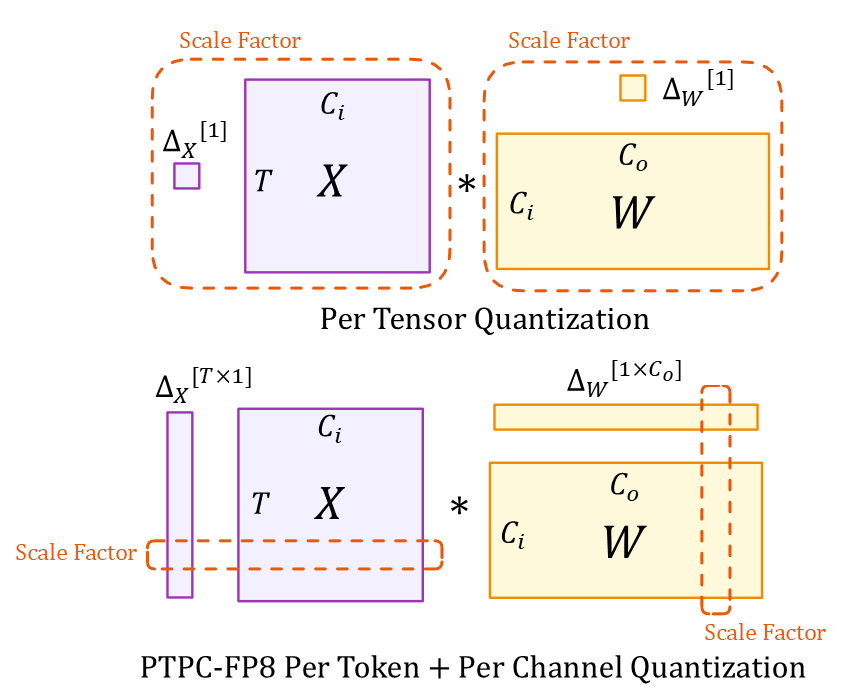
理解图示
该图示展示了两种量化方法
张量维度(两种方法)
- $X$:输入激活张量 ($T \times C_i$)
- $W$:权重张量 ($C_i \times C_o$)
- $T$:令牌序列长度
- $C_i/C_o$:输入/输出通道
- $*$:矩阵乘法
缩放因子
- 顶部(逐张量):整个张量的单个标量 $\Delta_X[1]$ 和 $\Delta_W[1]$
- 底部 (PTPC):向量 $\Delta_X[T \times 1]$,每个令牌一个缩放因子,以及 $\Delta_W[1 \times C_o]$,每个输入通道一个缩放因子
这种细粒度的缩放方法使 PTPC-FP8 能够在保持 8 位计算的速度和内存优势的同时,实现接近 BF16 的准确性。
深入探讨:PTPC-FP8 在 vLLM 中的工作原理(以及融合内核)
如果没有适当的优化,PTPC-FP8 的细粒度缩放可能会降低速度。保持速度的关键是 AMD ROCm 对融合 FP8 行式缩放 GEMM 操作的实现。
挑战:两步法与融合方法
在没有优化的情况下,使用逐令牌和逐通道缩放进行矩阵乘法将需要两个代价高昂的步骤
# Naive 2-step approach:
output = torch._scaled_mm(input, weight) # Step 1: FP8 GEMM
output = output * token_scales * channel_scales # Step 2: Apply scaling factors
这会造成性能瓶颈
- 将大型中间结果写入内存
- 读取它们以进行缩放操作
- 浪费内存带宽和计算周期
解决方案:融合
融合方法将矩阵乘法和缩放合并为单个硬件操作
# Optimized fused operation:
output = torch._scaled_mm(input, weight,
scale_a=token_scales,
scale_b=channel_scales)

为何这很重要
这种融合利用了 AMD GPU 的专用硬件(特别是在具有原生 FP8 支持的 MI300X 上)
- 内存效率:缩放在片上内存中进行,然后在写入结果之前完成
- 计算效率:消除冗余操作
- 性能提升:我们的测试表明,与朴素实现相比,速度提升高达 2.5 倍
融合操作使 PTPC-FP8 能够实际用于真实世界的部署,消除了使用更细粒度缩放因子带来的性能损失,同时保持了准确性优势。
PTPC-FP8 基准测试:MI300X 上的速度和准确性
我们使用 vLLM 在 AMD MI300X GPU 上广泛地对 PTPC-FP8 进行了基准测试(commit 4ea48fb35cf67d61a1c3f18e3981c362e1d8e26f)。以下是我们的发现
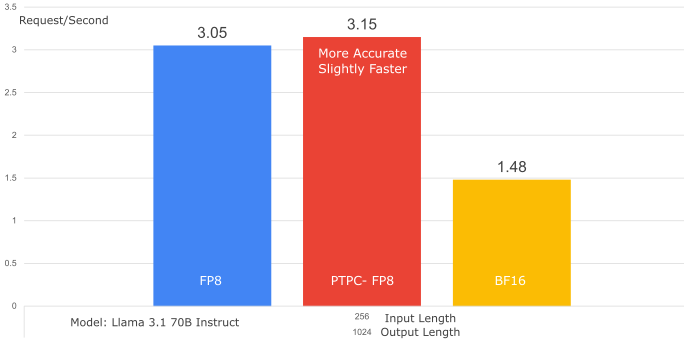
1. 吞吐量比较(PTPC-FP8 vs. 逐张量 FP8)
- 模型: Llama-3.1-70B-Instruct
- 数据集: SharedGPT
- GPU: 1x MI300X
- 结果: PTPC-FP8 实现了与逐张量 FP8 几乎相同的吞吐量(甚至略微更好——提升了 1.01 倍)。这表明融合内核完全克服了 PTPC-FP8 更复杂缩放的潜在开销。


2.1. 准确性:困惑度(越低越好)
- 模型: Llama-3.1-8B-Instruct
- 数据集: Wikitext
- 设置: 2× MI300X GPU,采用张量并行
理解困惑度:预测能力测试
将困惑度视为衡量模型在预测文本时有多“困惑”的指标。就像学生参加测验一样
- 较低的困惑度 = 更好的预测(模型自信地为正确的下一个词分配高概率)
- 较高的困惑度 = 更多的不确定性(模型经常对接下来发生的事情感到惊讶)
困惑度的小幅增加(即使是 0.1)也可能表明模型质量的显着下降,特别是对于经过广泛优化的大型语言模型而言。
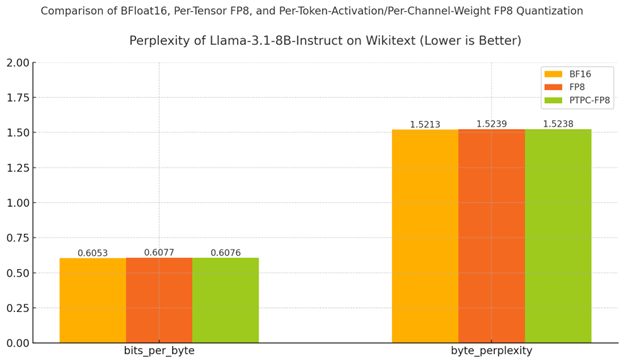
结果:PTPC-FP8 保持了类似 BF16 的质量
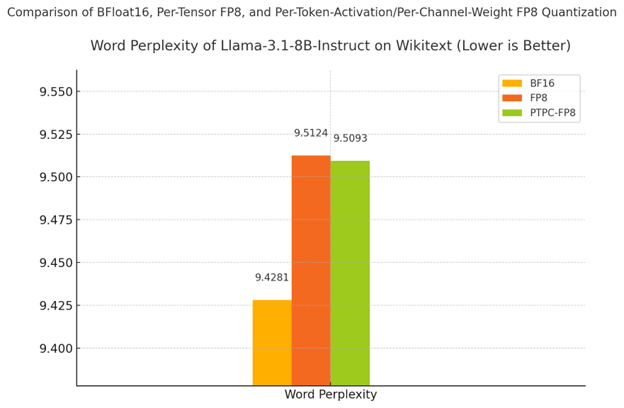
| 精度 | 单词困惑度 | % 降级 |
|---|---|---|
| BF16(基线) | 9.4281 | - |
| PTPC-FP8 | 9.5093 | 0.86% |
| 标准 FP8 | 9.5124 | 0.89% |
如表格和图表所示
- PTPC-FP8 优于标准 FP8 量化(9.5093 vs 9.5124)
- 与 BF16 的差距非常小——仅比全精度基线降低 0.86%
- 字节级指标(bits_per_byte 和 byte_perplexity)显示了相同的结果模式
为何这很重要: 虽然标准 FP8 已经提供了不错的结果,但 PTPC-FP8 更低的困惑度表明它更好地保留了模型进行准确预测的能力。这对于复杂的推理和生成任务尤为重要,在这些任务中,小的质量下降可能会累积成输出质量上的显著差异。
2.2. GSM8K 上的准确性:数学推理测试**
什么是 GSM8K 以及为何它很重要
GSM8K 测试模型解决小学数学应用题的能力——这是 LLM 最具挑战性的任务之一。与简单的文本预测不同,这些问题需要
- 多步骤推理
- 数值准确性
- 逻辑一致性
此基准测试有力地表明了量化是否保留了模型的推理能力。
理解结果
我们使用两种方法测量了准确性
- 灵活提取:如果响应中的任何位置出现正确的数字,则接受答案
- 严格匹配:要求答案与预期格式完全一致

8B 模型结果概览
| 方法 | 严格匹配准确率 | BF16 性能的百分比 |
|---|---|---|
| BF16(基线) | 73.2% | 100% |
| PTPC-FP8 | 70.8% | 96.7% |
| 标准 FP8 | 69.2% | 94.5% |
70B 模型结果
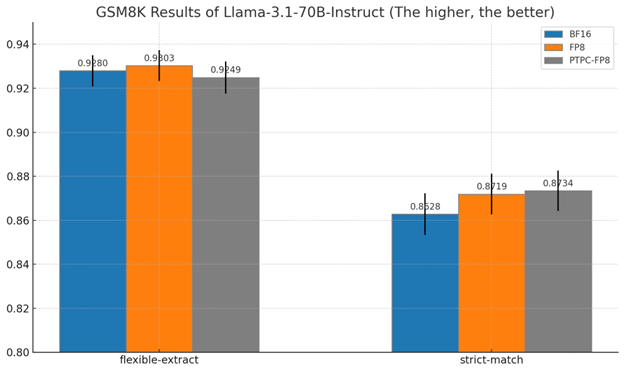
对于更大的 70B 模型
- PTPC-FP8 实现了 87.3% 的严格匹配准确率
- 这实际上略好于 BF16 的 86.3%
- 两者在严格匹配条件下均优于标准 FP8
为何这些结果很重要
-
推理能力的保留:数学推理通常是量化后第一个退化的能力
-
PTPC-FP8 在两种模型尺寸上始终优于标准 FP8
-
接近 BF16 的质量,同时显著降低内存并提高性能
-
扩展优势:量化方法之间的性能差距随着模型尺寸的增加而缩小,这表明 PTPC-FP8 对于大型模型尤其有价值
这些结果表明,PTPC-FP8 量化在提供 8 位精度的速度和效率优势的同时,保留了模型执行复杂推理任务的能力。
开始入门
- 安装 ROCm: 确保您拥有最新版本。
- 立即克隆最新的 vLLM commit!设置并开始探索这项新功能!
$ git clone https://github.com/vllm-project/vllm.git
$ cd vllm
$ DOCKER_BUILDKIT=1 docker build -f Dockerfile.rocm -t vllm-rocm .
$ docker run -it \
--network=host \
--group-add=video \
--ipc=host \
--cap-add=SYS_PTRACE \
--security-opt seccomp=unconfined \
--device /dev/kfd \
--device /dev/dri \
-v <path/to/model>:/app/model \
vllm-rocm \
bash
- 使用
--quantization ptpc_fp8标志运行 vLLM
VLLM_USE_TRITON_FLASH_ATTN=0 vllm serve <your-model> --max-seq-len-to-capture 16384 --enable-chunked-prefill=False --num-scheduler-steps 15 --max-num-seqs 1024 --quantization ptpc_fp8
(将 <your-model> 替换为任何 hugging face 模型;它将自动即时量化权重。)
结论:准确性与速度的最佳平衡点
AMD ROCm 上 vLLM 中的 PTPC-FP8 量化代表着在普及强大 LLM 方面迈出了重要一步。通过使接近 BF16 的准确性以 FP8 的速度实现,我们正在打破限制更广泛应用的计算壁垒。这项进步使更广泛的社区——从个人研究人员到资源受限的组织——能够在可访问的 AMD 硬件上利用大型语言模型的强大功能。我们邀请您探索 PTPC-FP8,分享您的经验,为 vLLM 项目做出贡献,并帮助我们构建一个人人都能获得高效且准确的 AI 的未来。
附录
lm-evaluation-harness 命令
# Unquantized (Bfloat16)
MODEL=meta-llama/Llama-3.1-8B-Instruct
HIP_VISIBLE_DEVICES=0,1 lm_eval \
--model vllm \
--model_args pretrained=$MODEL,add_bos_token=True,tensor_parallel_size=2,kv_cache_dtype=auto,max_model_len=2048,gpu_memory_utilization=0.6 \
--tasks wikitext --batch_size 16
# Per-Tensor FP8 Quantization
MODEL=meta-llama/Llama-3.1-8B-Instruct
HIP_VISIBLE_DEVICES=0,1 lm_eval \
--model vllm \
--model_args pretrained=$MODEL,add_bos_token=True,tensor_parallel_size=2,quantization=fp8,kv_cache_dtype=fp8_e4m3,max_model_len=2048,gpu_memory_utilization=0.6 \
--tasks wikitext --batch_size 16
# Per-Token-Activation Per-Channel-Weight FP8 Quantization
MODEL=meta-llama/Llama-3.1-8B-Instruct
HIP_VISIBLE_DEVICES=0,1 lm_eval \
--model vllm \
--model_args pretrained=$MODEL,add_bos_token=True,tensor_parallel_size=2,quantization=ptpc_fp8,kv_cache_dtype=fp8_e4m3,max_model_len=2048,gpu_memory_utilization=0.6 \
--tasks wikitext --batch_size 16
lm-evaluation-harness 命令(8B 模型 - 针对 70B 进行调整)
# FP8 (Per-Tensor)
MODEL=/app/model/Llama-3.1-8B-Instruct/ # Or Llama-3.1-70B-Instruct
lm_eval \
--model vllm \
--model_args pretrained=$MODEL,add_bos_token=True,quantization=fp8,kv_cache_dtype=fp8_e4m3 \
--tasks gsm8k --num_fewshot 5 --batch_size auto --limit 250
# PTPC FP8
MODEL=/app/model/Llama-3.1-8B-Instruct/ # Or Llama-3.1-70B-Instruct
lm_eval \
--model vllm \
--model_args pretrained=$MODEL,add_bos_token=True,quantization=ptpc_fp8,kv_cache_dtype=fp8_e4m3 \
--tasks gsm8k --num_fewshot 5 --batch_size auto --limit 250
# BF16
MODEL=/app/model/Llama-3.1-8B-Instruct/ # Or Llama-3.1-70B-Instruct
lm_eval \
--model vllm \
--model_args pretrained=$MODEL,add_bos_token=True,kv_cache_dtype=auto \
--tasks gsm8k --num_fewshot 5 --batch_size auto --limit 250