使用 vLLM 进行分布式推理
动机
服务大型模型通常会导致内存瓶颈,例如可怕的 CUDA 内存不足错误。为了解决这个问题,主要有两种方案
- 降低精度 – 利用 FP8 和更低位数的量化方法可以减少内存使用。然而,这种方法可能会影响准确性和可扩展性,并且随着模型规模增长到数千亿参数以上,它本身是不够的。
- 分布式推理 – 将模型计算分布在多个 GPU 或节点上可以实现可扩展性和效率。这就是张量并行和流水线并行等分布式架构发挥作用的地方。
vLLM 架构和大型语言模型推理挑战
与训练相比,LLM 推理提出了独特的挑战
- 与纯粹关注具有已知静态形状的吞吐量的训练不同,推理需要低延迟和动态工作负载处理。
- 推理工作负载必须有效管理 KV 缓存、推测解码和预填充到解码的转换。
- 大型模型通常超出单 GPU 容量,需要先进的并行化策略。
为了解决这些问题,vLLM 提供了
- 张量并行,用于将每个模型层分片到节点内的多个 GPU 上。
- 流水线并行,用于将模型层的连续部分分布到多个节点上。
- 优化的通信内核和控制平面架构,以最大限度地减少 CPU 开销并最大限度地提高 GPU 利用率。
vLLM 中的 GPU 并行技术
张量并行
问题:模型超出单 GPU 容量
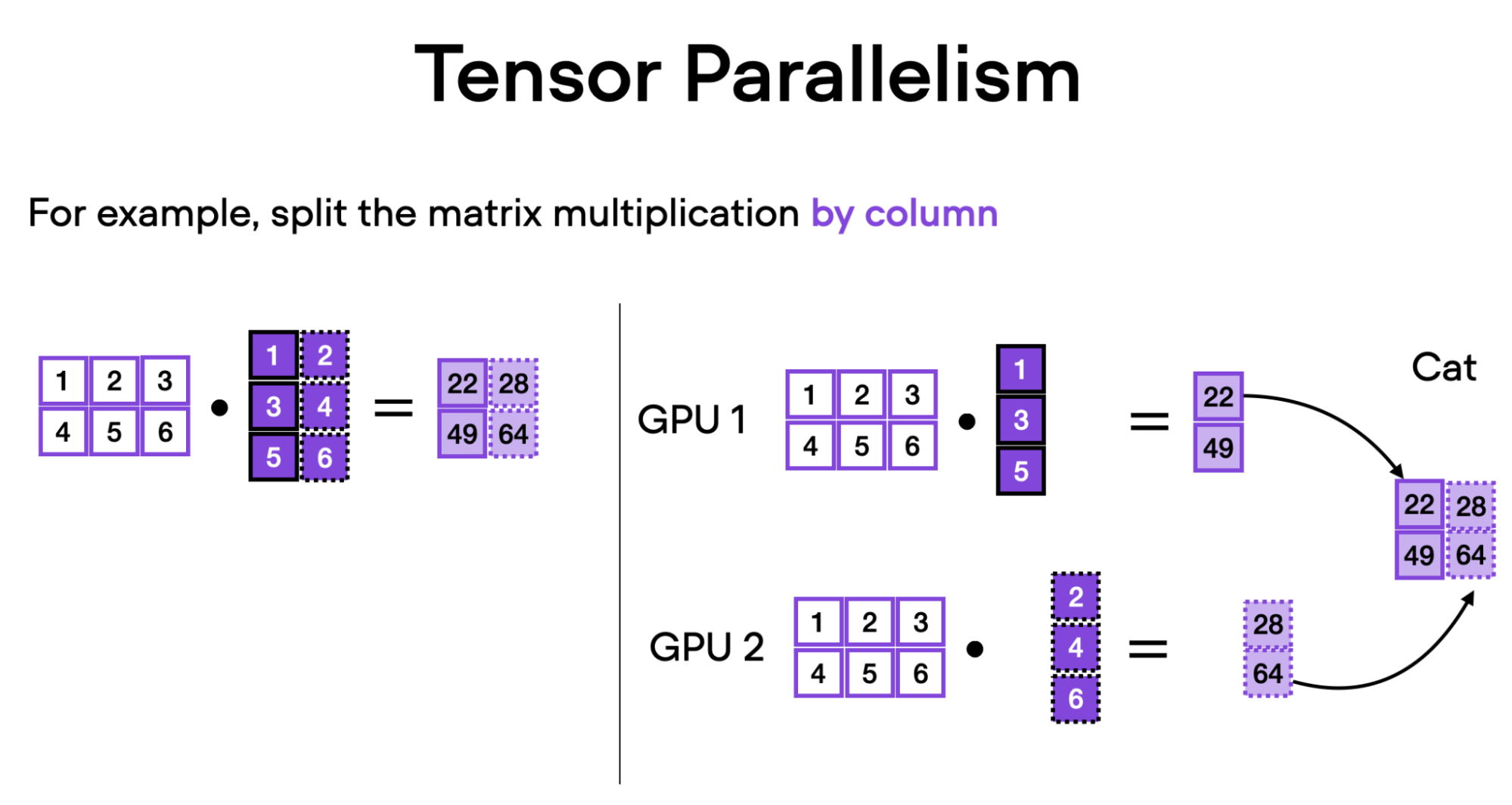
随着模型规模的增长,单个 GPU 无法容纳它们,因此需要多 GPU 策略。张量并行将模型权重分片到多个 GPU 上,从而允许并发计算,以实现更低的延迟和增强的可扩展性。
这种方法最初是在 Megatron-LM (Shoeybi 等人,2019) 中为训练而开发的,已经在 vLLM 中针对推理工作负载进行了调整和优化。
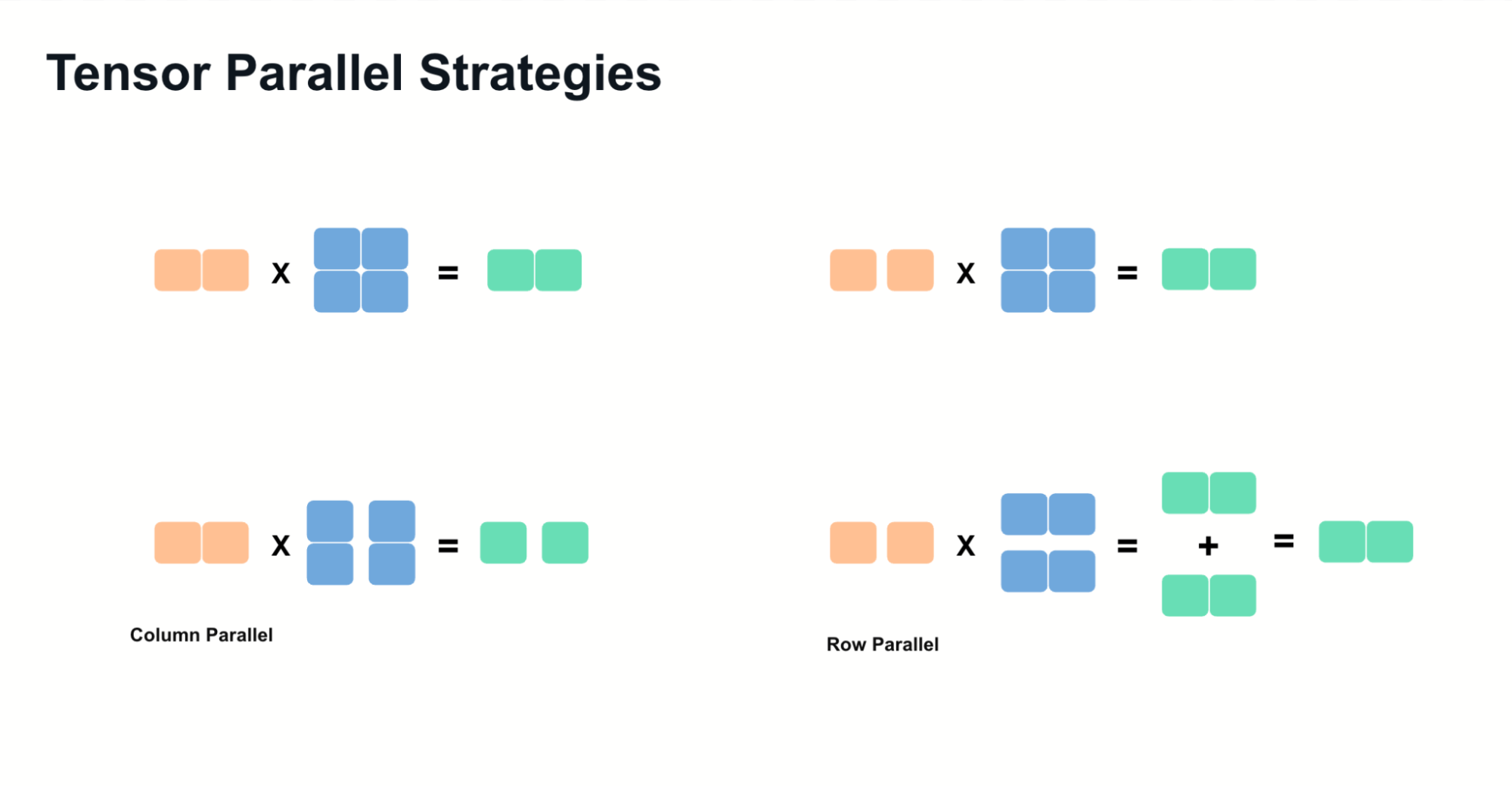
张量并行依赖于两种主要技术
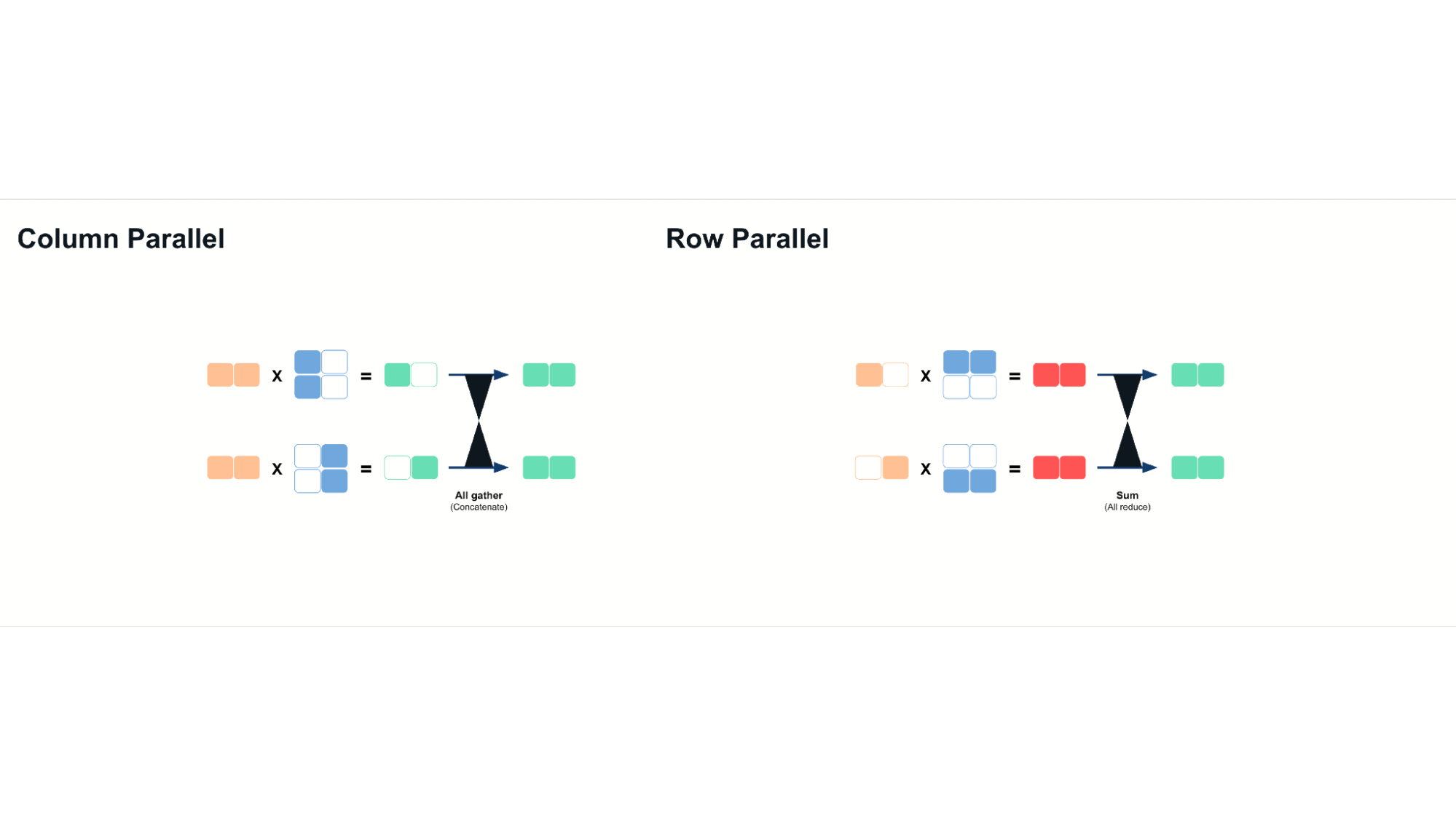
- 列并行:沿列拆分权重矩阵,并在计算后连接结果。
- 行并行:沿行拆分矩阵,并在计算后对部分结果求和。
作为一个具体的例子,让我们分解一下这种并行性如何在 Llama 模型中的 MLP(多层感知器)层中工作
- 列并行适用于上投影操作。
- 逐元素激活函数(例如,SILU)对分片输出进行操作。
- 行并行用于下投影,并使用 all-reduce 操作来聚合最终结果。
张量并行确保推理计算分布在多个 GPU 上,最大限度地利用可用的内存带宽和计算能力。使用张量并行时,我们可以通过有效提高内存带宽来获得延迟改进。这是因为分片模型权重允许多个 GPU 并行访问内存,从而减少单个 GPU 可能遇到的瓶颈。
然而,它需要每个 GPU 之间具有高带宽互连,例如 NVLink 或 InfiniBand,以最大限度地减少来自增加的通信成本的开销。
流水线并行
问题:模型超出多 GPU 容量
对于极大型模型(例如,DeepSeek R1、Llama 3.1 405B),单个节点可能不足以满足需求。流水线并行将模型分片到多个节点上,每个节点处理特定的连续模型层。
工作原理
- 每个 GPU 加载和处理一组不同的层。
- 发送/接收操作:中间激活在 GPU 之间传输,随着计算的进行。
与张量并行相比,这降低了通信开销,因为数据传输在每个流水线阶段发生一次。
流水线并行减少了跨 GPU 的内存限制,但不会像张量并行那样固有地减少推理延迟。为了缓解吞吐量效率低下问题,vLLM 结合了先进的流水线调度,通过优化微批处理执行来确保所有 GPU 保持活动状态。
结合张量并行和流水线并行
作为一般经验法则,可以这样考虑并行性的应用
- 当互连速度较慢时,跨节点使用流水线并行,节点内使用张量并行。
- 如果互连高效(例如,NVLink、InfiniBand),张量并行可以扩展到跨节点。
- 智能地结合这两种技术可以减少不必要的通信开销并最大限度地提高 GPU 利用率。
性能扩展和内存效应
虽然并行化的基本原理表明线性扩展,但在实践中,由于内存效应,性能提升可能是超线性的。使用张量并行或流水线并行,吞吐量提升可能以不明显的方式出现,这是由于 KV 缓存的可用内存呈超线性增长。
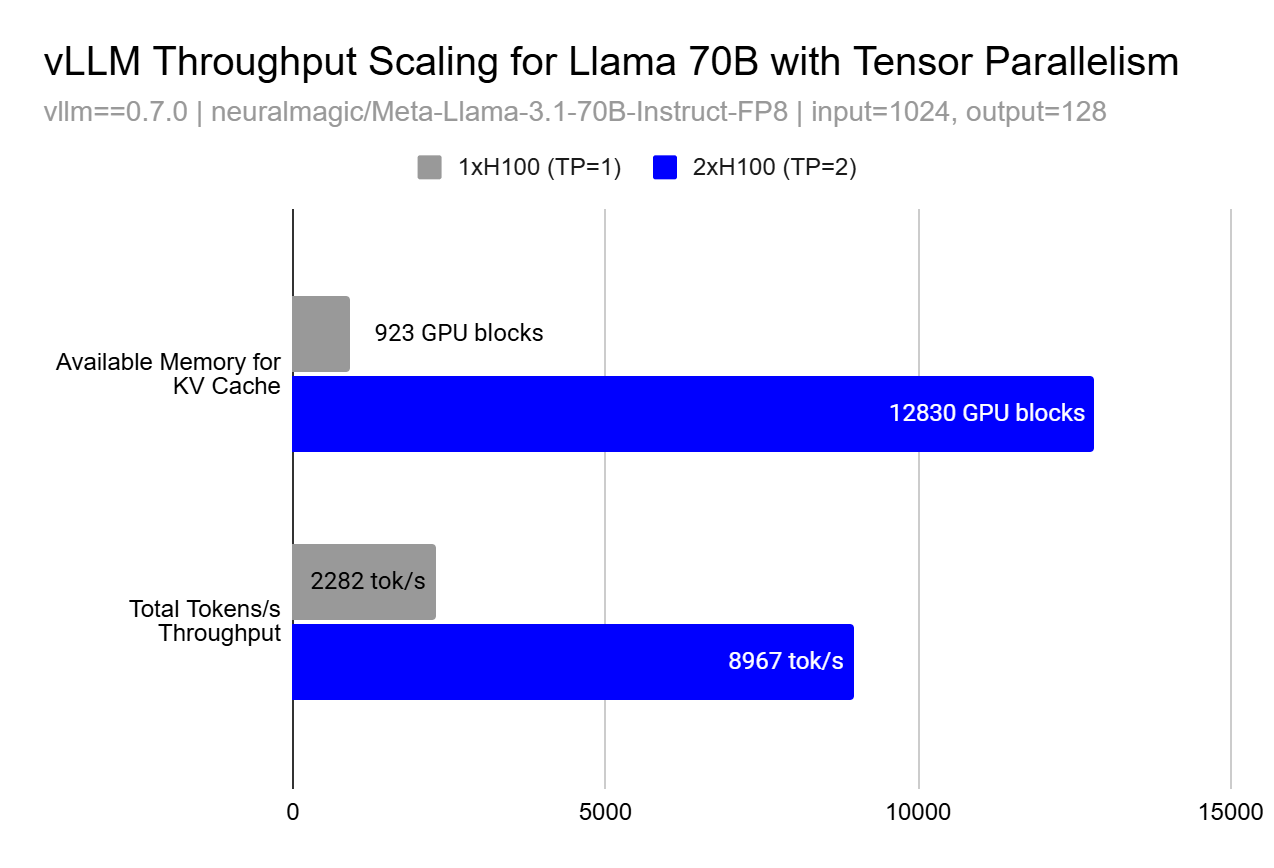
这种超线性扩展效应的发生是因为更大的缓存允许更大的批量大小,以便并行处理更多请求和更好的内存局部性,从而提高了 GPU 利用率,超过了仅仅增加更多计算资源所预期的效果。在上图中,您可以看到在 TP=1 和 TP=2 之间,我们能够将 KV 缓存块的数量增加 13.9 倍,这使我们能够观察到 3.9 倍的 token 吞吐量 - 远高于我们期望的从使用 2 个 GPU 而不是 1 个 GPU 获得的线性 2 倍提升。
进一步阅读
对于有兴趣深入了解影响 vLLM 设计的技术和系统的读者
- Megatron-LM (Shoeybi 等人,2019) 介绍了大型语言模型中模型并行性的基础技术
- Orca (Yu 等人,2022) 提出了一种使用迭代级调度的分布式服务的替代方法
- DeepSpeed 和 FasterTransformer 提供了关于优化 Transformer 推理的补充视角
结论
高效地服务大型模型需要结合张量并行、流水线并行和 性能优化,例如 分块预填充。vLLM 通过利用这些技术实现可扩展的推理,同时确保跨不同硬件加速器的适应性。随着我们不断增强 vLLM,及时了解新的发展,例如 用于混合专家模型 (MoE) 的专家并行 和 扩展的量化支持,对于优化 AI 工作负载至关重要。
参加双周办公时间,了解更多关于 LLM 推理优化和 vLLM 的信息!
致谢
感谢 Sangbin Cho (xAI) 提供了部分图表。