在 Llama Stack 中引入 vLLM 推理提供程序
我们很高兴地宣布,通过 Red Hat AI 工程团队和 Meta 的 Llama Stack 团队之间的合作,vLLM 推理提供程序现已在 Llama Stack 中可用。本文将介绍此集成,并提供一个教程,帮助您开始在本地使用它或将其部署在 Kubernetes 集群中。
什么是 Llama Stack?
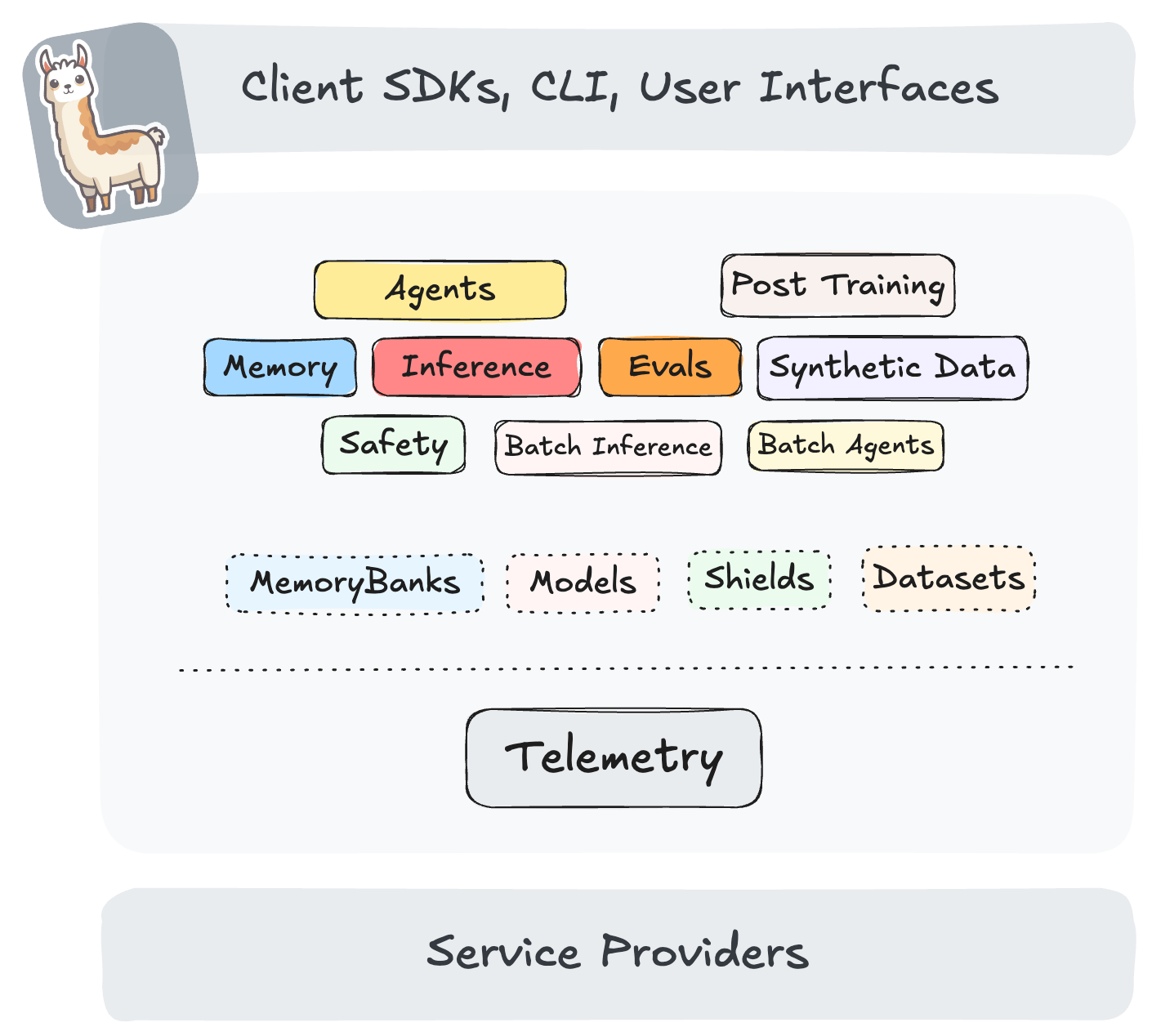
Llama Stack 定义并标准化了将生成式 AI 应用程序推向市场所需的核心构建模块集。这些构建模块以可互操作的 API 形式呈现,并由广泛的服务提供商提供其实现。
Llama Stack 专注于让用户能够轻松地使用各种模型构建生产应用程序,从最新的 Llama 3.3 模型到用于安全性的专用模型 Llama Guard 以及其他模型。目标是提供预打包的实现(也称为“发行版”),这些实现可以在各种部署环境中运行。该 Stack 可以帮助您完成整个应用程序开发生命周期 - 从在本地、移动设备或桌面设备上迭代开始,并无缝过渡到本地部署或公共云部署。在此过渡的每个阶段,都可以使用相同的 API 集和相同的开发者体验。
在此架构中,API 的每个特定实现都称为“提供程序”。用户可以通过配置来更换提供程序。vLLM 是支持推理 API 的高性能 API 的一个突出例子。
vLLM 推理提供程序
Llama Stack 提供了两个 vLLM 推理提供程序
- 远程 vLLM 推理提供程序,通过 vLLM 的 OpenAI 兼容服务器;
- 内联 vLLM 推理提供程序,与 Llama Stack 服务器并行运行。
在本文中,我们将通过远程 vLLM 推理提供程序演示该功能。
教程
前提条件
- Linux 操作系统
- 如果您想通过 CLI 下载模型,则需要 Hugging Face CLI。
- 符合 OCI 标准的容器技术,如 Podman 或 Docker(可以在运行
llama stackCLI 命令时通过CONTAINER_BINARY环境变量指定)。 - 用于 Kubernetes 部署的 Kind。
- 用于管理 Python 环境的 Conda。
通过容器开始
启动 vLLM 服务器
我们首先使用 Hugging Face CLI 下载 “Llama-3.2-1B-Instruct” 模型。请注意,您需要请求访问权限,然后在登录时指定您的 Hugging Face 令牌。
mkdir /tmp/test-vllm-llama-stack
huggingface-cli login --token <YOUR-HF-TOKEN>
huggingface-cli download meta-llama/Llama-3.2-1B-Instruct --local-dir /tmp/test-vllm-llama-stack/.cache/huggingface/hub/models/Llama-3.2-1B-Instruct
接下来,让我们从源代码构建 vLLM CPU 容器镜像。请注意,虽然我们将其用于演示目的,但还有许多其他镜像可用于不同的硬件和架构。
git clone git@github.com:vllm-project/vllm.git /tmp/test-vllm-llama-stack
cd /tmp/test-vllm-llama-stack/vllm
podman build -f Dockerfile.cpu -t vllm-cpu-env --shm-size=4g .
然后我们可以启动 vLLM 容器
podman run -it --network=host \
--group-add=video \
--ipc=host \
--cap-add=SYS_PTRACE \
--security-opt seccomp=unconfined \
--device /dev/kfd \
--device /dev/dri \
-v /tmp/test-vllm-llama-stack/.cache/huggingface/hub/models/Llama-3.2-1B-Instruct:/app/model \
--entrypoint='["python3", "-m", "vllm.entrypoints.openai.api_server", "--model", "/app/model", "--served-model-name", "meta-llama/Llama-3.2-1B-Instruct", "--port", "8000"]' \
vllm-cpu-env
模型服务器启动后,我们可以获取模型列表并测试提示
curl https://:8000/v1/models
curl https://:8000/v1/completions \
-H "Content-Type: application/json" \
-d '{
"model": "meta-llama/Llama-3.2-1B-Instruct",
"prompt": "San Francisco is a",
"max_tokens": 7,
"temperature": 0
}'
启动 Llama Stack 服务器
一旦我们验证 vLLM 服务器已成功启动并能够处理请求,我们就可以构建并启动 Llama Stack 服务器。
首先,我们克隆 Llama Stack 源代码并创建一个包含所有依赖项的 Conda 环境
git clone git@github.com:meta-llama/llama-stack.git /tmp/test-vllm-llama-stack/llama-stack
cd /tmp/test-vllm-llama-stack/llama-stack
conda create -n stack python=3.10
conda activate stack
pip install .
接下来,我们使用 llama stack build 构建容器镜像
cat > /tmp/test-vllm-llama-stack/vllm-llama-stack-build.yaml << "EOF"
name: vllm
distribution_spec:
description: Like local, but use vLLM for running LLM inference
providers:
inference: remote::vllm
safety: inline::llama-guard
agents: inline::meta-reference
vector_io: inline::faiss
datasetio: inline::localfs
scoring: inline::basic
eval: inline::meta-reference
post_training: inline::torchtune
telemetry: inline::meta-reference
image_type: container
EOF
export CONTAINER_BINARY=podman
LLAMA_STACK_DIR=. PYTHONPATH=. python -m llama_stack.cli.llama stack build --config /tmp/test-vllm-llama-stack/vllm-llama-stack-build.yaml --image-name distribution-myenv
容器镜像成功构建后,我们可以编辑生成的 vllm-run.yaml 文件,将其更改为 /tmp/test-vllm-llama-stack/vllm-llama-stack-run.yaml,并在 models 字段中进行以下更改
models:
- metadata: {}
model_id: ${env.INFERENCE_MODEL}
provider_id: vllm
provider_model_id: null
然后我们可以使用我们通过 llama stack run 构建的镜像启动 Llama Stack 服务器
export INFERENCE_ADDR=host.containers.internal
export INFERENCE_PORT=8000
export INFERENCE_MODEL=meta-llama/Llama-3.2-1B-Instruct
export LLAMA_STACK_PORT=5000
LLAMA_STACK_DIR=. PYTHONPATH=. python -m llama_stack.cli.llama stack run \
--env INFERENCE_MODEL=$INFERENCE_MODEL \
--env VLLM_URL=http://$INFERENCE_ADDR:$INFERENCE_PORT/v1 \
--env VLLM_MAX_TOKENS=8192 \
--env VLLM_API_TOKEN=fake \
--env LLAMA_STACK_PORT=$LLAMA_STACK_PORT \
/tmp/test-vllm-llama-stack/vllm-llama-stack-run.yaml
或者,我们可以改为运行以下 podman run 命令
podman run --security-opt label=disable -it --network host -v /tmp/test-vllm-llama-stack/vllm-llama-stack-run.yaml:/app/config.yaml -v /tmp/test-vllm-llama-stack/llama-stack:/app/llama-stack-source \
--env INFERENCE_MODEL=$INFERENCE_MODEL \
--env VLLM_URL=http://$INFERENCE_ADDR:$INFERENCE_PORT/v1 \
--env VLLM_MAX_TOKENS=8192 \
--env VLLM_API_TOKEN=fake \
--env LLAMA_STACK_PORT=$LLAMA_STACK_PORT \
--entrypoint='["python", "-m", "llama_stack.distribution.server.server", "--yaml-config", "/app/config.yaml"]' \
localhost/distribution-myenv:dev
一旦我们成功启动 Llama Stack 服务器,我们就可以开始测试推理请求
通过 Bash
llama-stack-client --endpoint https://:5000 inference chat-completion --message "hello, what model are you?"
输出
ChatCompletionResponse(
completion_message=CompletionMessage(
content="Hello! I'm an AI, a conversational AI model. I'm a type of computer program designed to understand and respond to human language. My creators have
trained me on a vast amount of text data, allowing me to generate human-like responses to a wide range of questions and topics. I'm here to help answer any question you
may have, so feel free to ask me anything!",
role='assistant',
stop_reason='end_of_turn',
tool_calls=[]
),
logprobs=None
)
通过 Python
import os
from llama_stack_client import LlamaStackClient
client = LlamaStackClient(base_url=f"https://:{os.environ['LLAMA_STACK_PORT']}")
# List available models
models = client.models.list()
print(models)
response = client.inference.chat_completion(
model_id=os.environ["INFERENCE_MODEL"],
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Write a haiku about coding"}
]
)
print(response.completion_message.content)
输出
[Model(identifier='meta-llama/Llama-3.2-1B-Instruct', metadata={}, api_model_type='llm', provider_id='vllm', provider_resource_id='meta-llama/Llama-3.2-1B-Instruct', type='model', model_type='llm')]
Here is a haiku about coding:
Columns of code flow
Logic codes the endless night
Tech's silent dawn rise
在 Kubernetes 上部署
除了在本地启动 Llama Stack 和 vLLM 服务器,我们还可以将它们部署在 Kubernetes 集群中。出于演示目的,我们将使用本地 Kind 集群
kind create cluster --image kindest/node:v1.32.0 --name llama-stack-test
将 vLLM 服务器作为 Kubernetes Pod 和 Service 启动(请记住将 <YOUR-HF-TOKEN> 替换为您的实际令牌)
cat <<EOF |kubectl apply -f -
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: vllm-models
spec:
accessModes:
- ReadWriteOnce
volumeMode: Filesystem
resources:
requests:
storage: 50Gi
---
apiVersion: v1
kind: Secret
metadata:
name: hf-token-secret
type: Opaque
data:
token: "<YOUR-HF-TOKEN>"
---
apiVersion: v1
kind: Pod
metadata:
name: vllm-server
labels:
app: vllm
spec:
containers:
- name: llama-stack
image: localhost/vllm-cpu-env:latest
command:
- bash
- -c
- |
MODEL="meta-llama/Llama-3.2-1B-Instruct"
MODEL_PATH=/app/model/$(basename $MODEL)
huggingface-cli login --token $HUGGING_FACE_HUB_TOKEN
huggingface-cli download $MODEL --local-dir $MODEL_PATH --cache-dir $MODEL_PATH
python3 -m vllm.entrypoints.openai.api_server --model $MODEL_PATH --served-model-name $MODEL --port 8000
ports:
- containerPort: 8000
volumeMounts:
- name: llama-storage
mountPath: /app/model
env:
- name: HUGGING_FACE_HUB_TOKEN
valueFrom:
secretKeyRef:
name: hf-token-secret
key: token
volumes:
- name: llama-storage
persistentVolumeClaim:
claimName: vllm-models
---
apiVersion: v1
kind: Service
metadata:
name: vllm-server
spec:
selector:
app: vllm
ports:
- port: 8000
targetPort: 8000
type: NodePort
EOF
我们可以通过日志验证 vLLM 服务器是否已成功启动(下载模型可能需要几分钟)
$ kubectl logs vllm-server
...
INFO: Started server process [1]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:8000 (Press CTRL+C to quit)
然后我们可以修改之前创建的 vllm-llama-stack-run.yaml 文件,将其更改为 /tmp/test-vllm-llama-stack/vllm-llama-stack-run-k8s.yaml,并使用以下推理提供程序
providers:
inference:
- provider_id: vllm
provider_type: remote::vllm
config:
url: http://vllm-server.default.svc.cluster.local:8000/v1
max_tokens: 4096
api_token: fake
一旦我们定义了 Llama Stack 的运行配置,我们就可以使用该配置和服务器源代码构建镜像
cat >/tmp/test-vllm-llama-stack/Containerfile.llama-stack-run-k8s <<EOF
FROM distribution-myenv:dev
RUN apt-get update && apt-get install -y git
RUN git clone https://github.com/meta-llama/llama-stack.git /app/llama-stack-source
ADD ./vllm-llama-stack-run-k8s.yaml /app/config.yaml
EOF
podman build -f /tmp/test-vllm-llama-stack/Containerfile.llama-stack-run-k8s -t llama-stack-run-k8s /tmp/test-vllm-llama-stack
然后我们可以通过部署 Kubernetes Pod 和 Service 来启动 Llama Stack 服务器
cat <<EOF |kubectl apply -f -
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: llama-pvc
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
---
apiVersion: v1
kind: Pod
metadata:
name: llama-stack-pod
labels:
app: llama-stack
spec:
containers:
- name: llama-stack
image: localhost/llama-stack-run-k8s:latest
imagePullPolicy: IfNotPresent
command: ["python", "-m", "llama_stack.distribution.server.server", "--yaml-config", "/app/config.yaml"]
ports:
- containerPort: 5000
volumeMounts:
- name: llama-storage
mountPath: /root/.llama
volumes:
- name: llama-storage
persistentVolumeClaim:
claimName: llama-pvc
---
apiVersion: v1
kind: Service
metadata:
name: llama-stack-service
spec:
selector:
app: llama-stack
ports:
- protocol: TCP
port: 5000
targetPort: 5000
type: ClusterIP
EOF
我们可以检查 Llama Stack 服务器是否已启动
$ kubectl logs vllm-server
...
INFO: Started server process [1]
INFO: Waiting for application startup.
INFO: ASGI 'lifespan' protocol appears unsupported.
INFO: Application startup complete.
INFO: Uvicorn running on http://['::', '0.0.0.0']:5000 (Press CTRL+C to quit)
现在让我们将 Kubernetes 服务转发到本地端口,并通过 Llama Stack 客户端针对它测试一些推理请求
kubectl port-forward service/llama-stack-service 5000:5000
llama-stack-client --endpoint https://:5000 inference chat-completion --message "hello, what model are you?"
您可以在官方文档中了解更多关于 Llama Stack 的不同提供程序和功能的信息。
致谢
我们要感谢 Red Hat AI 工程团队实现了 vLLM 推理提供程序,并为许多错误修复、改进和关键设计讨论做出了贡献。我们还要感谢 Meta 的 Llama Stack 团队和 vLLM 团队及时进行的 PR 审查和错误修复。