vLLM production-stack 在 K8S 中的高性能和简易部署
TL;DR(摘要)
- vLLM 拥有最大的开源社区,但是要将 vLLM 从最佳单节点 LLM 引擎转变为一流的 LLM 服务系统,还需要做些什么呢?
- 今天,我们发布 “vLLM production-stack”,这是一个基于 vLLM 的完整推理堆栈,它引入了两大主要优势
- 性能提升 10 倍(响应延迟降低 3-10 倍,吞吐量提高 2-5 倍),这得益于前缀感知请求路由和 KV 缓存共享。
- 简易的集群部署,内置支持容错、自动扩缩容和可观测性。
- 最棒的是,它是开源的——因此每个人都可以立即开始使用! [https://github.com/vllm-project/production-stack]
背景
在 AI 军备竞赛中,重要的不再仅仅是谁拥有最好的模型,而是谁拥有最好的 LLM 服务系统。
vLLM 以其无与伦比的硬件和模型支持,以及由顶尖贡献者组成的活跃生态系统,在开源社区中掀起了一股热潮。但到目前为止,vLLM 主要专注于单节点部署。
我们如何将其能力扩展到一个全栈推理系统,以便任何组织都能够以高可靠性、高吞吐量和低延迟进行大规模部署?这正是 LMCache 团队和 vLLM 团队构建 vLLM production-stack 的原因。
隆重推出 “vLLM Production-Stack”
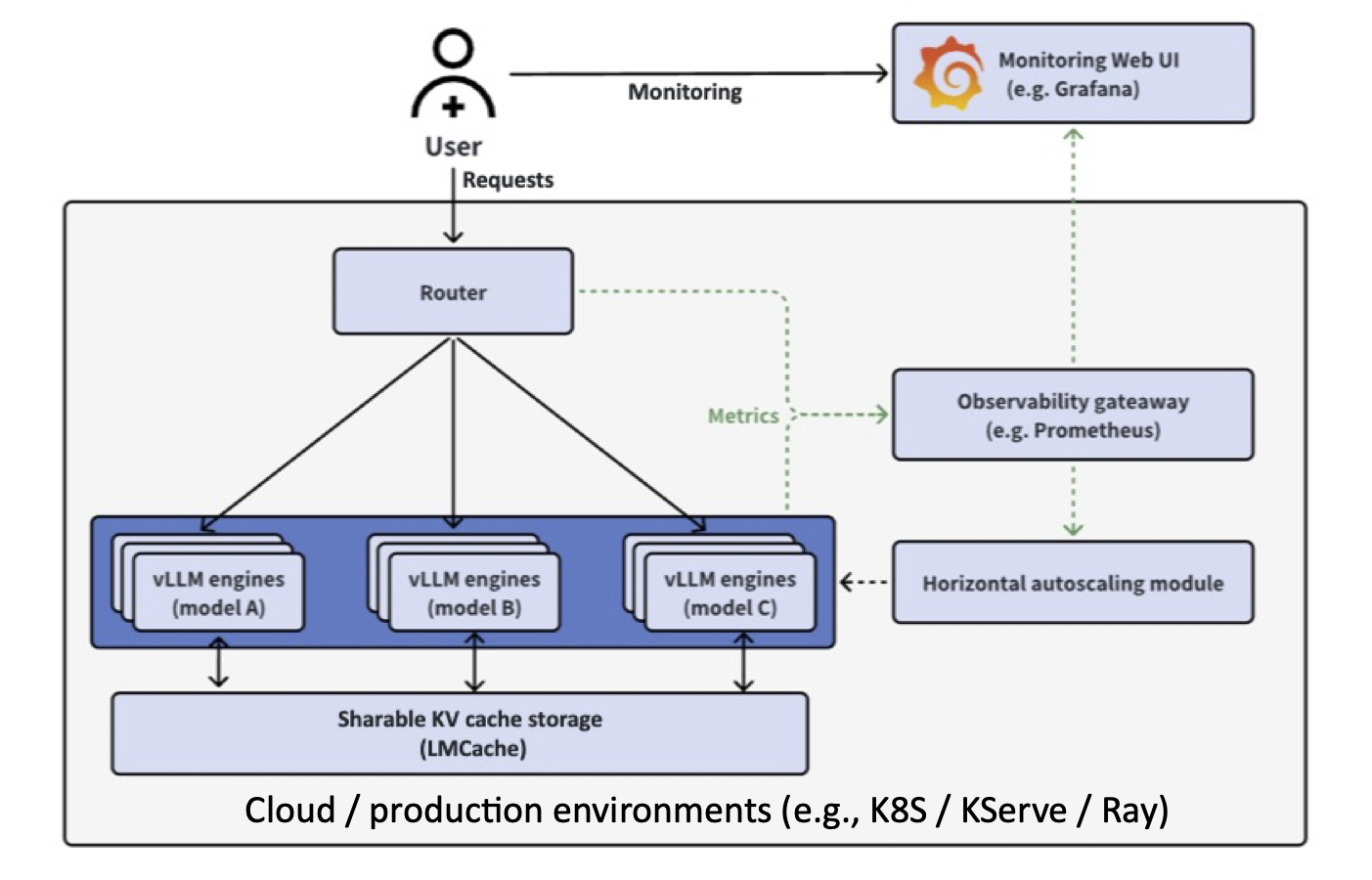
vLLM Production-stack 是一个开源的 参考实现,它是一个构建在 vLLM 之上的 推理堆栈,旨在集群 GPU 节点上无缝运行。它添加了四个关键功能,以补充 vLLM 的原生优势
- KV 缓存共享和存储,以加速上下文重用时的推理速度(由 LMCache 项目驱动)。
- 前缀感知路由,将查询发送到已持有相关上下文 KV 缓存的 vLLM 实例。
- 可观测性,用于监控各个引擎状态和查询级别的指标(首个令牌时间 TTFT、令牌间时间 TBT、吞吐量)。
- 自动扩缩容,以应对工作负载的动态变化。
与替代方案的比较
以下是一个快速快照,将 vLLM production-stack 与其最接近的竞争对手进行了比较

设计
vLLM production-stack 架构构建在 vLLM 强大的单节点引擎之上,以提供集群范围的解决方案。
在高层次上
- 应用程序发送 LLM 推理请求。
- 前缀感知路由检查请求的上下文是否已缓存在某个实例的内存池中。然后,它将请求转发到具有预计算缓存的节点。
- 自动扩缩容和集群管理器监视整体负载,并在需要时启动新的 vLLM 节点。
- 可观测性模块收集诸如 TTFT(首个令牌时间)、TBT(令牌间时间)和吞吐量等指标,让您可以实时了解系统的健康状况。
优势 #1:简易部署
通过运行单个命令,使用 helm chart 将 vLLM production-stack 部署到您的 k8s 集群
sudo helm repo add llmstack-repo https://lmcache.github.io/helm/ &&\
sudo helm install llmstack llmstack-repo/vllm-stack
有关更多详细信息,请参阅 vLLM production-stack repo 中的详细 README。关于设置 k8s 集群和自定义 helm charts 的 教程 也已提供。
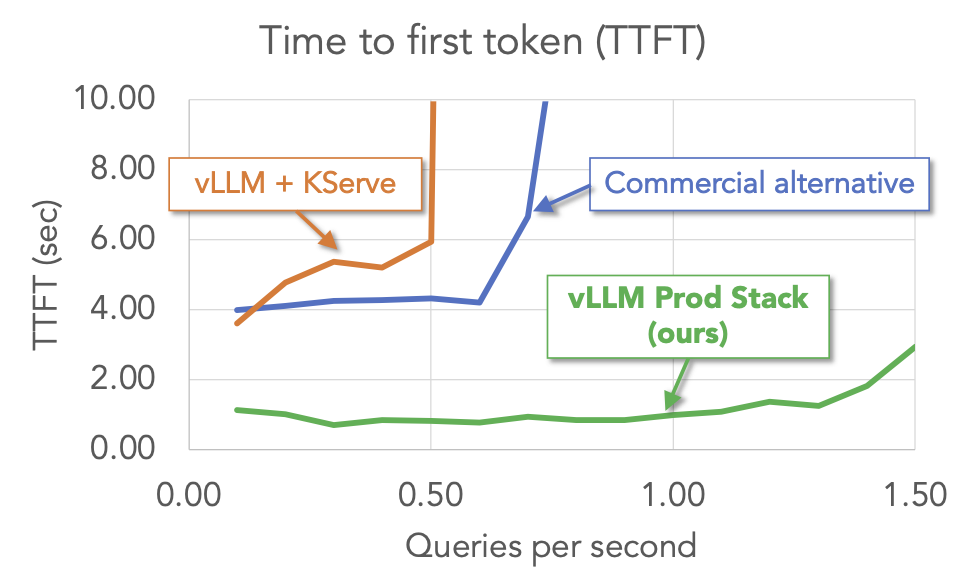
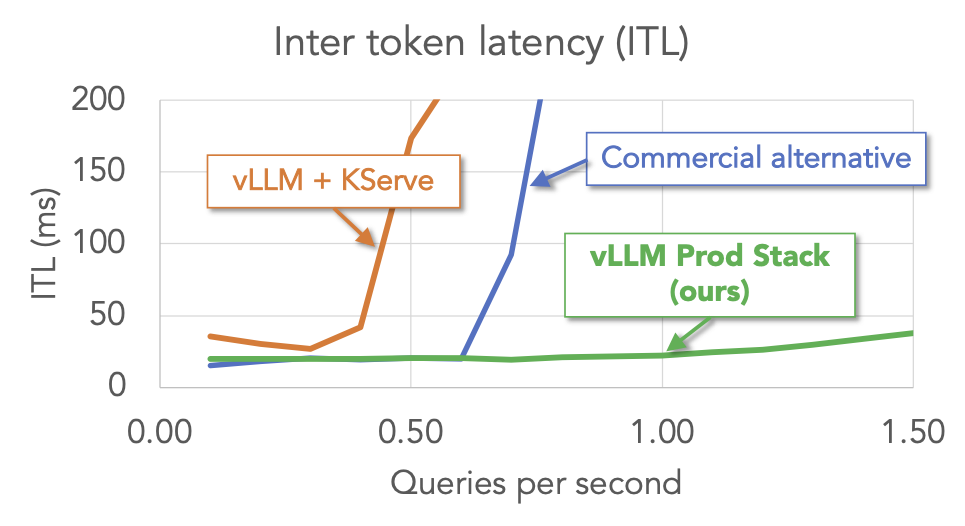
优势 #2:更佳性能
我们对 vLLM production-stack 和其他设置(包括 vLLM + KServe 和商业端点服务)进行了多轮问答工作负载的基准测试。结果表明,在关键指标(首个令牌时间和令牌间延迟)方面,vLLM stack 优于其他设置。
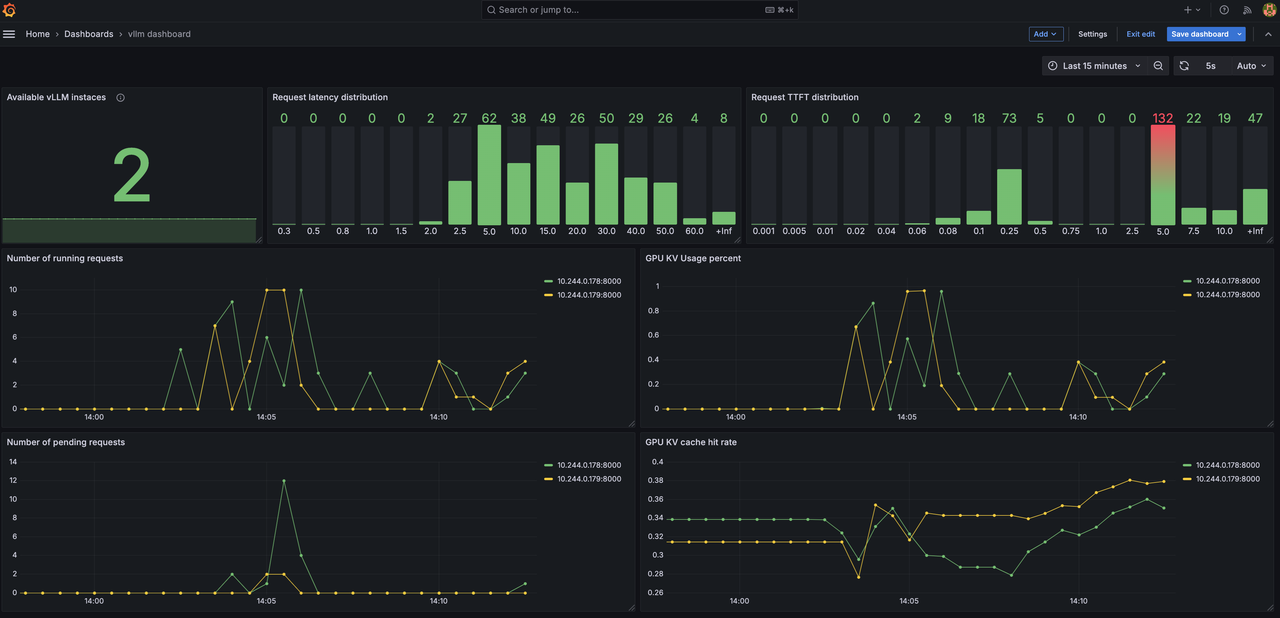
优势 #3:轻松监控
通过关键指标(包括延迟分布、随时间变化的请求数量、KV 缓存命中率),实时跟踪您的 LLM 推理集群。
结论
我们很高兴推出 vLLM Production Stack——将 vLLM 从一流的单节点引擎转变为全规模 LLM 服务系统的下一步。我们相信 vLL stack 将为寻求构建、测试和部署大规模 LLM 应用程序的组织打开新的大门,同时不牺牲性能或简易性。
如果您和我们一样兴奋,请不要等待!
- 克隆仓库:https://github.com/vllm-project/production-stack
- 试用一下
- 请告诉我们您的想法!
- 兴趣表单
加入我们,共同构建一个未来,让每个应用程序都能可靠地、大规模地、轻松地利用 LLM 推理的力量。部署愉快!
联系方式