vLLM 中的结构化解码:简明介绍
摘要:
- 结构化解码允许精确控制大语言模型(LLM)的输出格式
- vLLM 现在支持 outlines 和 XGrammar 两种后端进行结构化解码
- 最近集成的 XGrammar 在负载下将每个输出 Token 的时间(TPOT)提升了高达 5 倍
- 即将发布的 v1 版本将专注于性能增强和调度层级的掩码广播,以支持混合请求的批处理
vLLM 是一个用于运行大型语言模型(LLM)的高吞吐量、高效率的推理引擎。在本文中,我们将探讨语言模型的历史及其注解,介绍 vLLM 中结构化解码的现状,最近与 XGrammar 的集成,并分享我们未来改进的初步路线图。
我们还邀请用户从哲学的角度来探讨这篇博客文章,并在此过程中尝试提出一个观点:结构化解码代表了我们思考 LLM 输出方式的根本性转变。它在构建复杂的智能体(agentic)系统中也扮演着重要角色。
有关 vLLM 的更多信息,请查阅我们的文档。
语言模型:简要历史背景
1950年,艾伦·图灵提出,一台高速数字计算机,通过规则编程,可以展现出智能的涌现行为(Turing, 1950)。这催生了人工智能发展的两条主要路径:
-
传统人工智能(GOFAI):20世纪50年代,研究人员中迅速出现了一种范式,即设计专家系统来复制人类专家的决策能力1(或称符号推理系统)。Haugland 将其称为“传统人工智能”(GOFAI)(Haugeland, 1997)。然而,由于其语义表示无法扩展到通用任务,它很快遇到了资金问题(这一时期也被称为“人工智能的冬天”(Hendler, 2008))。
-
新兴人工智能(NFAI):与此同时,Donald Norman 的并行分布式处理(Rumelhart et al., 1986)小组研究了 Rosenblatt 感知机(Rosenblatt, 1958)的变体,他们在网络中除了输入和输出层外,还提出了“隐藏层”的概念,以根据其在训练过程中学到的知识来推断出适当的响应。这些联结主义网络通常建立在统计方法之上2。鉴于数据的丰富性和摩尔定律3带来的前所未有的计算能力,我们看到联结主义网络在研究和生产用例中占据了主导地位,尤其是在文本生成任务中,各种仅解码器(decoder-only)的 Transformer 模型4尤为突出。因此,大多数现代 Transformer 变体被认为是新兴人工智能(NFAI)系统。
总结如下
- 传统人工智能(GOFAI)是基于规则的确定性系统,其意图性通过显式编程注入
- 新兴人工智能(NFAI)通常被认为是“黑箱”模型(输入 -> 某种输出),由数据驱动,其内部表示具有网络复杂性的特点
为什么我们需要结构化解码?

LLM 擅长以下启发式任务:给定一段文本,模型会生成一段它预测为最可能出现的连续文本。例如,如果你给它一篇维基百科文章,模型应该能生成与该文章其余部分风格一致的文本。
这些模型在以下假设下表现良好:输入提示必须围绕用户想要解决的问题,并且是连贯且结构良好的。换句话说,当你需要特定格式的输出时,LLM 可能会变得不可预测。想象一下让模型生成 JSON——在没有指导的情况下,它可能会产生虽然是有效的文本,但却破坏了 JSON 规范5。
这就是结构化解码发挥作用的地方。它使 LLM 能够在保持系统非确定性本质的同时,生成遵循所需结构的输出。
像 OpenAI 这样的公司已经认识到这一需求,并实现了诸如 JSON 模式之类的功能,以约束6输出格式。如果你之前构建过类似功能(如智能体工作流、函数调用、编码助手),那么你很可能在底层使用了结构化解码。
引导式解码之于 LLM,就如同验证之于 API——它保证了输出与你的预期相符。引导式解码确保了结构的完整性,让开发者能轻松地将 LLM 集成到他们的应用程序中!
结构化解码与 vLLM
简单来说,结构化解码为 LLM 提供了一个可遵循的“模板”。用户提供一个模式(schema),该模式会“影响”模型的输出,确保其符合期望的结构。

从技术角度看,推理引擎可以通过对来自任何给定模式的所有词元(token)应用偏置(通常通过 logit 掩码)来修改下一个词元的概率分布。为了应用这些偏置,outlines 提出了通过有限状态机(FSM)为任何给定模式进行引导式生成的方法(Willard & Louf, 2023)。这使我们能够在解码过程中跟踪当前状态,并通过向输出应用 logit 偏置来过滤掉无效的词元。
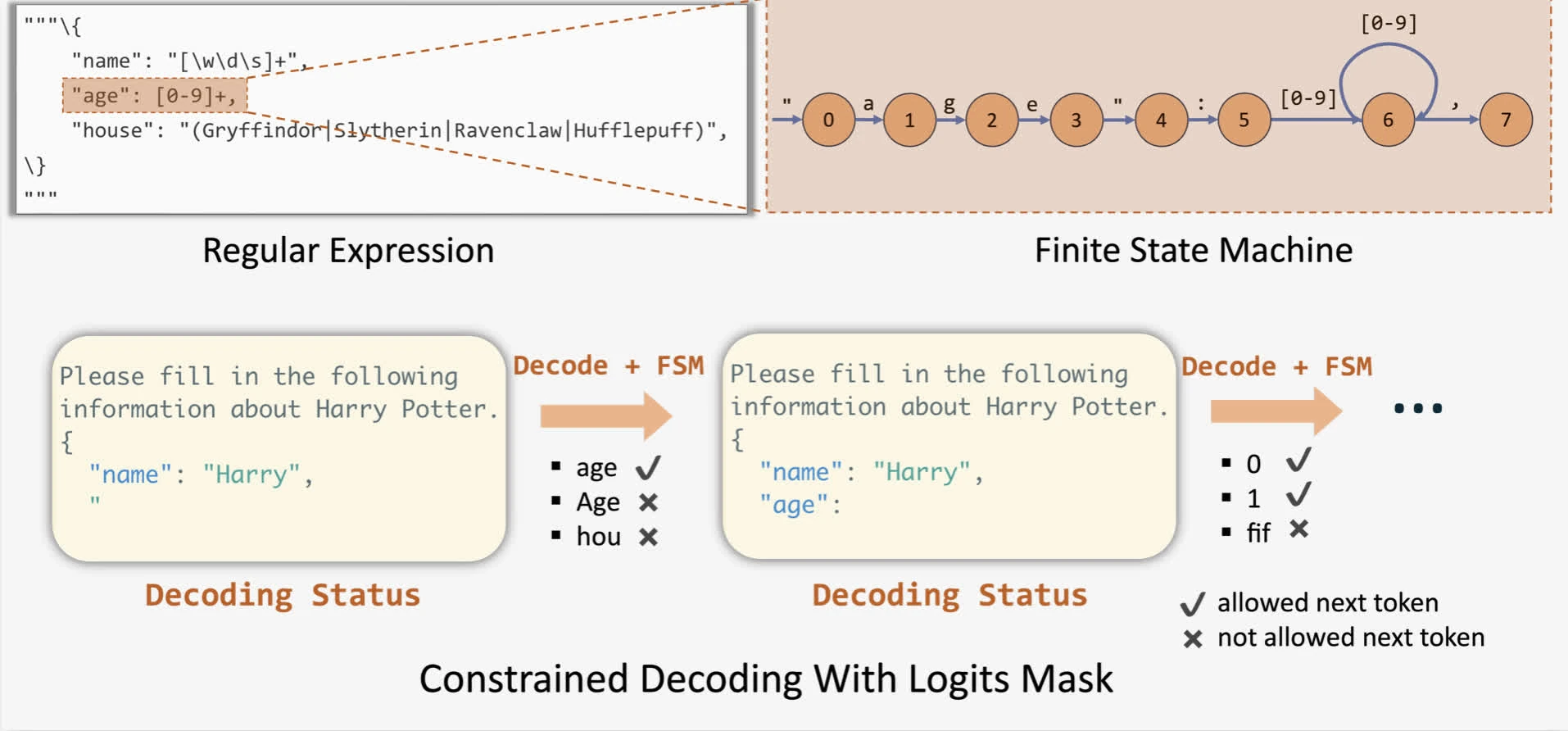
在 vLLM 中,你可以通过向采样参数(通过 Python SDK 或 HTTP 请求)传递一个 JSON 模式来使用此功能。
注意:在某些情况下,它甚至可以提升 LLM 的原生解码性能!
vLLM 以往的局限性
当前 vLLM 对 Outlines 后端的支持存在一些局限性:
- 解码速度慢:FSM 必须在词元级别构建,这意味着它每步只能转换一个词元的状态。因此,它每次只能解码*一个*词元,导致解码速度缓慢。
- 批处理瓶颈:vLLM 中的实现严重依赖于 logit 处理器7。因此,这位于采样过程的关键路径上。在批处理用例中,为每个请求编译 FSM 以及同步计算掩码意味着批次中的所有请求都会被阻塞,导致首个词元生成时间(TTFT)过高,吞吐量降低。
- 我们发现,编译 FSM 是一项相对耗时的任务,是导致 TTFT 增加的一个重要原因。
- CFG 模式下的性能问题:在使用 outlines 集成时,虽然 JSON 模式相对较快,但 CFG 模式运行速度明显较慢,并且偶尔会导致引擎崩溃。
- 对高级功能的支持有限:像前瞻解码(jump-forward decoding)这样的技术目前无法通过 logit 处理器方法实现。它需要预填充一组 k 个下一个词元,而 logit 处理器只能处理下一个词元。
与 XGrammar 的集成
XGrammar 引入了一种新技术,通过下推自动机(PDA)实现批量约束解码。你可以将 PDA 想象成“一组 FSM 的集合,其中每个 FSM 代表一个上下文无关文法(CFG)”。PDA 的一个显著优势是其递归性,允许我们执行多个状态转换。它们还包括额外的优化(感兴趣的读者可以查看),以减少文法编译的开销。
这一进步将文法编译从 Python 移至 C 语言,并利用 pthread,从而解决了局限性 (1)。此外,XGrammar 为在未来版本中解决局限性 (4) 奠定了基础。以下是 XGrammar 和 Outlines 后端的性能比较:
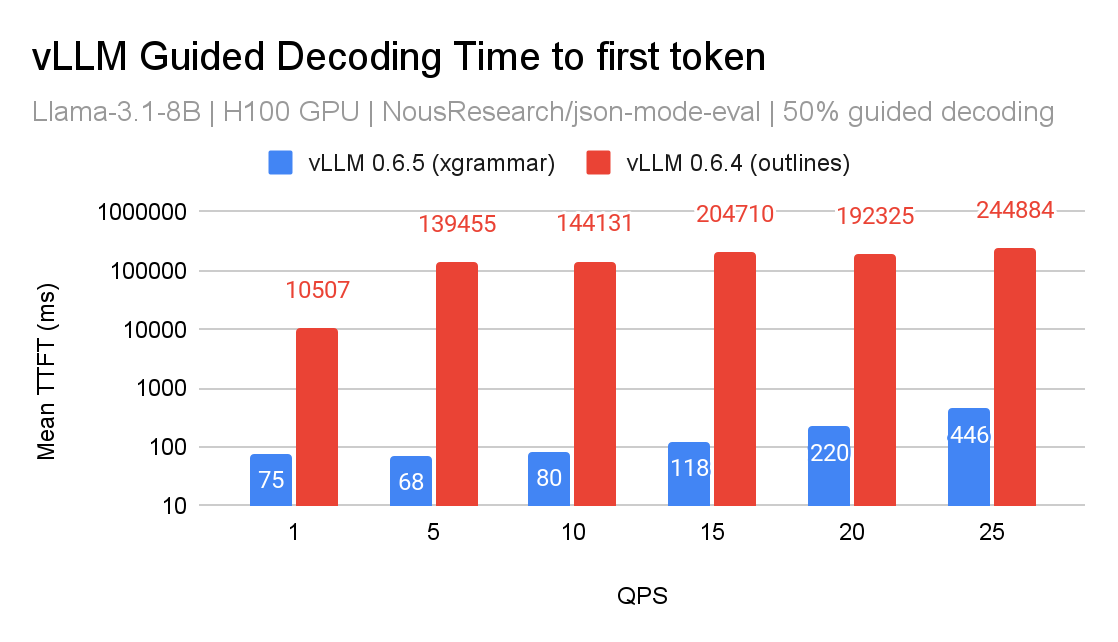
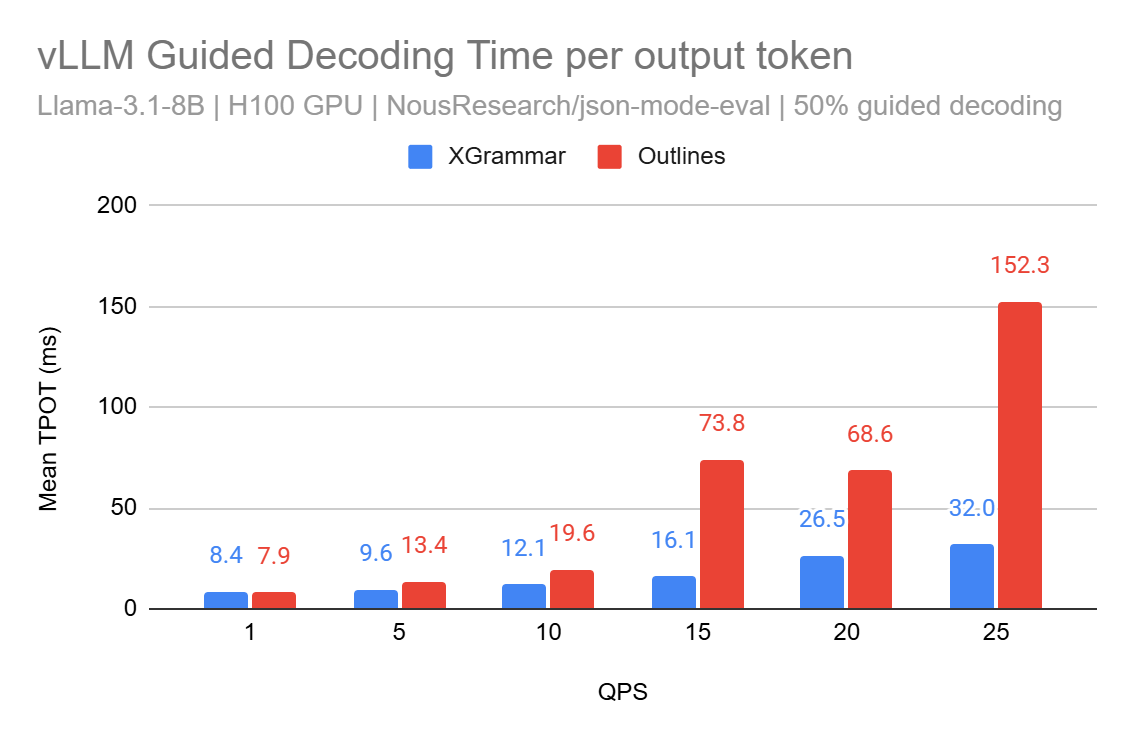
在 vLLM 的 v0 架构中,我们将 XGrammar 实现为一个 logit 处理器,并利用缓存对分词器数据进行了优化。虽然性能提升令人鼓舞,但我们相信仍有巨大的优化空间。
在 XGrammar v0 的集成中,仍有一些可用性问题需要解决,以匹配所有用例的功能对等性:
- 它尚未支持 GBNF 格式以外的文法(vLLM 上的 PR: github)
- 它尚未支持正则表达式
- 它尚未支持使用正则表达式模式或数值范围的复杂 JSON
- 有几个 PR 试图解决这些用法。一个是 vLLM 上的错误修复 PR,另一个是上游 PR。
vLLM 现在默认基本支持 XGrammar。在我们知道 XGrammar 不足以处理请求的情况下,我们会回退到 Outlines。
请注意,vLLM 也包含了对 lm-format-enforcer 的支持。然而,根据我们的测试,我们发现在一些长上下文测试用例中,lm-format-enforcer 无法强制执行正确的输出,并且在性能方面也不及 Outlines。
v1 版本的初步计划
随着 v1 版本即将发布,我们正在为结构化解码制定一个初步计划:
- 将引导式解码移至调度器层面
- 原因:在调度器层面,我们能更好地了解哪些请求使用了结构化解码,因此它不应该阻塞批处理中的其他请求(初步解决局限性 (2))。从某种意义上说,这将引导式解码移出了关键路径。
- 这将允许与前瞻解码进行更自然的垂直整合(解决局限性 (4))。
- 允许在一个进程中计算位掩码,而不是在每个 GPU 工作进程中计算
- 原因:我们可以将这个位掩码广播给每个 GPU 工作进程,而不是在每个 GPU 工作进程中重复这个过程。
- 我们将仔细分析为每个使用引导式解码的请求的每个样本广播掩码所带来的带宽影响。
- 为推测解码和工具使用提供良好基础
- 原因:XGrammar 计划支持工具使用,这样我们就可以摆脱 Python 的工具解析器。
- 推测解码中的树评分可以与前瞻解码使用相同的 API(这取决于在调度器层面集成引导式解码)。
注意:如果您有任何更多的建议,我们非常乐意考虑。欢迎通过 #feat-structured-output 频道加入 vLLM slack。
致谢
我们感谢 vLLM 团队、XGrammar 团队、Aaron Pham (BentoML)、Michael Goin (Red Hat)、Chendi Xue (Intel) 和 Russell Bryant (Red Hat) 在将 XGrammar 引入 vLLM 过程中的宝贵反馈与合作,以及为改进 vLLM 中的结构化解码所付出的持续努力。
参考文献
- Bahdanau, D., Cho, K., & Bengio, Y. (2016). Neural Machine Translation by Jointly Learning to Align and Translate. arXiv preprint arXiv:1409.0473
- Haugeland, J. (1997). Mind Design II: Philosophy, Psychology, and Artificial Intelligence. The MIT Press. https://doi.org/10.7551/mitpress/4626.001.0001
- Hendler, J. (2008). Avoiding Another AI Winter. IEEE Intelligent Systems, 23(2), 2–4. https://doi.org/10.1109/MIS.2008.20
- Hochreiter, S., & Schmidhuber, J. (1997). Long Short-Term Memory. Neural Computation.
- Kaplan, J., McCandlish, S., Henighan, T., Brown, T. B., Chess, B., Child, R., Gray, S., Radford, A., Wu, J., & Amodei, D. (2020). Scaling Laws for Neural Language Models. arXiv preprint arXiv:2001.08361
- Mikolov, T., Chen, K., Corrado, G., & Dean, J. (2013). Efficient Estimation of Word Representations in Vector Space. arXiv preprint arXiv:1301.3781
- Rosenblatt, F. (1958). The perceptron: A probabilistic model for information storage and organization in the brain. Psychological Review, 65(6), 386–408. https://doi.org/10.1037/h0042519
- Rumelhart, D. E., McClelland, J. L., & Group, P. R. (1986). Parallel Distributed Processing, Volume 1: Explorations in the Microstructure of Cognition: Foundations. The MIT Press. https://doi.org/10.7551/mitpress/5236.001.0001
- Shortliffe, E. H. (1974). MYCIN: A Rule-Based Computer Program for Advising Physicians Regarding Antimicrobial Therapy Selection (Technical Report STAN-CS-74-465). Stanford University.
- Statistical Machine Translation. (n.d.). IBM Models. Statistical Machine Translation Survey. http://www2.statmt.org/survey/Topic/IBMModels
- Turing, A. M. (1950). i.—Computing Machinery And Intelligence. Mind, LIX(236), 433–460. https://doi.org/10.1093/mind/LIX.236.433
- Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, L., & Polosukhin, I. (2023). Attention Is All You Need. arXiv preprint arXiv:1706.03762
- Willard, B. T., & Louf, R. (2023). Efficient Guided Generation for Large Language Models. arXiv preprint arXiv:2307.09702
-
艾伦·纽厄尔和赫伯特·西蒙在兰德公司(RAND)的初步工作表明,计算机可以模拟智能的重要方面。
另一个著名的应用出现在医疗领域(Haugeland, 1997)。20世纪70年代,斯坦福大学开发的 MYCIN 系统可以诊断血液感染并推荐治疗方案(Shortliffe, 1974)。MYCIN 的开发者认识到为建议提供理由的重要性,他们实现了所谓的“规则追溯”功能,以人类可理解的方式解释系统的推理过程。↩
-
在20世纪90年代,IBM 发布了一系列复杂的统计模型,这些模型被训练用于执行机器翻译任务(Statistical Machine Translation, n.d.)(另请参阅:康奈尔大学的这堂课)。
2001年,一种基于词袋模型(BoW)变体的模型在 3 亿个词元上进行了训练,并在当时被认为是业界顶尖水平(Mikolov et al., 2013)。这些早期工作向研究界证明,统计建模在语言处理方面优于符号方法,因为它能捕捉大量文本语料库的普遍模式。↩
-
2017年,里程碑式的论文《Attention is all You Need》为神经机器翻译任务引入了 Transformer 架构(Vaswani et al., 2023),该架构基于(Bahdanau et al., 2016)首次提出的注意力机制。
随后,OpenAI 引入了神经语言模型的缩放定律(Kaplan et al., 2020),这引发了基于基础语言模型构建这些系统的竞赛。↩
-
在基于注意力的 Transformer 出现之前,序列到序列(seq-to-seq)模型使用循环神经网络(RNN),因为它们具有更长的上下文长度和更好的记忆能力。然而,与前馈网络相比,RNN 更容易出现梯度消失/爆炸问题,因此 LSTM(Hochreiter & Schmidhuber, 1997)被提出来解决这个问题。然而,LSTM 的一个主要问题是,它们对于很久以前见过的数据,记忆回忆能力较差。
注意力机制的论文通过在输入中编码额外的位置数据来解决这个问题。该论文还额外提出了一种用于翻译任务的编码器-解码器架构,然而,现在大多数文本生成模型都是仅解码器(decoder-only)的,因为它们在零样本任务上表现更优。
基于注意力的 Transformer 比 LSTM 效果更好的众多原因之一是,Transformer 非常具有可扩展性和硬件感知能力(你不能随意增加 LSTM 模块并期望获得更好的长期记忆保留)。更多信息,请参阅原始论文。↩
-
有人可能会争辩说,我们可以通过少样本提示(few-shot prompting)来可靠地实现这些,例如“给我一个能返回用户地址的 JSON。输出示例可以是……”。然而,这并不能保证生成的输出是有效的 JSON。这是因为这些模型是概率系统,它们是根据其训练数据的分布来“采样”下一个结果的。
也有人可能会争辩说,应该使用专门为 JSON 输出微调的模型来执行此类任务。然而,微调通常需要大量的训练和更多的人力来整理数据、监控进度和进行评估,这是一项巨大的资源投入,并非人人都能负担得起。↩
-
请注意,“[结构化/约束/引导式]解码”(structured/constrained/guided decoding)这些术语可以互换使用,但它们都指的是同一种机制,即“使用一种格式来让模型结构化地采样输出”。↩