vLLM 2024 回顾与 2025 展望
vLLM 社区在 2024 年取得了显著增长,从一个专业的推理引擎发展成为开源 AI 生态系统中事实上的服务解决方案。 这种转变反映在我们的增长指标中
- GitHub 星星数从 14,000 增长到 32,600 (增长 2.3 倍)
- 贡献者人数从 190 扩展到 740 (增长 3.8 倍)
- 月下载量从 6,000 激增至 27,000 (增长 4.5 倍)
- GPU 小时数在过去六个月内增长了约 10 倍
- 在 https://2024.vllm.ai 探索更多使用数据
vLLM 已确立其作为领先的开源 LLM 服务和推理引擎的地位,并在生产应用中得到广泛采用(例如,为 Amazon Rufus 和 LinkedIn AI 功能提供支持)。我们的双月例会已成为与 IBM、AWS 和 NVIDIA 等行业领导者建立合作伙伴关系的战略聚会,标志着我们在成为开源 AI 生态系统的通用服务解决方案方面取得了进展。 继续阅读以了解有关 vLLM 2024 年成就和 2025 年路线图的更多详细信息!
这篇博客基于双周 vLLM 办公时间 的第 16 次会议。 在 此处 观看录像。
2024 年成就:扩展模型、硬件和功能
社区贡献与增长
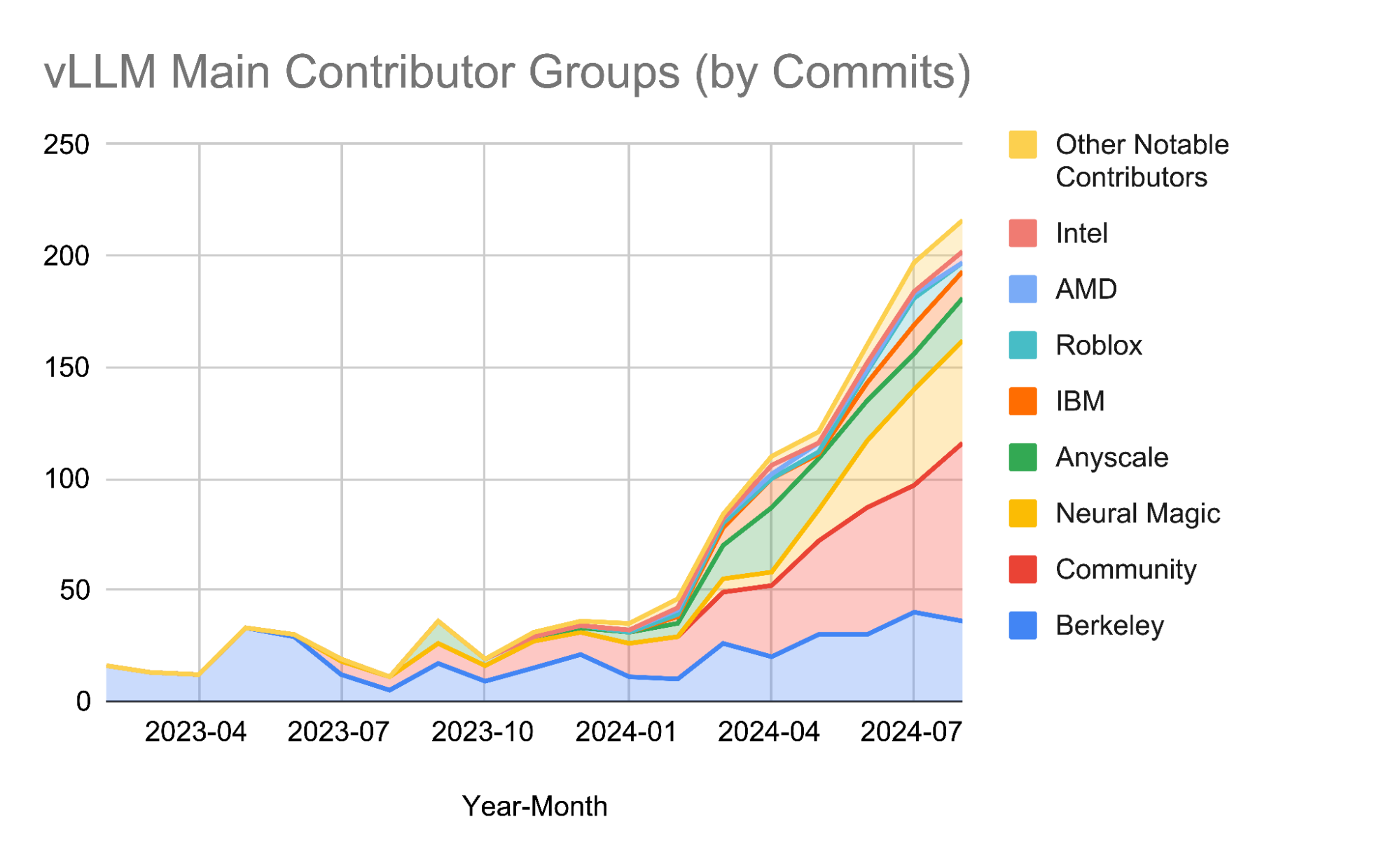
2024 年对 vLLM 来说是卓越的一年! 我们的贡献社区已显著扩展,包括
- 来自 6 个以上组织的 15+ 名全职贡献者
- 20+ 个活跃组织作为主要利益相关者和赞助商
- 来自顶尖机构的贡献,包括加州大学伯克利分校、Neural Magic、Anyscale、Roblox、IBM、AMD、Intel 和 NVIDIA,以及全球各地的个人开发者
- 一个蓬勃发展的生态系统,连接模型创建者、硬件供应商和优化开发者
- 组织良好、参与度高的双周办公时间,促进透明度、社区增长和战略合作伙伴关系
这些数字不仅仅反映了增长,它们还展示了 vLLM 作为 AI 生态系统中关键基础设施的角色,支持从研究原型到为数百万用户提供服务的生产系统的一切。
扩展模型支持
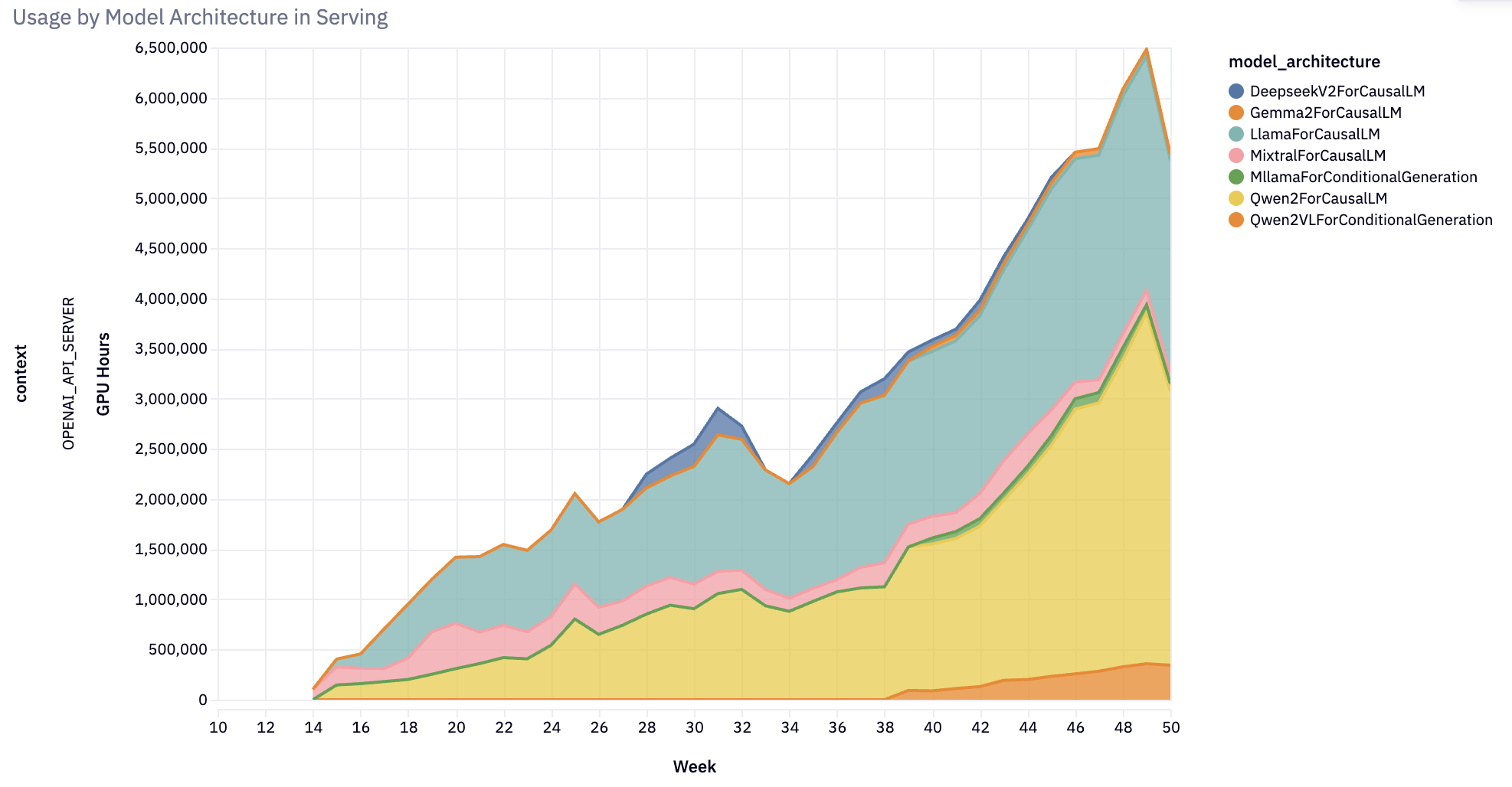
在 2024 年初,vLLM 仅支持少数模型。 到年底,该项目已发展为支持几乎 100 种模型架构 的高性能推理:涵盖几乎所有著名的开源大型语言模型 (LLM)、多模态(图像、音频、视频)、编码器-解码器、推测性解码、分类、嵌入和奖励模型。 值得注意的是,vLLM 推出了对状态空间语言模型的生产支持,探索非 Transformer 语言模型的未来。
拓宽硬件兼容性
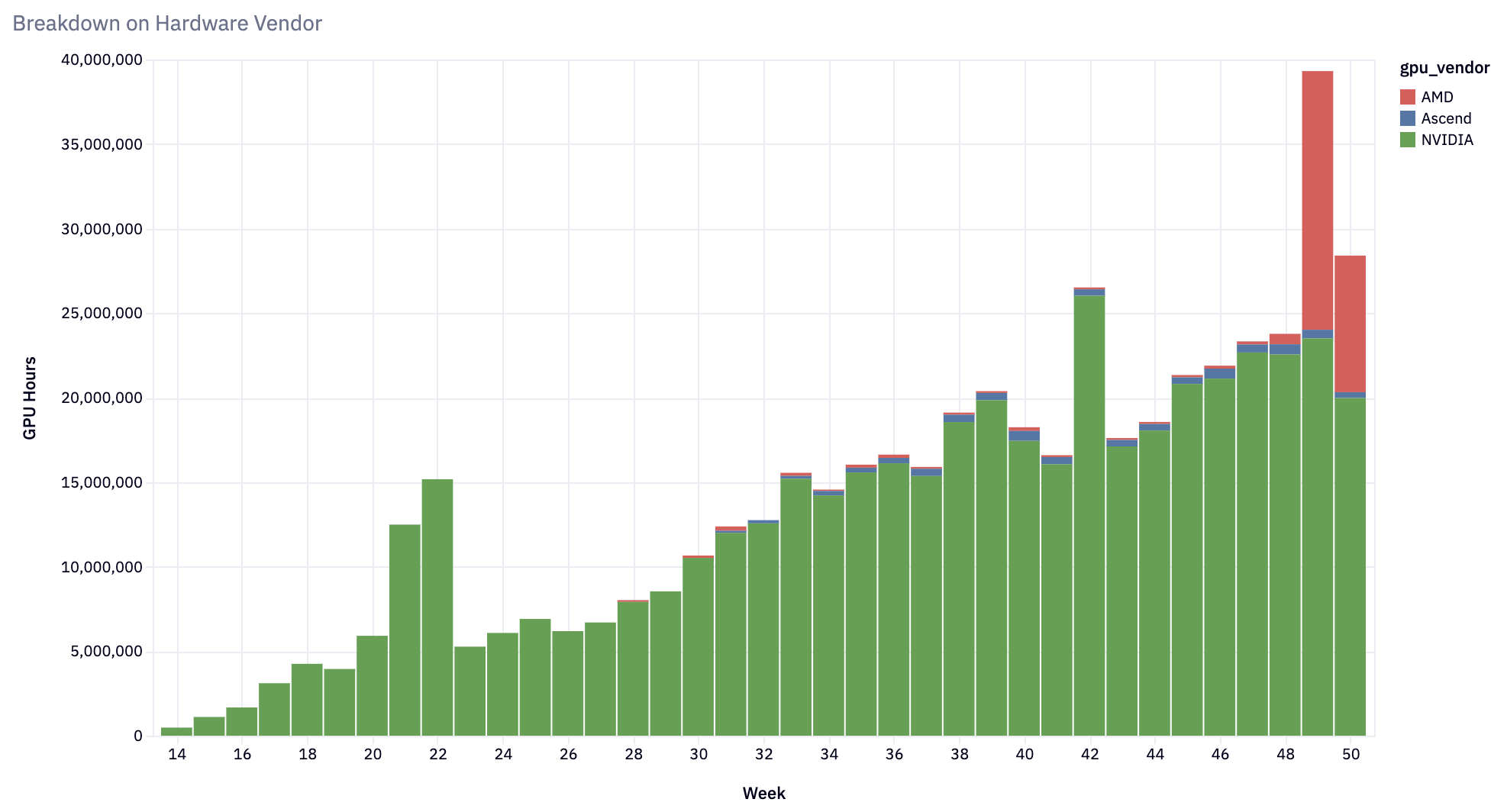
从最初的 NVIDIA A100 GPU 硬件目标开始,vLLM 已扩展到支持
- NVIDIA GPU:针对 H100 的一流优化,并支持从 V100 及更新版本开始的每款 NVIDIA GPU。
- AMD GPU:支持 MI200、MI300 和 Radeon RX 7900 系列 - MI300X 的采用率迅速增长。
- Google TPU:支持 TPU v4、v5p、v5e 和最新的 v6e。
- AWS Inferentia 和 Trainium:支持 trn1/inf2 实例。
- Intel Gaudi (HPU) 和 GPU (XPU):利用 Intel GPU 和 Gaudi 架构进行 AI 工作负载。
- CPU:支持越来越多的 ISA - x86、ARM 和 PowerPC。
vLLM 的硬件兼容性已扩展到满足多样化的用户需求,同时融入了性能改进。 重要的是,vLLM 正在朝着确保所有模型在所有硬件平台上都能工作,并启用所有优化的方向前进。
交付关键功能
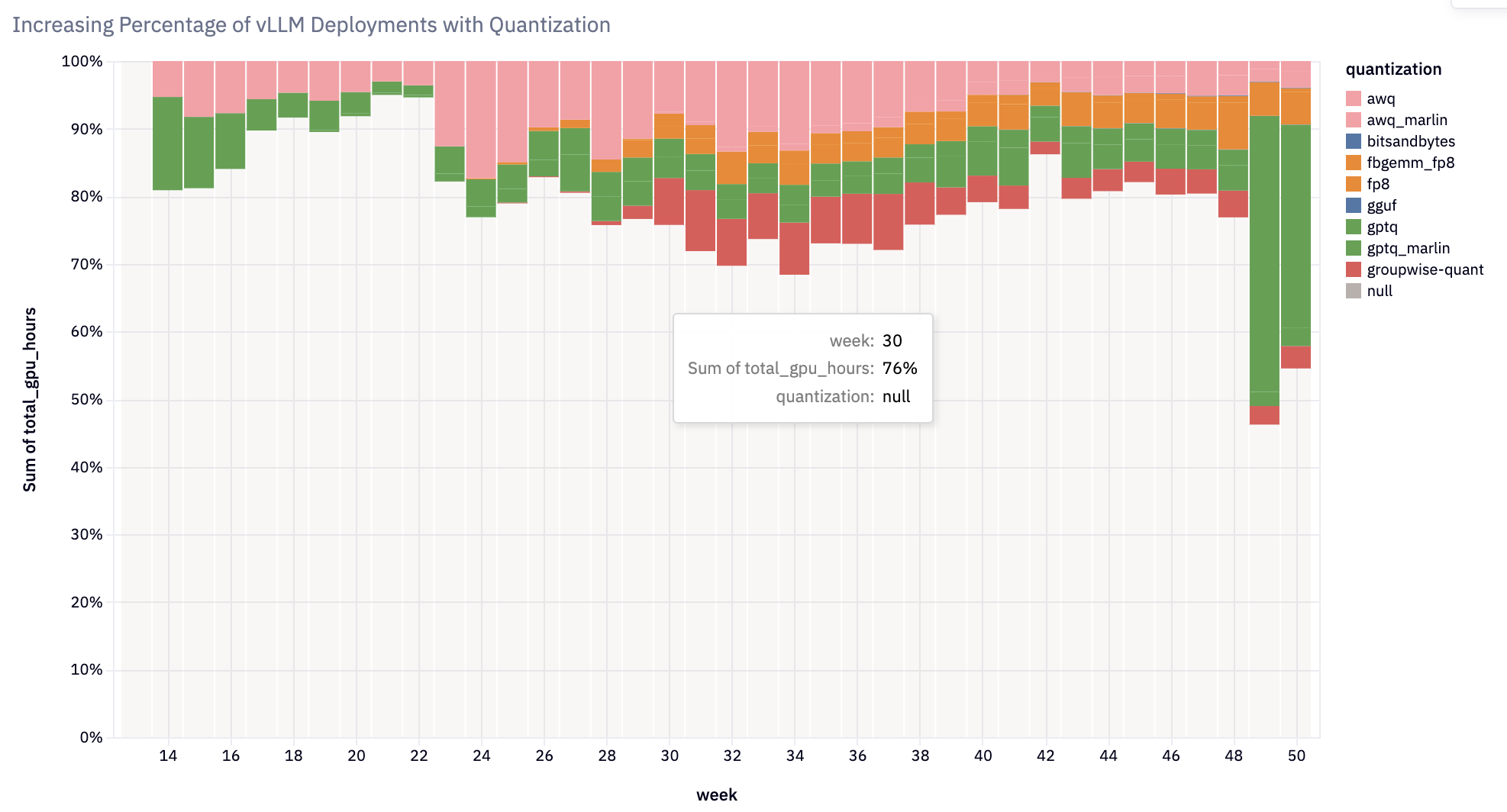
vLLM 2024 年的开发路线图强调了性能、可扩展性和可用性
- 权重和激活量化:增加了对多种量化方法和内核的支持,从而在各种硬件平台上实现高效推理。 值得注意的集成包括 FP8+INT8 的激活量化、用于 GPTQ/AWQ/wNa16 的 Marlin+Machete 内核、FP8 KV 缓存、AQLM、QQQ、HQQ、bitsandbytes 和 GGUF。 现在超过 20% 的 vLLM 部署使用量化。
- 自动前缀缓存:降低了成本并改善了上下文密集型应用的延迟。
- 分块预填充:增强了交互式应用中令牌间延迟的稳定性。
- 推测性解码:通过同步令牌预测和验证加速了令牌生成,支持草稿模型、提示中的 n-gram 匹配以及像 Medusa 或 EAGLE 这样的 MLP 推测器。
- 结构化输出:为需要特定格式(如 JSON 或 pydantic 模式)的应用提供了高性能功能。
- 工具调用:使具有受支持聊天模板的模型能够自主生成工具调用,从而促进数据处理和 Agentic 流程。
- 分布式推理:引入了流水线并行和分解预填充,以有效地跨 GPU 和节点扩展工作负载。
我们的 2025 年展望
在 2025 年,我们预计预训练和推理时扩展的边界将迎来重大突破。 我们相信开源模型正在迅速赶上专有模型,并且通过蒸馏,这些庞大的模型正变得更小、更智能、更适合生产部署。
新兴模型能力:在单节点上服务的 GPT-4o 级别模型
我们的愿景是雄心勃勃且具体的:在单个 GPU 上实现 GPT-4o 级别的性能,在单个节点上实现 GPT-4o,并在适度的集群上实现下一代规模能力。 为了实现这一目标,我们专注于三个关键的优化前沿
-
KV 缓存和注意力优化,包括滑动窗口、跨层注意力以及原生量化
-
MoE 优化,目标是具有共享专家和大量细粒度专家的架构
-
通过状态空间模型等替代架构扩展长上下文支持
除了原始性能之外,我们还在为专门的垂直应用定制 vLLM。 每个用例都需要特定的优化:推理应用需要自定义令牌和灵活的推理步骤,编码需要中间填充功能和提示查找解码,Agent 框架受益于基于树的缓存,而创意应用需要多样化的采样策略,包括束搜索变体和对比解码。
我们还在扩展 vLLM 在模型训练过程中的作用。 最近像 John Schulman 这样的著名研究人员的采用表明我们在后训练工作流程中的重要性日益增加。 我们将提供与数据整理和后训练流程的紧密集成,使 vLLM 成为整个 AI 开发生命周期中的重要工具。
实际规模:为数千个生产集群提供动力
随着 LLM 成为现代应用的主干,我们设想 vLLM 为数千个 24/7 全天候运行的生产集群提供动力。 这些不是实验性部署,而是处理产品功能持续流量的关键任务系统,由专门的平台团队维护。
为了支持这种规模,我们正在使 vLLM 真正成为生产应用的开箱即用解决方案。 量化、前缀缓存和推测性解码将成为默认功能,而不是可选优化。 结构化输出生成将成为标准而不是例外。 我们正在开发全面的路由、缓存和自动扩展方案,涵盖生产部署的完整生命周期。
随着部署规模超出单个副本,我们正在为集群级解决方案创建稳定的接口。 这包括针对常用模型和硬件平台调整的稳健默认配置,以及针对各种用例的灵活优化路径。 我们正在培养一个致力于推动 vLLM 效率边界的社区,确保我们的平台不断发展以迎接新的挑战。
开放架构:我们未来的基础
vLLM 持续成功的关键在于其开放架构。 我们正在推出 V1 版本的全新架构,这体现了这一理念。 从模型架构到调度策略,从内存管理到采样策略,每个组件都旨在在研究和私有分支中进行修改和扩展。
我们对开放性的承诺不仅限于代码。 我们正在引入
-
用于无缝集成新模型、硬件后端和自定义扩展的可插拔架构
-
一流的
torch.compile支持,实现自定义操作融合传递和快速实验 -
一个灵活的组件系统,在保持核心稳定性的同时支持私有扩展
我们正在加倍投入社区发展,协调跨组织的工程工作,同时庆祝生态系统项目。 这包括通过明确的招聘流程和组织结构来壮大我们的核心团队。 我们的目标不仅仅是使 vLLM 在技术上成为最佳选择,而是确保每个投资 vLLM 的人都因这样做而变得更好。
我们的架构不仅仅是一个技术选择; 它更是通过可扩展性和修改而不是锁定来创建一个互联生态系统的承诺。 通过使 vLLM 既强大又可定制,我们确保了它在 AI 推理生态系统中的核心地位。
一点反思
当我们回顾 vLLM 的历程时,一些关键主题浮现出来,这些主题塑造了我们的增长并继续指导我们前进的道路。
在 AI 生态系统中架起桥梁
最初只是一个推理引擎,现在已经发展成为更重要的东西:一个在 AI 领域中连接以前截然不同的世界的平台。 模型创建者、硬件供应商和优化专家在 vLLM 中找到了独特的贡献放大器。 当硬件团队开发新的加速器时,vLLM 可以立即访问广泛的应用生态系统。 当研究人员设计出新颖的优化技术时,vLLM 提供了一个生产就绪的平台来展示现实世界的影响。 这种贡献和放大的良性循环已成为我们身份的核心,推动我们不断提高平台的可访问性和可扩展性。
在保持卓越的同时管理增长
我们在 2024 年的指数级增长带来了机遇和挑战。 代码库和贡献者群体的快速扩张创造了前所未有的速度,使我们能够应对雄心勃勃的技术挑战并快速响应社区需求。 然而,这种增长也增加了我们代码库的复杂性。 我们没有让技术债务累积,而是果断地选择投资于我们的基础。 2024 年下半年,我们对 vLLM 的核心架构进行了雄心勃勃的重新设计,最终形成了我们现在称之为 V1 架构的架构。 这不仅仅是一次技术更新,更是一个深思熟虑的举措,旨在确保我们的平台在扩展以满足不断扩展的 AI 生态系统的需求时,仍然保持可维护性和模块化。
开创开源开发的新模式
也许我们最独特的挑战是通过赞助志愿者网络建立一个世界一流的工程组织。 与依赖单个组织资助的传统开源项目不同,vLLM 正在开辟一条不同的道路。 我们正在创建一个协作环境,多个组织不仅贡献代码,还贡献资源和战略方向。 这种模式在协调、规划和执行方面带来了新的挑战,但也为创新和韧性提供了前所未有的机会。 我们正在学习,有时甚至是在发明,从分布式决策到跨组织边界的远程协作等各个方面的最佳实践。
我们坚定不移的承诺
纵观所有这些变化和挑战,我们的基本使命仍然明确:构建世界上最快、最易于使用的开源 LLM 推理和服务引擎。 我们相信,通过降低高效 AI 推理的门槛,我们可以帮助使先进的 AI 应用更实用,更易于所有人使用。 这不仅仅关乎技术卓越,更关乎创建一个基础,使整个 AI 社区能够更快地共同前进。
使用数据收集
本文中的指标和见解由 vLLM 的 使用系统 提供支持,该系统收集匿名部署数据。 每个 vLLM 实例都会生成一个 UUID 并报告技术指标,包括
- 硬件规格(GPU 数量/类型、CPU 架构、可用内存)
- 模型配置(架构、dtype、张量并行度)
- 运行时设置(量化类型、前缀缓存已启用)
- 部署上下文(云提供商、平台、vLLM 版本)
此遥测数据有助于确定常见硬件配置的优化优先级,并识别哪些功能需要性能改进。 数据在本地 ~/.config/vllm/usage_stats.json 中收集。 用户可以通过设置 VLLM_NO_USAGE_STATS=1、DO_NOT_TRACK=1 或创建 ~/.config/vllm/do_not_track 来选择退出。 实施细节和完整模式可在我们的 使用统计文档 中找到。
加入旅程
vLLM 2024 年的旅程展示了开源协作的变革潜力。 凭借 2025 年的清晰愿景,该项目已准备好重新定义 AI 推理,使其更易于访问、扩展和高效。 无论是通过代码贡献、参加 vLLM 办公时间,还是在生产中采用 vLLM,每位参与者都在帮助塑造这个快速发展的项目的未来。
当我们进入 2025 年时,我们将继续鼓励社区参与,通过
- 贡献代码:帮助改进 vLLM 的核心功能或扩展其功能 - 许多 RFC 和功能需要额外的支持
- 提供反馈:通过 GitHub、Slack、Discord 或活动分享有关功能和用例的见解,以塑造 vLLM 的路线图
- 使用 vLLM 构建:在您的项目中采用该平台,发展您的专业知识,并分享您的经验
加入 vLLM 开发者 Slack,获得项目领导者的指导,并在 AI 推理创新的前沿工作。
携手并进,我们将在 2025 年推进开源 AI 创新!