投机解码如何将 vLLM 性能提升高达 2.8 倍
vLLM 中的投机解码是一项强大的技术,它通过协同利用小型和大型模型来加速令牌生成。在本博客中,我们将深入探讨 vLLM 中的投机解码,其工作原理以及它带来的性能提升。
本内容基于我们双周 vLLM 办公时间的一次会议,我们在会上讨论优化 vLLM 性能的技术和更新。您可以在此处查看会议幻灯片。如果您喜欢观看视频,可以在 YouTube 上观看完整录像。我们很期待您参加未来的会议 - 请注册!
投机解码简介
投机解码 (Leviathan 等人,2023) 是一项在大型语言模型 (LLM) 中减少令牌生成延迟的关键技术。这种方法利用较小的模型来处理较简单的令牌预测,同时利用较大的模型来验证或调整这些预测。通过这样做,投机解码在不牺牲准确性的前提下加速了生成过程,使其成为优化 LLM 性能的一种无损但高效的方法。
为什么投机解码可以减少延迟? 传统上,LLM 以自回归方式一次生成一个令牌。例如,给定一个提示,模型生成三个令牌 T1、T2、T3,每个令牌都需要单独的前向传递。投机解码通过允许在一个前向传递中提出和验证多个令牌来改变这一过程。
以下是该过程的工作原理
- 草稿模型:一个较小、更高效的模型逐个提出令牌。
- 目标模型验证:较大的模型在单个前向传递中验证这些令牌。它确认正确的令牌并纠正任何不正确的令牌。
- 一次传递中处理多个令牌:这种方法不是每次传递生成一个令牌,而是同时处理多个令牌,从而减少延迟。

如上图所示,草稿模型提出了五个令牌:["我", "喜欢", "烹饪", "和", "旅行"]。然后将这些令牌转发到目标模型以进行并行验证。在本例中,第三个令牌“烹饪”(应为“玩耍”)的提议不准确。因此,在此步骤中仅生成前三个令牌 ["我", "喜欢", "玩耍"]。
通过使用这种方法,投机解码加快了令牌生成速度,使其成为小型和大型语言模型部署的有效方法。
vLLM 中投机解码的工作原理
在 vLLM 中,投机解码与系统的连续批处理架构集成,在该架构中,不同的请求在单个批次中一起处理,从而实现更高的吞吐量。vLLM 使用两个关键组件来实现这一点
- 草稿运行器:此运行器负责执行较小的模型以提出候选令牌。
- 目标运行器:目标运行器通过运行较大的模型来验证令牌。
vLLM 的系统经过优化,可以高效地处理此过程,从而使投机解码与连续批处理无缝协作,从而提高整体系统性能。
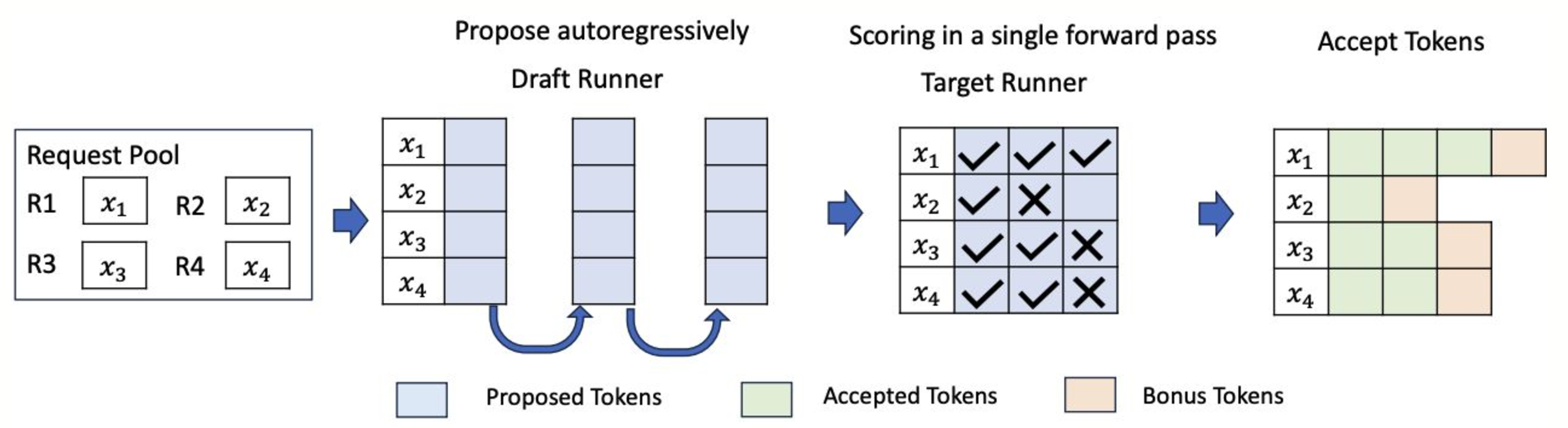
图表说明了草稿运行器和目标运行器如何在 vLLM 批处理系统中交互。
为了在 vLLM 中实现投机解码,必须修改两个关键组件
- 调度器:调整了调度器以处理单个前向传递中的多个令牌槽,从而实现同时生成和验证多个令牌。
- 内存管理器:内存管理器现在处理草稿模型和目标模型的 KV 缓存,确保在投机解码期间的平稳处理。
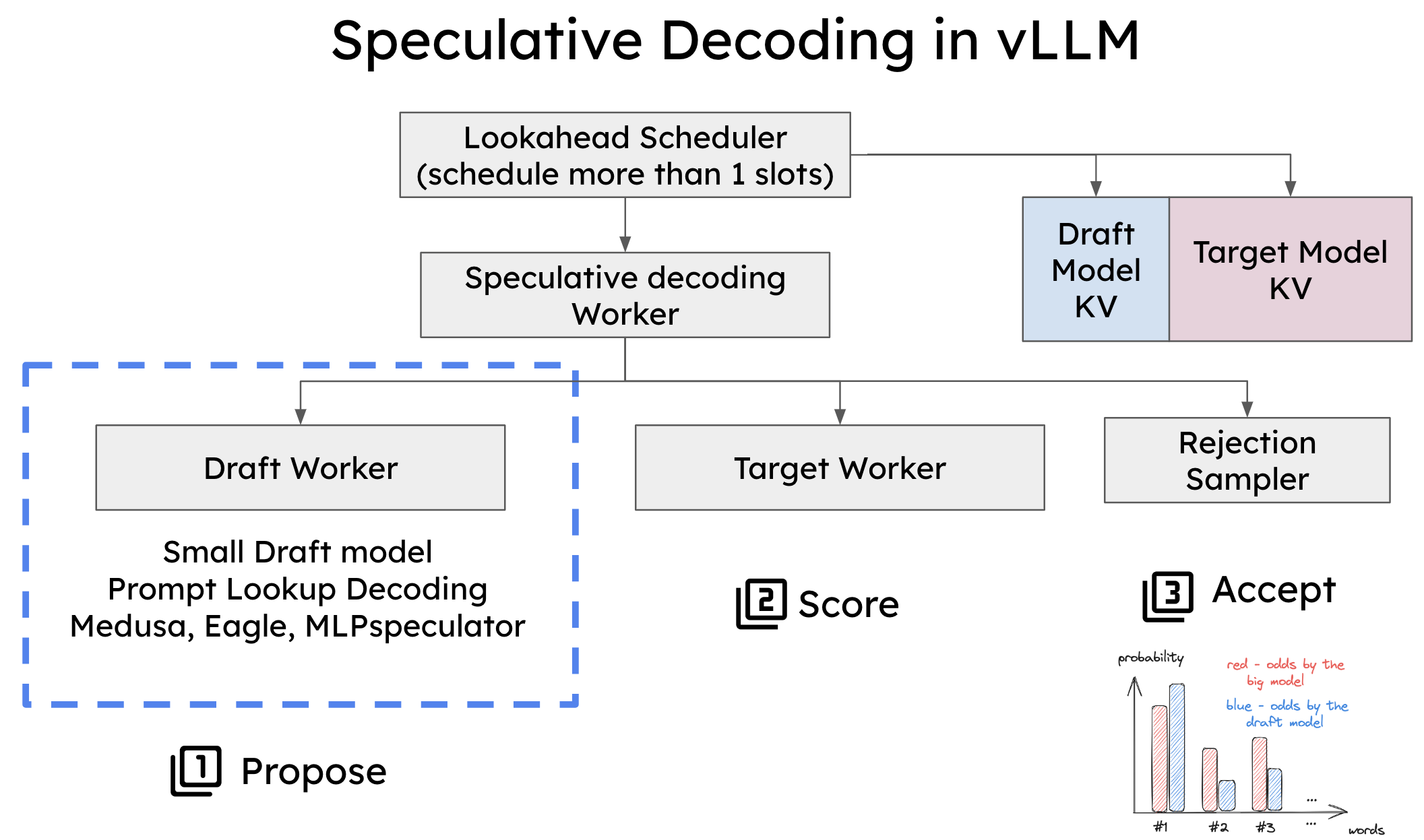
vLLM 中投机解码的系统架构。
vLLM 中支持的投机解码类型
vLLM 支持三种类型的投机解码,每种类型都针对不同的工作负载和性能需求量身定制
基于草稿模型的投机解码
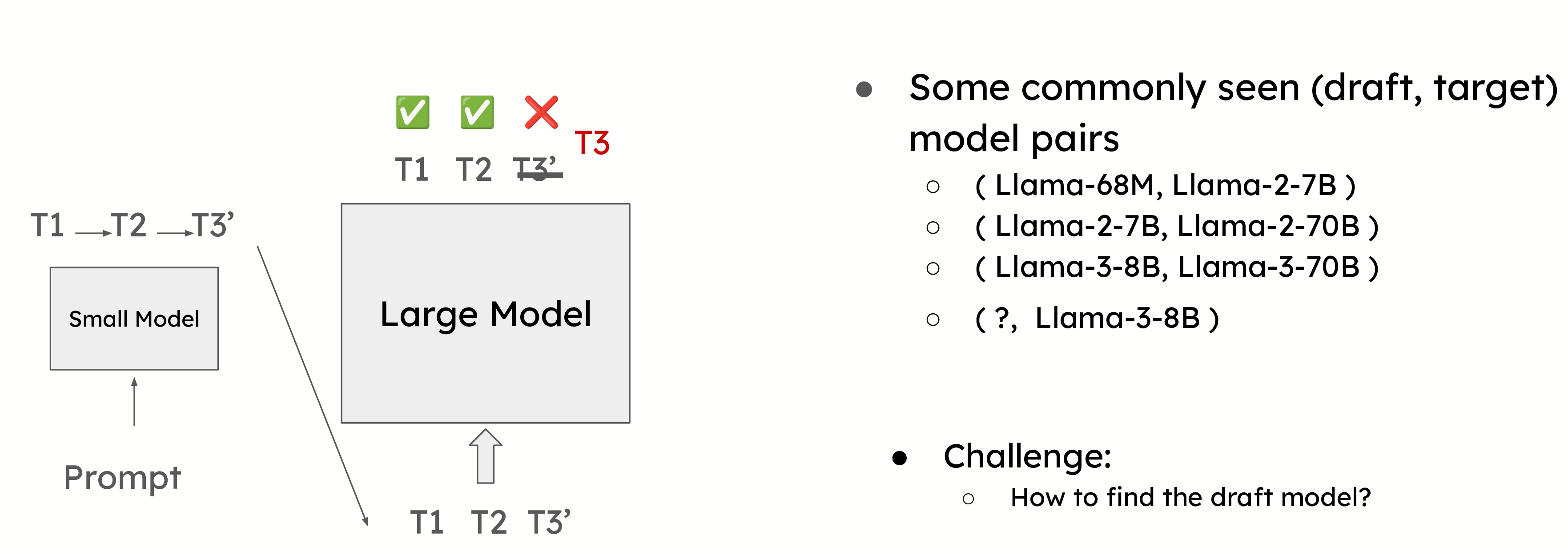
这是最常用的投机解码形式,其中较小的模型预测下一个令牌,而较大的模型验证它们。一个常见的例子是使用 Llama 68M 模型来预测 Llama 2 70B 模型的令牌。这种方法需要仔细选择草稿模型,以平衡准确性和开销。
选择正确的草稿模型对于最大化投机解码的效率至关重要。草稿模型需要足够小,以避免产生显著的开销,但仍要足够准确,以提供有意义的性能提升。
然而,选择合适的草稿模型可能具有挑战性。例如,在像 Llama 3 这样的模型中,由于词汇量大小的差异,很难找到合适的草稿模型。投机解码要求草稿模型和目标模型共享相同的词汇表,在某些情况下,这可能会限制投机解码的使用。因此,在以下部分中,我们将介绍几种无草稿模型的投机解码方法。
提示查找解码
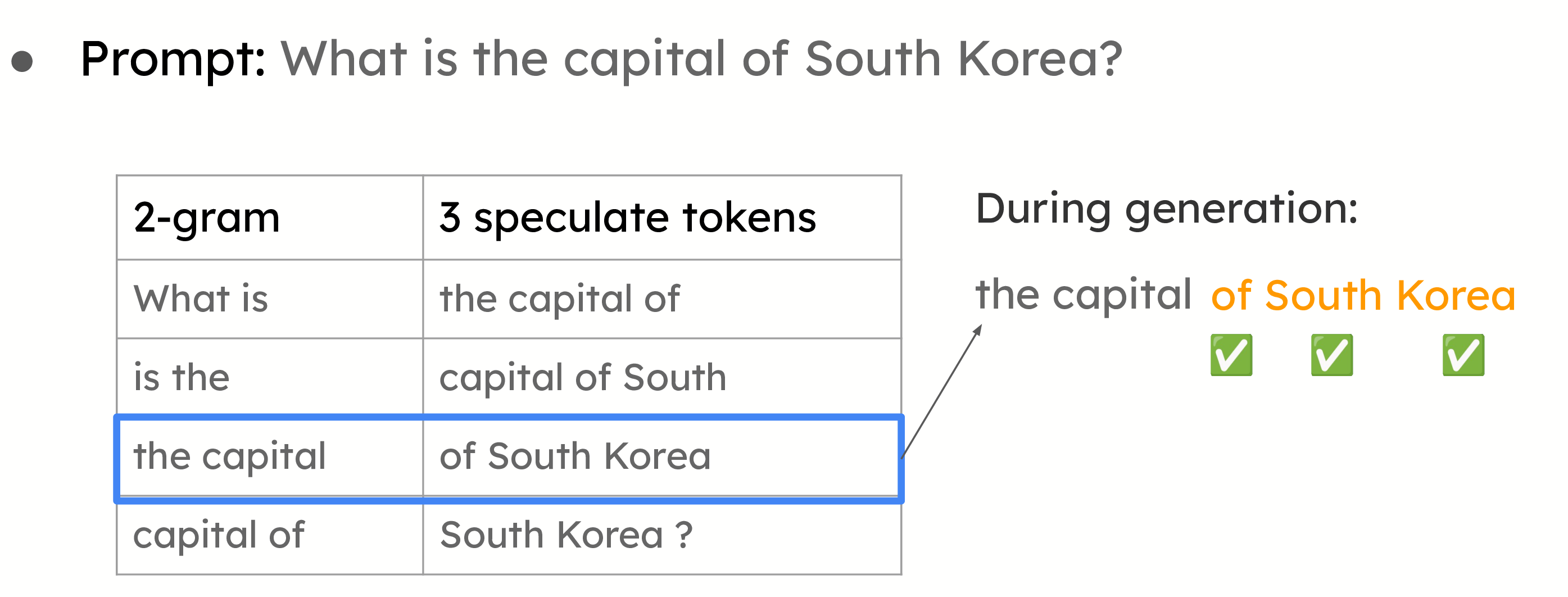
提示查找解码的示例。给定提示,我们将构建所有 2-gram 作为查找键。这些值是查找键后面的三个令牌。在生成过程中,我们将检查当前的 2-gram 是否与任何键匹配。如果匹配,我们将使用该值提议以下令牌。
也称为 n-gram 匹配,这种方法对于摘要和问答等用例非常有效,在这些用例中,提示和答案之间存在显著的重叠。系统不是使用小型模型来提议令牌,而是基于提示中已有的信息进行推测。当大型模型在其答案中重复提示的部分内容时,这种方法尤其有效。
Medusa/Eagle/MLPSpeculator
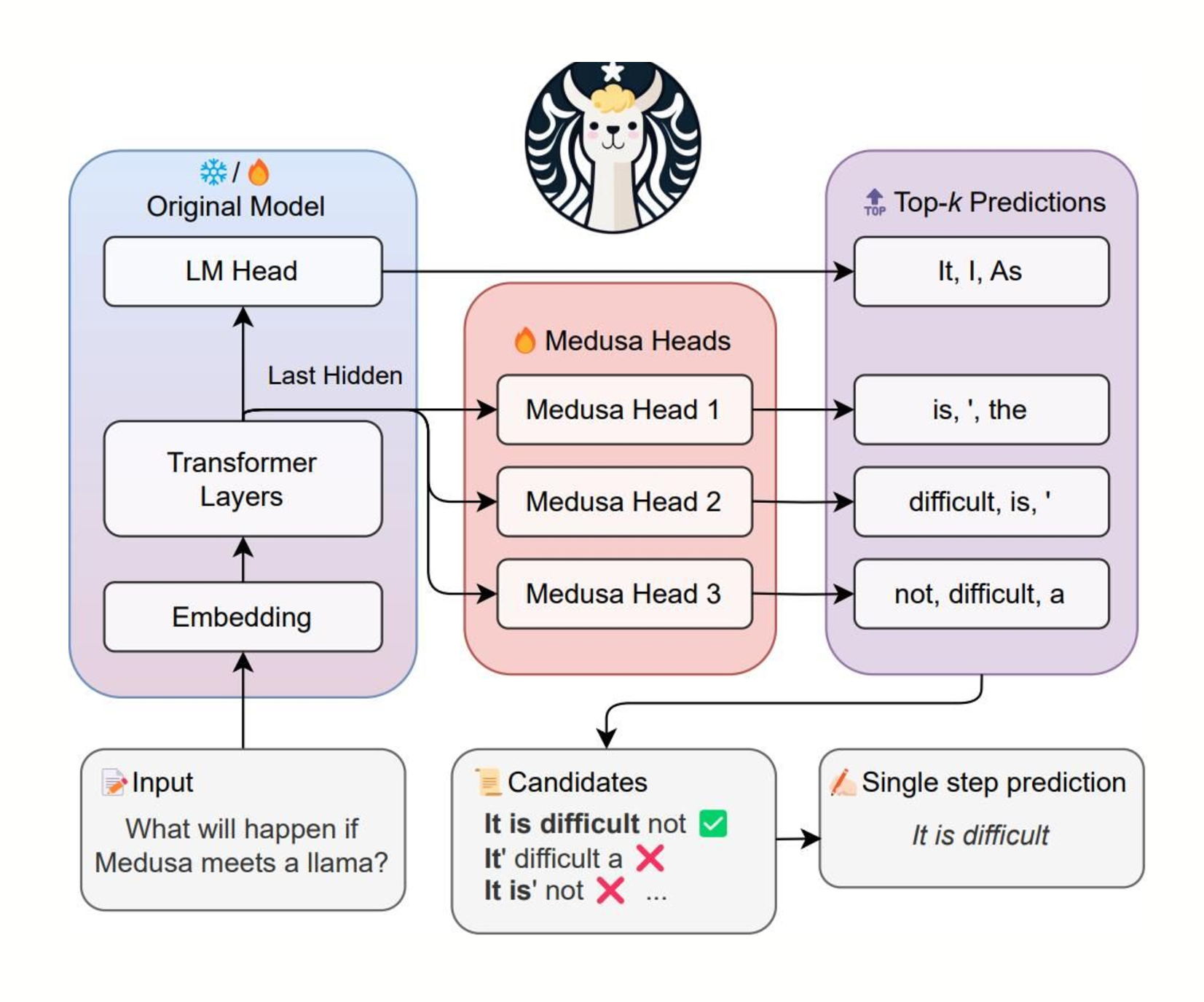
图片来自 https://github.com/FasterDecoding/Medusa。在该示例中,使用三个头来为以下三个位置提议令牌。头 1 为第一个位置提议 ["is", "\'", "the"]。头 2 为第二个位置提议 ["difficult", "is", "\'"]。头 3 为第三个位置提议 ["not", "difficult", "a"]。所有头都将最后一个 Transformer 块的输出作为输入。
在这种方法中,将额外的层(或头)添加到大型模型本身,使其能够在单个前向传递中预测多个令牌。这减少了对单独的草稿模型的需求,而是利用大型模型自身的能力进行并行令牌生成。尽管尚处于初步阶段,但随着更优化的内核的开发,这种方法显示出提高效率的潜力。
投机解码性能洞察:加速和权衡
投机解码在低 QPS(每秒查询数)环境中提供了显著的性能优势。例如,在 ShareGPT 数据集上的测试中,vLLM 在使用基于草稿模型的投机解码时,令牌生成速度提高了 1.5 倍。同样,当应用于摘要数据集(如 CNN/DailyMail)时,提示查找解码也显示出高达 2.8 倍的加速。
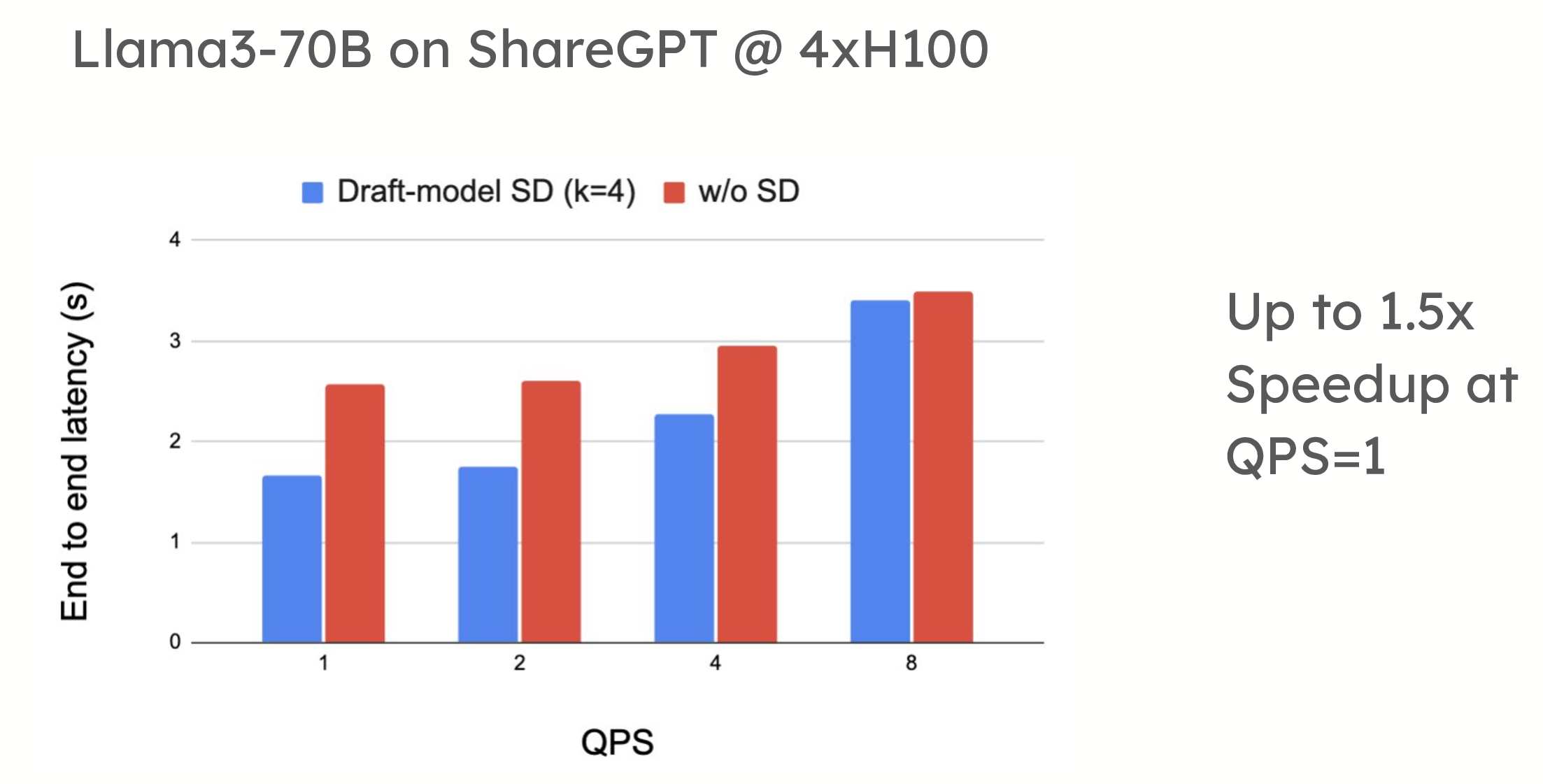
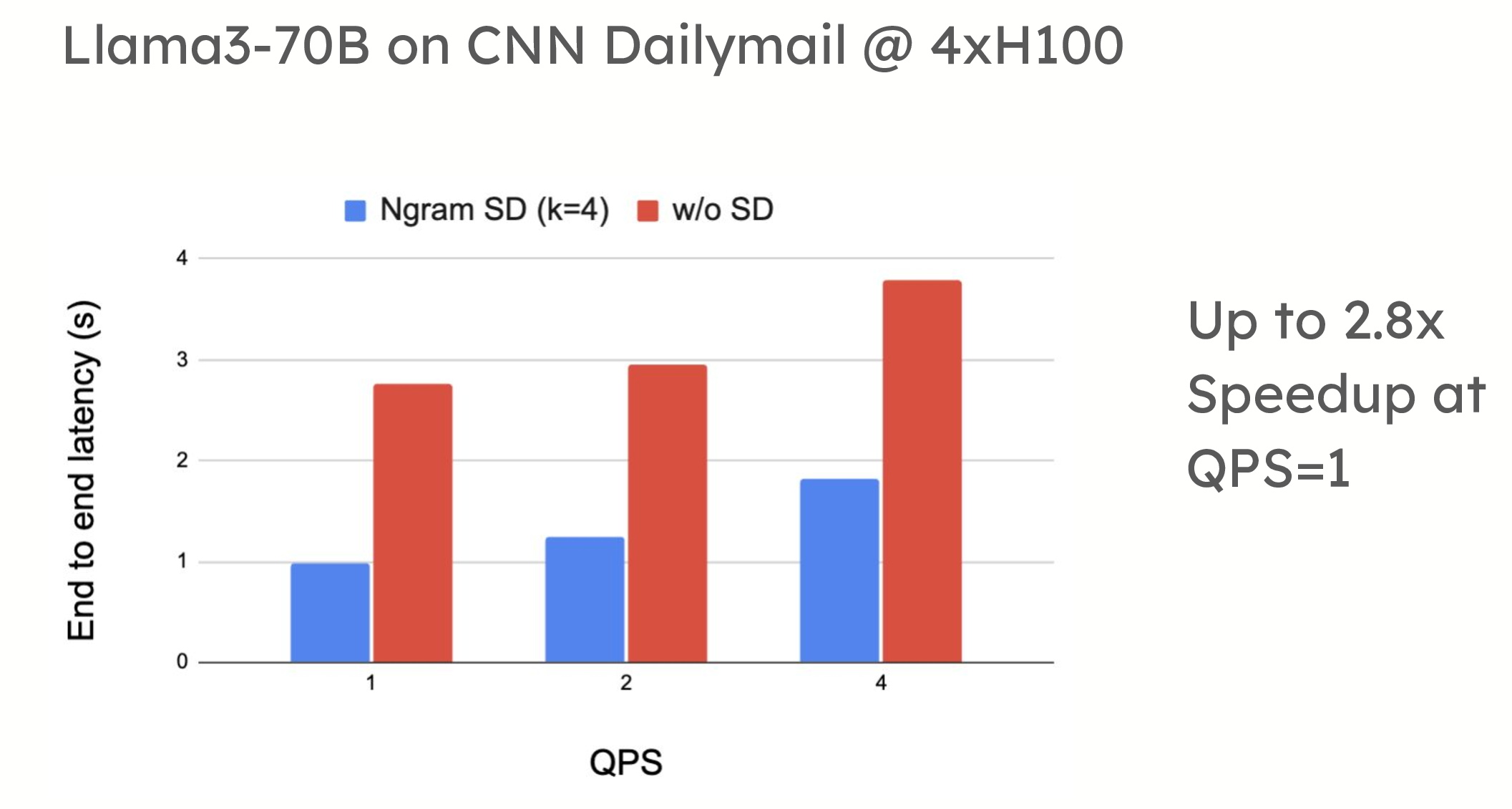
性能比较显示,在使用草稿模型 (turboderp/Qwama-0.5B-Instruct) 的 4xH100 上,QPS=1 时,Llama3-70B 在 ShareGPT 上使用投机解码可实现高达 1.5 倍的加速;在使用 n-gram 的 4xH100 上,QPS=1 时,Llama3-70B 在 CNN Dailymail 上使用投机解码可实现高达 2.8 倍的加速。
然而,在高 QPS 环境中,投机解码可能会引入性能权衡。当系统已经受到计算限制时,提议和验证令牌所需的额外计算有时会减慢系统速度,正如每秒请求数增加时所看到的那样。在这种情况下,投机解码的开销可能会超过其优势,从而导致性能下降。
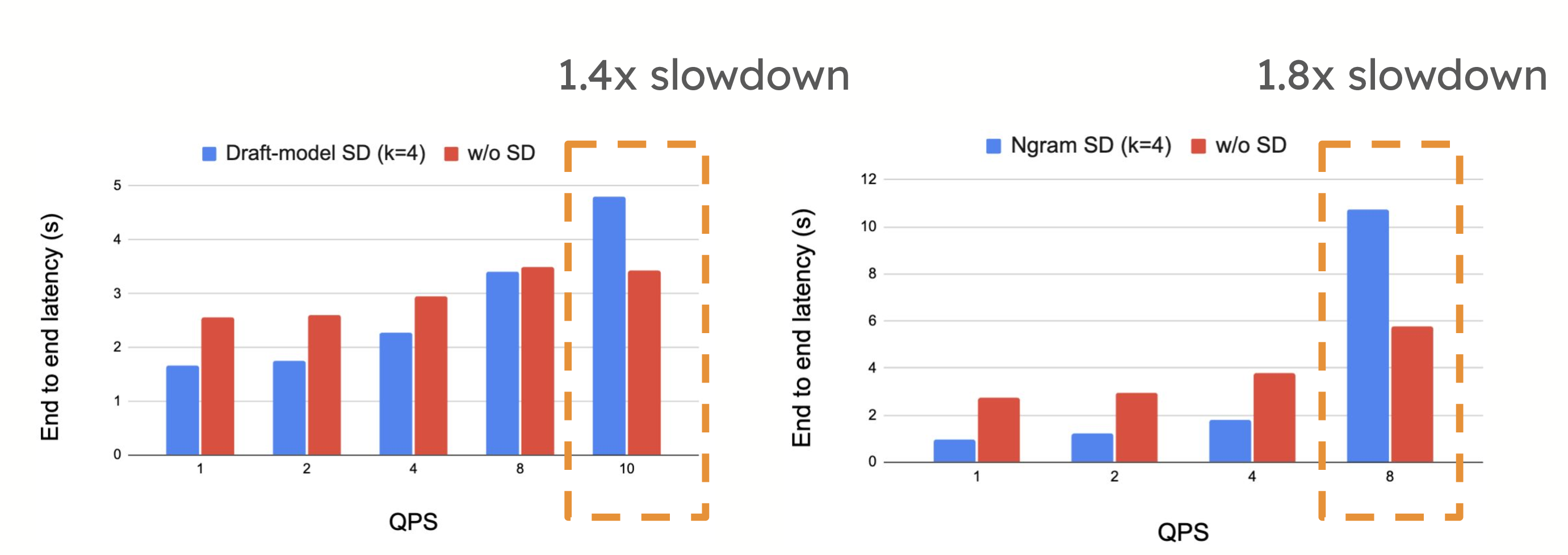
在高 QPS 下,我们看到 Llama3-70B 在 ShareGPT 上使用 4xH100 时速度减慢 1.4 倍,Llama3-70B 在 CNN Dailymail 上使用 4xH100 时速度减慢 1.8 倍
路线图:用于提升性能的动态调整
为了克服投机解码在高 QPS 设置中的局限性,vLLM 正在努力实现动态投机解码。请随时查看论文以获取更多详细信息。这也是 vllm 中活跃的研究方向之一!此功能将允许 vLLM 根据系统负载和草稿模型的准确性来调整投机令牌的数量。在较高层面,当系统负载较高时,动态投机解码会缩短提议的长度。然而,如下图所示,当平均令牌接受率较高时,这种减少不太明显。
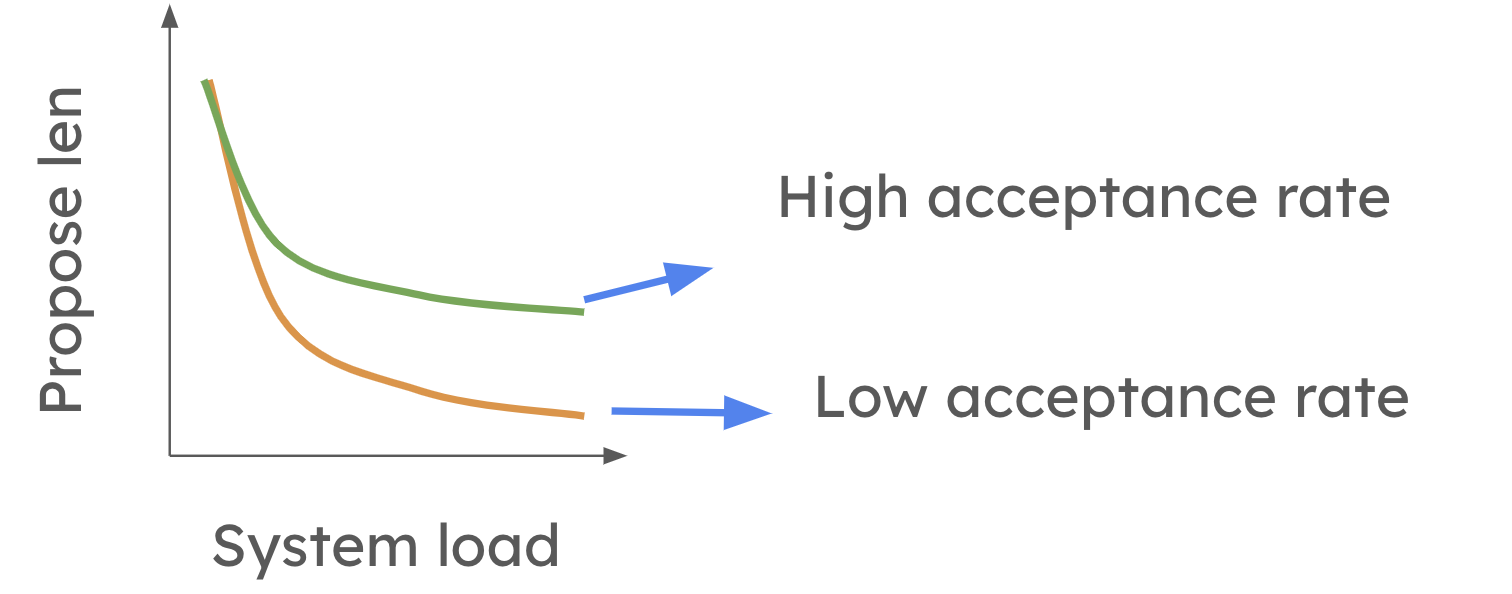
未来,系统将能够自动修改每一步的投机程度,确保投机解码始终是有益的,而无需考虑工作负载。这将允许用户激活投机解码,而无需担心它是否会减慢系统速度。
如何在 vLLM 中使用投机解码
在 vLLM 中设置投机解码非常简单。启动 vLLM 服务器时,您只需包含必要的标志来指定投机模型、令牌数量和张量并行大小。
以下代码配置 vLLM 在离线模式下使用带有草稿模型的投机解码,每次投机 5 个令牌
from vllm import LLM
llm = LLM(
model="facebook/opt-6.7b",
speculative_model="facebook/opt-125m",
num_speculative_tokens=5,
)
outputs = llm.generate("The future of AI is")
for output in outputs:
print(f"Prompt: {output.prompt!r}, Generated text: {output.outputs[0].text!r}")
以下代码配置 vLLM 使用投机解码,其中提议通过匹配提示中的 n-gram 生成
from vllm import LLM
llm = LLM(
model="facebook/opt-6.7b",
speculative_model="[ngram]",
num_speculative_tokens=5,
ngram_prompt_lookup_max=4,
ngram_prompt_lookup_min=1,
)
outputs = llm.generate("The future of AI is")
for output in outputs:
print(f"Prompt: {output.prompt!r}, Generated text: {output.outputs[0].text!r}")
有时,您可能希望草稿模型以与目标模型不同的张量并行大小运行,以提高效率。这允许草稿模型使用更少的资源并减少通信开销,将更多资源密集型计算留给目标模型。在 vLLM 中,您可以将草稿模型配置为使用张量并行大小 1,而目标模型使用大小 4,如下例所示。
from vllm import LLM
llm = LLM(
model="meta-llama/Meta-Llama-3.1-70B-Instruct",
tensor_parallel_size=4,
speculative_model="ibm-fms/llama3-70b-accelerator",
speculative_draft_tensor_parallel_size=1,
)
outputs = llm.generate("The future of AI is")
for output in outputs:
print(f"Prompt: {output.prompt!r}, Generated text: {output.outputs[0].text!r}")
未来的更新 (论文,RFC) 将允许 vLLM 自动选择投机令牌的数量,从而无需手动配置并进一步简化流程。
请关注我们的文档 vLLM 中的投机解码 以开始使用。加入我们的双周办公时间,提出问题并提供反馈。
结论:vLLM 中投机解码的未来
vLLM 中的投机解码提供了显著的性能提升,尤其是在低 QPS 环境中。随着动态调整的引入,即使在高 QPS 设置中,它也将成为一种高效的工具,使其成为降低延迟和提高 LLM 推理效率的多功能且必不可少的功能。