宣布 vLLM 支持 Llama 3.1
今天,vLLM 团队非常激动地与 Meta 合作宣布支持 Llama 3.1 模型系列。Llama 3.1 带来令人兴奋的新功能,包括更长的上下文长度(高达 128K tokens)、更大的模型尺寸(高达 405B 参数)以及更先进的模型能力。vLLM 社区添加了许多增强功能,以确保更长、更大的 Llama 模型在 vLLM 上平稳运行,其中包括分块预填充(chunked prefill)、FP8 量化和流水线并行。我们将在本博文中介绍这些新的增强功能。
简介
vLLM 是一个快速、易于使用、开源的大型语言模型服务引擎。vLLM 支持 40 多种开源 LLM、多种多样的硬件平台(Nvidia GPU、AMD GPU、AWS Inferentia、Google TPU、Intel CPU、GPU、Gaudi 等)以及各种推理优化技术。请点击此处了解更多关于 vLLM 的信息。
对于新的 Llama 3.1 系列,vLLM 可以使用完整的 128K 上下文窗口运行模型。为了支持更大的上下文窗口,vLLM 自动启用分块预填充。分块预填充不仅可以控制内存使用量,还可以减少长时间的 prompt 处理对正在进行的请求造成的干扰。您可以通过运行以下命令或使用我们的官方 docker 镜像 (vllm/vllm-openai) 来安装 vLLM。
pip install -U vllm
对于大型 Llama 405B 模型,vLLM 支持以下几种方法:
- FP8: vLLM 在 8xA100 或 8xH100 上原生运行官方 FP8 量化模型。
- 流水线并行: vLLM 通过将模型的不同层放置在不同的节点上,在多个节点上运行官方 BF16 版本。
- 张量并行: vLLM 也可以通过在多个节点以及节点内的多个 GPU 之间分片模型来运行。
- AMD MI300x 或 NVIDIA H200: vLLM 可以在单个 8xMI300x 或 8xH200 机器上运行该模型,其中每个 GPU 分别具有 192GB 和 141 GB 内存。
- CPU 卸载: 作为最后的手段,vLLM 可以在执行前向传播时将部分权重卸载到 CPU,从而允许您在有限的 GPU 内存上以全精度运行大型模型。
请注意,虽然 vLLM 支持所有这些方法,但性能仍处于初步阶段。vLLM 社区正在积极进行优化,我们欢迎大家的贡献。例如,我们正在积极探索更多量化模型的方法,以及提高流水线并行的吞吐量。稍后在博客中发布的性能数据仅作为早期的参考点;我们预计性能将在未来几周内得到显着提升。
在所有方法中,我们推荐单节点使用 FP8,多节点使用流水线并行。让我们更详细地讨论它们。
FP8
FP8 以 8 位表示浮点数。当前一代 GPU(H100、MI300x)通过专用张量核心为 FP8 提供原生支持。目前,vLLM 可以为 KV 缓存、注意力机制和 MLP 层运行 FP8 量化模型。这减少了内存占用、提高了吞吐量、降低了延迟,并且精度下降极小。
目前,vLLM 支持官方 Meta Llama 3.1 405B FP8 模型,该模型通过 FBGEMM 量化,并在 MLP 层中利用了逐通道量化。具体而言,up/gate/down 投影的每个通道都经过量化,并乘以静态缩放因子。结合跳过第一层和最后一层的量化以及静态上限,这种方法对模型精度的影响极小。您可以使用最新的 vLLM 在单个 8xH100 或 8xA100 上运行该模型,命令如下:
$ vllm serve meta-llama/Meta-Llama-3.1-405B-Instruct-FP8 --tensor-parallel-size 8
在使用平均输入长度为 1024 个 tokens 和平均输出长度为 128 个输出 tokens 的 FP8 量化模型服务请求时,服务器可以维持每秒 2.82 个请求。相应的服务吞吐量分别为每秒 2884.86 个输入 tokens 和每秒 291.53 个输出 tokens。
我们还独立证实了 FP8 检查点的精度下降极小。例如,使用 lm-eval-harness 和 8-shot 以及链式思考 (chain-of-thought) 运行 GSM8K 基准测试,我们观察到精确匹配得分 (exact match score) 为 95.38%(+- 0.56% 标准差),与 BF16 官方得分 96.8% 相比,下降幅度极小。
流水线并行
如果您想在不进行量化的情况下运行 Llama 3.1 405B 模型怎么办?您可以使用 vLLM 的流水线并行在 16xH100 或 16xA100 GPU 上实现!
流水线并行将模型分成更小的层集合,在两个或多个节点上以流水线方式并行执行它们。与需要昂贵的 all-reduce 操作的张量并行不同,流水线并行跨层边界划分模型,仅需要廉价的点对点通信。当您拥有多个节点,而这些节点不一定通过像 Infiniband 这样的快速互连技术连接时,这尤其有用。
vLLM 支持结合流水线并行和张量并行。例如,对于跨 2 个节点的 16 个 GPU,您可以使用 2 路流水线并行和 8 路张量并行来优化硬件使用率。此配置将模型的一半映射到每个节点,并使用 NVLink 将每层划分为 8 个 GPU 以进行 all-reduce 操作。您可以使用以下命令运行 Llama 3.1 405B 模型:
$ vllm serve meta-llama/Meta-Llama-3.1-405B-Instruct --tensor-parallel-size 8 --pipeline-parallel-size 2
如果您有像 Infiniband 这样的快速互连技术,则可以使用 16 路张量并行。
$ vllm serve meta-llama/Meta-Llama-3.1-405B-Instruct --tensor-parallel-size 16
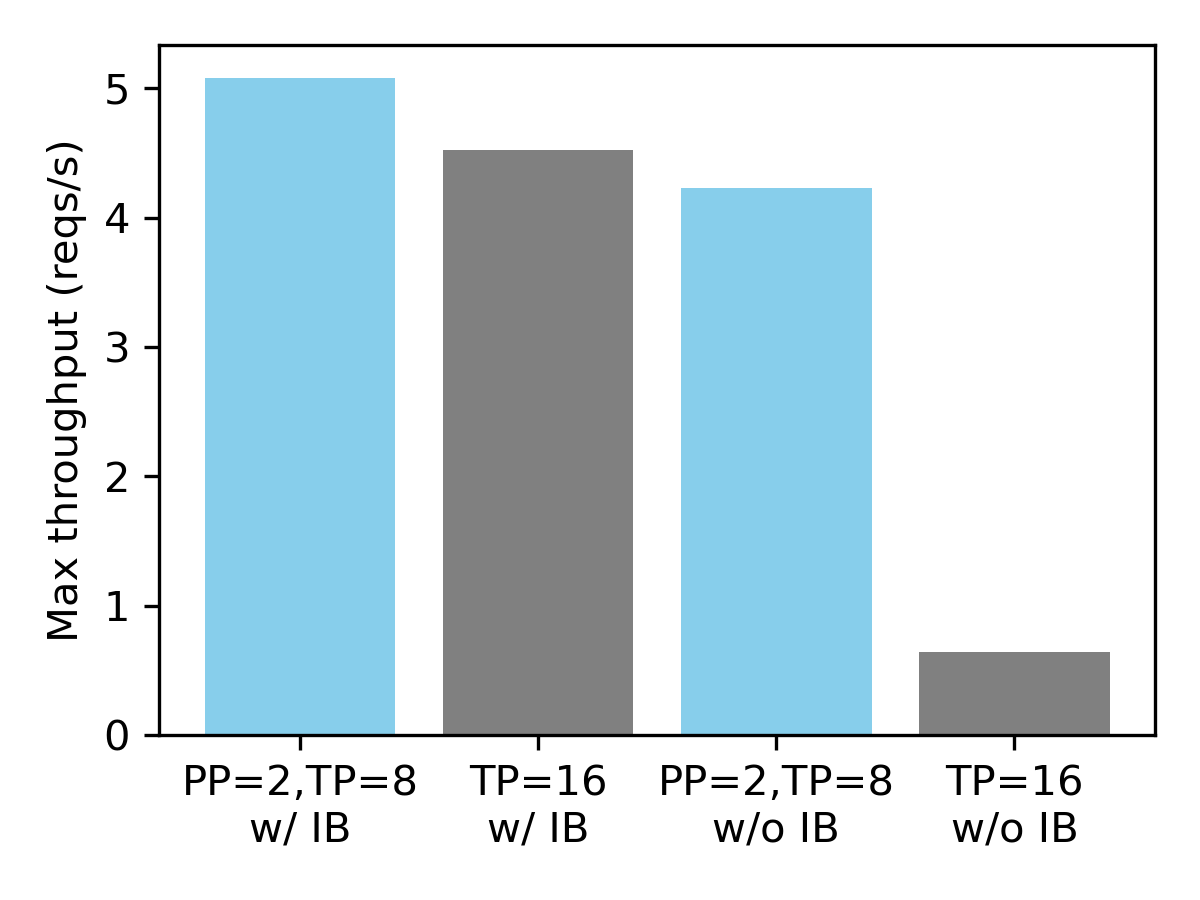
在具有合成数据集的 16xH100 GPU 上的服务吞吐量(平均输入长度 1024,平均输出长度 128)。
我们观察到,当节点未通过 Infiniband 连接时,流水线并行至关重要。与 16 路张量并行相比,将 2 路流水线并行与 8 路张量并行相结合可带来 6.6 倍的性能提升。另一方面,对于 Infiniband,两种配置的性能相似。
要了解更多关于使用 vLLM 进行分布式推理的信息,请参阅此文档。对于 CPU 卸载,请参阅此示例。
致谢
我们要感谢 Meta 提供的预发布合作伙伴关系,让我们能够测试该模型。除了发布之外,我们还要感谢以下 vLLM 贡献者为本博文中提到的功能做出的贡献:Neural Magic 贡献了 FP8 量化;CentML 和 Snowflake AI Research 贡献了流水线并行;Anyscale 贡献了分块预填充功能。评估运行在配备 InfiniBand 的 Lambda 的 1-Click Clusters 上,我们感谢 Lambda 提供的资源和顺畅的集群设置体验。