关于 vLLM 与 DeepSpeed-FastGen 的比较说明
概要
- 在常见场景中,vLLM 的速度与 DeepSpeed-FastGen 相匹敌,并在处理较长输出时超越后者。
- 由于其动态 SplitFuse 优化技术,DeepSpeed-FastGen 仅在长提示和短输出的场景中优于 vLLM。此优化技术已在 vLLM 的路线图上。
- vLLM 的使命是构建最快且最易于使用的开源 LLM 推理和服务引擎。它采用 Apache 2.0 许可证,由社区所有,并提供广泛的模型和优化支持。
DeepSpeed 团队最近发布了一篇博客文章,声称通过利用动态 SplitFuse 技术,吞吐量比 vLLM 提高了 2 倍。我们很高兴看到开源社区的技术进步。在这篇博客中,我们展示了动态 SplitFuse 技术具有优势的具体场景,并指出这些情况相对有限。对于大多数工作负载,vLLM 比 DeepSpeed-FastGen 更快(或性能相当)。
性能基准测试
我们已经确定了 vLLM 和 DeepSpeed-FastGen 在性能优化方面的两个主要区别。
- DeepSpeed-FastGen 采用保守/次优的内存分配方案,这会在输出长度较大时浪费内存。
- DeepSpeed-FastGen 的动态 SplitFuse 调度仅在提示长度远大于输出长度时才能提供加速。
因此,当工作负载始终为长提示和短输出时,DeepSpeed-FastGen 表现更佳。在其他场景中,vLLM 显示出卓越的性能。
我们在 NVIDIA A100-80GB GPU 上使用 LLaMA-7B 模型,在以下场景中对这两个系统进行了基准测试。
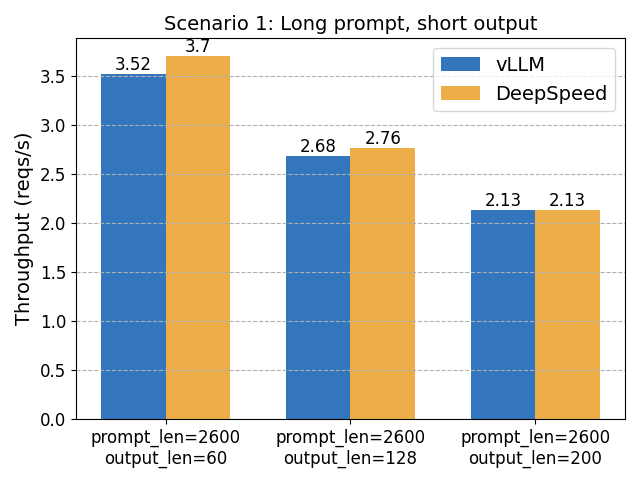
场景 1:长提示长度,短输出
在这里,DeepSpeed-FastGen 的动态 SplitFuse 调度有望发挥优势。然而,我们观察到的性能提升并没有 2 倍那么显著。
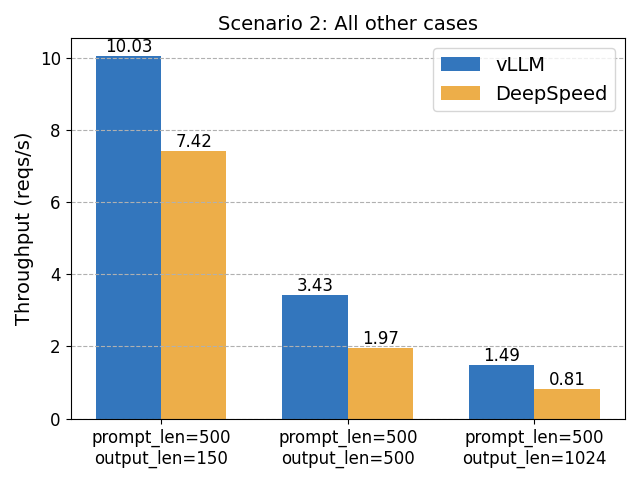
场景 2:其他情况
在这些情况下,vLLM 比 DeepSpeed-FastGen 快 1.8 倍。
vLLM 的未来:真正的社区项目
我们致力于将 vLLM 打造成最佳开源项目,融合社区的最佳模型、优化和硬件。vLLM 源于加州大学伯克利分校 Sky Computing Lab,我们正在以 Apache 2.0 许可证真正地以开源方式构建 vLLM。
vLLM 团队优先考虑合作,并努力保持代码库的高质量和易于贡献。我们正在积极致力于系统性能;以及 LoRA、推测解码和更好的量化支持等新功能。此外,我们正在与 AMD、AWS Inferentia 和 Intel Habana 等硬件供应商合作,将 LLM 带给最广泛的社区。
专门针对动态 SplitFuse 优化,我们正在积极研究适当的集成方案。如果您有任何问题和建议,请随时在 GitHub 上联系我们。我们还在此处发布了基准测试代码:here。
附录:功能比较
DeepSpeed-FastGen 目前提供基本功能,仅支持三种模型类型,并且缺乏诸如停止字符串和并行采样(例如,束搜索)等常用功能。我们确实期望 DeepSpeed-FastGen 渴望赶上,并且我们欢迎市场上的创新!
| vLLM | DeepSpeed-FastGen | |
|---|---|---|
| 运行时 | Python/PyTorch | Python/PyTorch |
| 模型实现 | HuggingFace Transformers | 自定义实现 + HF 模型转换器 |
| 服务器前端 | 用于演示目的的简单 FastAPI 服务器 | 基于 gRPC 的自定义服务器 |
| 调度 | 连续批处理 | 动态 SplitFuse |
| 注意力内核 | PagedAttention & FlashAttention | PagedAttention & FlashAttention |
| 自定义内核(用于 LLaMA) | 注意力, RoPE, RMS, SILU | 注意力, RoPE, RMS, SILU, 嵌入 |
| KV 缓存分配 | 近乎最优 | 次优/保守 |
| 支持的模型 | 16 种不同的架构 | LLaMA, Mistral, OPT |
| 采样方法 | 随机, 并行, 集束搜索 | 随机 |
| 停止标准 | 停止字符串, 停止 tokens, EOS | EOS |